一、目标网站介绍
网易云音乐是一款由网易开发的音乐产品,是网易杭州研究院的成果,依托专业音乐人、DJ、好友推荐及社交功能,在线音乐服务主打歌单、社交、大牌推荐和音乐指纹,以歌单、DJ节目、社交、地理位置为核心要素,主打发现和分享。
2017年11月17日,网易云用户突破4亿。知乎上有这样一个问题:你为什么用网易云其中,有一条是这样说的:
成年人的生活里有太多无奈。
我之前把情绪和秘密写在QQ留言板里,被朋友们发现。
后来写在人人网上,被朋友们发现。
后来写在微博里,被朋友们发现。
后来写在知乎里,被朋友们发现。
后来淹没在网易云强大的评论区里。
我需要一个地方,一个可以光明正大写出来的地方。
不用担心被任何人看到,不需要任何解释。
网易云可以把所有的悲伤,变成段子。
出于大众对网易云音乐的喜爱,这次文本挖掘我放在了这里,希望能发现些有趣的东西。
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
二、所需工具
-
Anaconda 3.5.0
-
Pycharm
-
Node.js
-
Mongodb
-
Studio 3T
-
RStudio
三、数据爬取
3.1 环境搭建
本文基于Scrapy框架爬取数据。使用pip install 来安装scrapy需要安装大量的依赖库:
-
Wheel
pip install wheel
-
lxml
pip install D:\Downloads\Scrapy\lxml-4.3.0-cp36-cp36m-win_amd64.whl
-
PyOpenssl]
pip install D:\Downloads\Scrapy\pyOpenSSL-18.0.0-py2.py3-none-any.whl
-
Twisted
pip install D:\Downloads\Scrapy\Twisted-18.9.0-cp36-cp36m-win_amd64.whl
-
Pywin32
可执行文件,挑选与Python对应版本安装就好。 -
Scrapy
pip install scrapy
这里我使用了Anaconda来安装scrapy,安装时只需要一条语句:
conda install scrapy
3.2 网站分析
网易云音乐首页:
爬取思路有两种:
1.基于网页原代码,利用正则表达式、XPath等获取数据;
2.基于每次请求的API,直接获取所需数据;
本文采用第二种,针对电视剧《旋风少女》插曲的评论做简单说明:

查看NetWork,发起请求,我们可以看到,数据保存在这里:
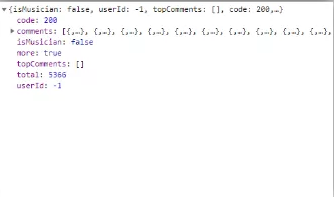
请求地址为:
https://music.163.com/weapi/v1/resource/comments/R_SO_4_28936510?csrf_token=但是Request HEaders里的Cookie值、FromData里的params、encSecKey都是加密过的。开始解密:
http://music.163.com/api/v1/resource/comments/R_SO_4_28936510
很好,但是很不巧的是网易云设置了反爬虫,根本不了手,爬虫时会出现以下错误:
1.{"code":-460,"msg":"Cheating"}
这是网上存在的解决办法:
更换动态IP的:
-
我跟网易云音乐爬虫不得不说的故事
复制请求头的:
-
Python爬网易云音乐的那些事
说明:上面两种方法在现在是行不通的,网易云加强了反爬虫机制,对请求头中的Cookie值进行了加密,所以有了下面这些对请求头中的Cookie值进行解密的:
-
如何爬网易云音乐的评论数?
-
用Python代码来下载任意指定网易云歌曲(超详细版)
但是,这种解密方法繁琐复杂,本文采用@Binaryify团队开发的[NeteaseCloudMusicApi]获取请求,这是一个相当便利、好用的API,感谢Binaryify。
3.3 功能特性
此次爬虫,下面的所有功能,都可以实现:
获取用户信息 , 歌单,收藏,mv, dj 数量
获取用户歌单
获取用户电台
获取用户关注列表
获取用户粉丝列表
获取用户动态
获取用户播放记录
获取精品歌单
获取歌单详情
搜索
搜索建议
获取歌词
歌曲评论
收藏单曲到歌单
专辑评论
歌单评论
mv 评论
电台节目评论
banner
获取歌曲详情
获取专辑内容
获取歌手单曲
获取歌手 mv
获取歌手专辑
获取歌手描述
获取相似歌手
获取相似歌单
相似 mv
获取相似音乐
获取最近 5 个听了这首歌的用户
获取每日推荐歌单
获取每日推荐歌曲
私人 FM
喜欢音乐
歌单 ( 网友精选碟 )
新碟上架
热门歌手
最新 mv
推荐 mv
推荐歌单
推荐新音乐
推荐电台
推荐节目
独家放送
mv 排行
获取 mv 数据
播放 mv/视频
排行榜
歌手榜
云盘
电台 - 推荐
电台 - 分类
电台 - 分类推荐
电台 - 订阅
电台 - 详情
电台 - 节目
获取动态
获取热搜
发送私信
发送私信歌单
新建歌单
收藏/取消收藏歌单
歌单分类
收藏的歌手列表
订阅的电台列表
相关歌单推荐
付费精选接口
音乐是否可用检查接口
获取视频数据
发送/删除评论
热门评论
视频评论
所有榜单
所有榜单内容摘要
收藏视频
收藏 MV
视频详情
相关视频
关注用户
新歌速递
喜欢音乐列表(无序)
收藏的 MV 列表
本文以其中几个为例,进行数据爬取和文本挖掘:
3.4 歌单
我们找到歌单页面为下:

可以看到:
语种有:华语、欧美、日语、韩语、小语种;
风格有:流行、摇滚、民谣、电子、舞曲、说唱、轻音乐、说唱、爵士、乡村、古典、民族、英伦、金属、朋克、蓝调、雷鬼、世界音乐、拉丁、古风等;还有对歌单的场景、情感、主题分类。
我们不对其进行帅选,爬取所有种类的歌单。当每页为35个歌单的时候,一共有38页;当每页为20个歌单的时候,一共有66页,我们把66页一共1306个的歌单信息爬取下来:
1.class MenuSpider(scrapy.Spider):
2. name = 'menu'
3. allowed_domains = ['localhost:3000']
4. start_urls = ['http://localhost:3000/']
5. allplaylist_url = 'http://localhost:3000/top/playlist?order=hot&cat=%E5%85%A8%E9%83%A8&limit=20&offset={offset}'
6.
7. def start_requests(self):
8. for i in range(0, 66):
9. yield Request(self.allplaylist_url.format(offset=i * 20), callback=self.parse_allplaylist)
10.
11. def parse_allplaylist(self, response):
12. result = json.loads(response.text)
13. item = MusicmenuItem()
14. for field in item.fields:
15. if field in result.keys():
16. item[field] = result.get(field)
17. yield item
3.5 歌曲
这是一个歌单下面的几十首歌曲,每首歌都有歌曲名称、歌手、时长、所属专辑、发行时间、评论等。像这个歌单《一个人在外漂泊,记得按时听歌呀》一共有40首歌。
接下来,连接数据库,提取上面所爬歌单的id,根据id值获得每个歌单下面的歌曲id,再根据歌曲id值获得每首歌下面的评论信息。执行翻页操作,从而最终获取1306个歌单下面的前30首歌曲的前10页评论:
1.# -*- coding: utf-8 -*-
2.import time
3.import scrapy
4.from scrapy import Spider,Request
5.import io
6.import sys
7.import json
8.import pandas as pd
9.import pymongo
10.from wangyiyun.items import WangyiyunCommentItem
11.from wangyiyun.items import WangyiyunPlaylistItem
12.from wangyiyun.items import WangyiyunAllPlaylistItem
13.
14.sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
15.
16.class MusiccommentsSpider(scrapy.Spider):
17. name = 'musiccomments'
18. allowed_domains = ['localhost:3000']
19. start_urls = ['http://localhost:3000/comment/music?id=296883/']
20. allplaylist_url = 'http://localhost:3000/top/playlist?order=hot&cat=%E5%85%A8%E9%83%A8&limit=20&offset={offset}'
21. playlist_url = 'http://localhost:3000/playlist/detail?id={id}'
22. comment_url = 'http://localhost:3000/comment/music?id={id}&offset={offset}&limit=20'
23. num_comment = 0
24. num_page = 0
25. song_id = 0
26. results = ''
27.
28.
29. def start_requests(self):
30. client = pymongo.MongoClient(host='localhost', port=27017)
31. db = client['music']
32. collection = db['menu']
33. # 将数据库数据转为dataFrame
34. menu = pd.DataFrame(list(collection.find()))
35. num = menu['playlists']
36. result = pd.DataFrame(num.iloc[0])
37. for i in range(1, 66):
38. data2 = pd.DataFrame(num.iloc[i])
39. result = pd.concat([result, data2], ignore_index=True)
40. print(result.shape)
41. id = result['id']
42. for i in range(0, 1000):
43. yield Request(self.playlist_url.format(id=id.iloc[i]), callback=self.parse_playlist)
44.
45. def parse_playlist(self, response):
46. result = json.loads(response.text)
47. item = WangyiyunPlaylistItem()
48. for field in item.fields:
49. if field in result.keys():
50. item[field] = result.get(field)
51. yield item
52.
53. for j in range(0, 30):
54. for k in range(0,10):
55. yield Request(
56. self.comment_url.format(id=result.get('playlist').get('tracks')[j].get('id'), offset=k * 20),
57. callback=self.parse_comment, dont_filter=True)
58.
59. def parse_comment(self, response):
60. result = json.loads(response.text)
61. item = WangyiyunCommentItem()
62. #print(response.text.encode('utf-8','ignore'))
63. for field in item.fields:
64. if field in result.keys():
65. item[field] = result.get(field)
66. yield item
获取了13943个文档。由于爬取时歌曲信息和评论信息保存到了一张表里,去掉其中的歌曲信息,评论信息约有12000*20=24万条。