前言
最近几天接触了一下Flask,在惊叹于其简洁性的同时,更是被其先进的设计理念折服。但是一直以来对于它的ORM不是很理解,借此机会,做下实践,让自己对此加深一下印象。
权当是留给自己的一个纪念吧。
ORM拓展
Flask中可以使用的拓展有很多。或者可以这么说, 在flask中,你可以使用ORM,也可以不使用ORM。一切都在您的掌控中。
而在众多的ORM框架汇中,SQLAlchemy算是老大哥了。特别地,Flask中有专门针对于SQLAlchemy的拓展,使得包装后的SQLAlchemy更加易用。
安装
安装步骤非常简单,前提是安装了pip的话。
pip install flask-sqlalchemy数据库设置
在Flask中,既可以使用关系型数据库,还可以使用非关系型数据库。一切都可以由你自己控制。这里先拿关系型数据库入手吧。
对于关系型数据库,常见的有这么几个,sqlite3, MySQL, PostgreSQL, Oracle, MSSQL
SQLAlchemy连接数据库的时候需要一个特殊的URI(统一资源定位符)来创建数据库的连接。这个URI的是一个有特殊格式的字符串,包含了SQLAlchemy连接数据库所需要的所有信息。
databasetype+driver://user:password@ip:port/db_name从上面也可以看出,需要driver 的支持。当然了,这个driver是需要你自己手动安装好的。对于这几个数据库而言,常见的URI如下:
- SQLite:
sqlite:///database.db- MySQL:
mysql+pymysql://user:password@ip:port/db_name- PostgreSQL:
postgresql+psycopg2://user:password@ip:port/db_name- MSSQL:
mssql+pyodbc://user:password@ip:port/db_name- Oracle:
oracle+cx_oracle://user:password@ip:port/db_name由于Flask可以通过一个类对象来加载相关的配置。所以我们可以轻松的把这些配置信息,写到一个类中,这样对于代码的管理和维护都会十分的有帮助。
比如我们可以这么写:
class Config(object):
DEBUG = True
SQLALCHEMY_DATABASE_URI = "path.db"
# 然后可以通过下面的这行代码进行加载
app.config.from_object(Config)
使用
在Flask中,要想使用某一个拓展,仅仅需要把flask对象当做构造参数传递给拓展类即可。
比如拓展一个管理类:
from flask.ext.script import Manager
from flask import Flask
app = Flask(__name__)
manager = Manager(app)
# 然后就可以使用manager对象开始对flask应用进行管理了再者,拓展一个数据库:
from flask import Flask
from flask.ext.sqlalchemy import SQLAlchemy
class Config(object):
SQLALCHEMY_DATABASE_URI = "sqlite:///test.db"
app = Flask(__name__)
# 需要加载一下数据库的URI等配置信息
app.config.from_object(Config)
# 开启对数据库的拓展
db = SQLAlchemy(app)开启一个就是这么简单, 而且flask官网上有太多太多已经很完善的拓展了,可以轻松的拿来使用。
关系
在关系型数据库中,最最常见的应该就是什么一对多,多对多了。对于单表操作,多表操作。使用ORM其实还是有点晦涩的。
毕竟相对于原生的SQL语句而言,需要掌握一些额外的语法。但是熟悉了这个套路之后,就不会很烦躁了。反而会通过流处理获取到一丝畅快。
单表操作
在开始具体的操作之前,还是得先有表结构才行。与原生的SQL相比,建表啊什么的不需要我们手动执行了。通过ORM框架可以自动生成相关的表结构。(相关的前提还是得先定义好类的模式,不知道这算不算自动了,估计不能吧,(⊙﹏⊙)b)
“建表”
下面先来创建一个单表model.py。
# coding: utf8
from flask.ext.sqlalchemy import SQLAlchemy
from flask import Flask
####################
# 数据库路径等相关配置选项
####################
class Config(object):
SQLALCHEMY_DATABASE_URI = "sqlite:///test.db"
app = Flask(__name__)
app.config.from_object(Config)
# 拓展数据库相关内容
db = SQLAlchemy(app)
####################
# 开始制作模型
####################
class User(db.Model):
id = db.Column(db.Integer(), primary_key=True)
username = db.Column(db.String(255))
password = db.Column(db.String(255))
def __init__(self, username, password):
self.username = username
self.password = password
def __repr__(self):
return "<[User] username:`{}`, password:`{}`".format(self.username, self.password)
然后是一个管家,来操作这个模型。main.py
# coding: utf8
from model import app, db, User
from flask.ext.script import Manager, Server
# 通过拓展来管理flask应用
manager = Manager(app)
# 添加自定义命令,通过python main.py server就可以开启
manager.add_command('server', Server)
# 创建在命令行里面的上下文环境
@manager.shell
def make_shell_context():
return dict(app=app, db=db, User=User)
if __name__ == '__main__':
manager.run()执行下面的命令,我们就可以在命令行里面操作这张表了。
python main.py shell如果出现下面的情况,那么恭喜你,可以开始我们下一步的操作了。

应用表结构
对于刚才的模型来说,我们确实是创建好了,但也只是创建好了。还没应用到数据库中。可以查看一下项目目录,是否有test.db出现。
要想让其表现在数据库中,还需要下面的一条语句。
>>> db.create_all()
>>>然后我们会发现,项目目录下多出了一个文件。
然后可以使用软件来查看一下里面的表结构是否为我们预先设计好的。
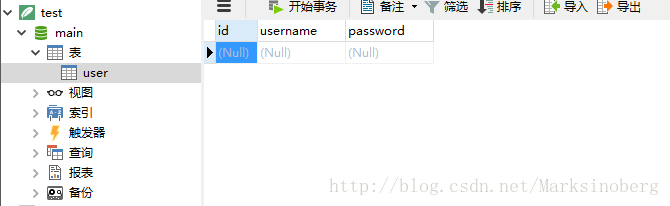
确实是我们预先设计的。这说明到目前为止,操作还是很顺利的。
CRUD
添加,查找操作
>>> user = User(username='m', password='password')
>>> db.session.add(user)
>>> db.session.commit()
>>>查看添加
>>> User.query.all()
[<[User] username:`m`, password:`password`]
>>>下面多添加几条数据
>>> for index in range(28):
... tempuser = User(username='user{}'.format(index), password='{}'.format(index))
... db.session.add(tempuser)
...
>>> db.session.commit()
>>>查看添加
>>> User.query.all()[25:]
[<[User] username:`user24`, password:`24`, <[User] username:`user25`, password:`25`, <[User] username:`user26`, password:`26`, <[User] username:`user27`, password:`27`]
>>>排序操作可以使用order_by实现。
>>> User.query.order_by(User.username).limit(3).all()
[<[User] username:`flask-admin`, password:`mypassword`, <[User] username:`user0`, password:`0`, <[User] username:`user1`, password:`1`]
>>>如果想指定某一列的反向排序,则可以这么做。
>>> User.query.order_by(User.username.desc()).limit(3).all()
[<[User] username:`郭璞`, password:``, <[User] username:`user9`, password:`9`, <[User] username:`user8`, password:`8`]
>>>注意是按照字母顺序排列的。
过滤器的使用,过滤器有下面两种方式,区别如下:
- filter_by: 需要指定某一个值,类似于SQL语句中的where操作。
- filter: 可以模糊化和关系化,> < in not or等等
下面分别举个例子。
通过filter_by来查找user的用户名为m的用户的信息。
>>> User.query.filter_by(username='m').all()
[<[User] username:`m`, password:`password`]
>>>通过filter_by来查找密码为18的用户的信息。
>>> User.query.filter_by(password='18').all()
[<[User] username:`user18`, password:`18`]
>>>需要注意的是在filter_by方式中,关键字不需要指定是哪个类的哪个属性,只需要制定属性及其目标值就可以了。
而通过filter可以实现更加灵活的处理。比如查找用户名为某一个列表中的的用户的信息。
>>> User.query.filter(User.username.in_(constraints)).limit(3).all()
[<[User] username:`user0`, password:`0`, <[User] username:`user3`, password:`3`, <[User] username:`user6`, password:`6`]
>>>再比如用户名不在某一个列表中的用户的信息
>>> User.query.filter(User.username.notin_(constraints)).limit(3).all()
[<[User] username:`m`, password:`password`, <[User] username:`user1`, password:`1`, <[User] username:`user2`, password:`2`]
>>>需要注意的是,filter中指定查询条件的时候需要指定类名的前缀。如上所示。
对于not_, or_等关系操作,这里还有更加高级的用法。不过需要拓展的支持,使用前需要引入相关的函数
from sqlalchemy.sql.expression import not_, or_下面添加一个密码为空的用户,然后进行查找。
>>> User.query.filter(not_(User.password!='')).all()
[<[User] username:`郭璞`, password:``]
>>>与之类似,or_ 操作可以联结这些过滤条件。
>>> User.query.filter(or_(not_(User.password!=''), User.username=='郭璞', User.username=='user7')).all()
[<[User] username:`user7`, password:`7`, <[User] username:`郭璞`, password:``]
>>>差不多常用的查询语句,这里都涉及到了。对查询部分来说,多写几遍代码就会很熟悉了。简单查询没什么难度。
更新操作
更新需要以dict的形式传递到参数中。比如我们想修改刚才添加的第一条数据的密码。
修改之前
>>> User.query.first()
<[User] username:`m`, password:`password`
>>>修改内容后记得提交修改
>>> User.query.filter_by(username='m').update({'username': 'flask-admin', 'password': 'mypassword'})
0
>>> db.session.commit()
>>> User.query.first()
<[User] username:`flask-admin`, password:`mypassword`
>>>如此这般,就可以修改特定目标了。还是很方便的。
删除操作
一般来说,增删改查这些操作都是类似的。需要注意的是不管做了什么操作,都要记得提交,这样才能把变化反馈到数据库中。
下面删除咱们刚才添加的最后那个密码为空的用户吧。
>>> del tmpuser
>>> User.query.filter_by(password='').first()
<[User] username:`郭璞`, password:``
>>> tmpuser = User.query.filter_by(password='').first()
>>> db.session.delete(tmpuser)
>>> db.session.commit()
>>> User.query.filter_by(password='').all()
[]
>>>分页相关,分页操作在web框架中会经常用到,从数据库直接返回分页数据,比返回所有数据然后自己处理方便多了。
>>> User.query.paginate(1, 7)
<flask_sqlalchemy.Pagination object at 0x00000194CC505588>
>>> page = User.query.paginate(1, 7)
>>> page.page
1
>>> page.pages
5
>>> page.has_prev
False
>>> page.has_next
True
>>> prepage = page.prev()
>>> prepage
<flask_sqlalchemy.Pagination object at 0x00000194CC505710>
>>> page.items
[<[User] username:`flask-admin`, password:`mypassword`, <[User] username:`user0`, password:`0`, <[User] username:`user1`, password:`1`, <[User] username:`user2`, password:`2`, <[User] username:`user3`, password:`3`, <[User] username:`user4`, password:`4`, <[User] username:`user5`, password:`5`]
>>> page.page
1
>>> nextpage = page.next()
>>> nextpage.page
2
>>> len(nextpage.items)
7
>>>到此为止,单表操作基本上就算完成的差不多了。东西比较多,而且比较琐碎。但是这是今后数据库ORM操作的基础,还是需要多多练习。
一对多
一对多操作,比如一个用户可以发表多篇博客。所以我们可以设计下面的这个模型model.py
# coding: utf8
from flask.ext.sqlalchemy import SQLAlchemy
from flask import Flask
import datetime
####################
# 数据库路径等相关配置选项
####################
class Config(object):
SQLALCHEMY_DATABASE_URI = "sqlite:///test.db"
app = Flask(__name__)
app.config.from_object(Config)
# 拓展数据库相关内容
db = SQLAlchemy(app)
####################
# 开始制作模型
####################
class User(db.Model):
id = db.Column(db.Integer(), primary_key=True)
username = db.Column(db.String(255))
password = db.Column(db.String(255))
# 一对多反馈
posts = db.relationship("Post", backref='user', lazy='dynamic')
def __init__(self, username, password):
self.username = username
self.password = password
def __repr__(self):
return "<[User] username:`{}`, password:`{}`".format(self.username, self.password)
class Post(db.Model):
id = db.Column(db.Integer(), primary_key=True)
title = db.Column(db.String(255))
text = db.Column(db.Text())
publish_time = db.Column(db.DateTime())
user_id = db.Column(db.Integer(), db.ForeignKey('user.id'))
def __init__(self, title):
self.title = title
self.publish_time = datetime.datetime.now()
def __repr__(self):
return "<[Post] title:`{}`>".format(self.title)
相应的,main.py也需要稍作修改。
# coding: utf8
from model import app, db, User, Post
from flask.ext.script import Manager, Server
# 通过拓展来管理flask应用
manager = Manager(app)
# 添加自定义命令,通过python main.py server就可以开启
manager.add_command('server', Server)
# 创建在命令行里面的上下文环境
@manager.shell
def make_shell_context():
return dict(app=app, db=db, User=User, Post=Post)
if __name__ == '__main__':
manager.run()然后就可以执行
Python main.py shell记得把设计好的模型反馈到数据库中。
>>> db.create_all()
>>> post1 = Post(title='firstpost')
>>> post2 = Post(title='secondpost')
>>> post3 = Post(title='thirdpost')
>>> db.session.add(post1)
>>> db.session.add(post2)
>>> db.session.add(post3)
>>> db.session.commit()
>>> Post.query.all()
[<[Post] title:`firstpost`>, <[Post] title:`secondpost`>, <[Post] title:`thirdpost`>]
>>>下面开始为用户指定发表的文章,实际中不该是这么处理的,这里只是做下模拟。指定的方式有两种,一个是通过backref,另一个是直接操作列表。
>>> user = User.query.first()
>>> user
<[User] username:`flask-admin`, password:`mypassword`
>>> Post.user = user
>>> db.session.commit()
>>> user.posts.all()
[]
>>> post1.user = user
>>> db.session.commit()
>>> user.posts.all()
[]
>>> Post.query.first()
<[Post] title:`firstpost`>
>>> Post.query.first().user_id
>>> post1.user
<[User] username:`flask-admin`, password:`mypassword`
>>> user
<[User] username:`flask-admin`, password:`mypassword`由于User类的posts是一个列表形式的属性,所以可以直接操作这个列表来为用户添加新文章。
>>> user.posts.append(post1)
>>> user.posts.append(post2)
>>> user.posts
<sqlalchemy.orm.dynamic.AppenderBaseQuery object at 0x000001D9252B19E8>
>>> user.posts.all()
[<[Post] title:`firstpost`>, <[Post] title:`secondpost`>]
>>> db.session.commit()
>>>查看数据库中的信息,不难发现。外键已经自动添加完毕。
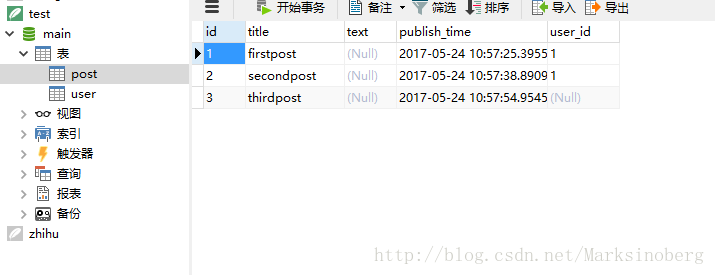
>>> post3
<[Post] title:`thirdpost`>
>>> post3.user_id = User.query.filter_by(username='user3').first().id
>>> user3.posts.all()
[<[Post] title:`thirdpost`>]
>>> db.session.commit()
>>>再次核实数据库。
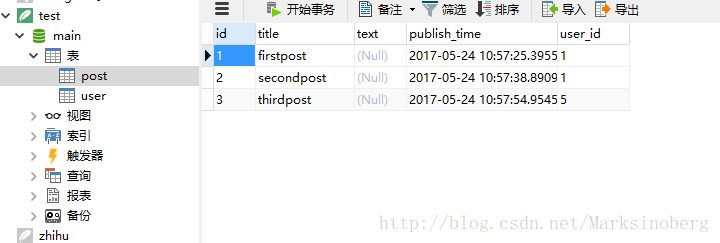
需要注意的是
backref参数可以让我们通过Post.user**属性**来对User的对象进行读取和修改,这一点会很方便。
lazy参数指的是如何去加载我们指定的关联对象 。subquery立即处理,速度慢; dynamic指在需要数据的时刻加载,对于数据量大的情形,采用dynamic效果会比较好。
多对多
了解了一对多的关系如何使用,下面对于多对多关系的操作应该也不会很难了。类比于原生SQL对此的处理即可。
下面模拟一个博客系统,包括用户,用户发表的文章, 文章的标签,文章的评论内容。我们不难发现这样的关系:
一个用户可以发表多篇文章, 一篇文章只属于一个用户(“伪规定”)一对多
一篇文章可以有多个评论,一个评论只属于一篇文章。一对多
一篇文章可以有多个标签,一个标签可以被多个文章共享。多对多
因此,模型可以被这么设计, model.py
# coding: utf8
from flask.ext.sqlalchemy import SQLAlchemy
from flask import Flask
import datetime
####################
# 数据库路径等相关配置选项
####################
class Config(object):
SQLALCHEMY_DATABASE_URI = "sqlite:///test.db"
app = Flask(__name__)
app.config.from_object(Config)
# 拓展数据库相关内容
db = SQLAlchemy(app)
####################
# 开始制作模型
####################
class User(db.Model):
id = db.Column(db.Integer(), primary_key=True)
username = db.Column(db.String(255))
password = db.Column(db.String(255))
# 一对多反馈
posts = db.relationship("Post", backref='user', lazy='dynamic')
def __init__(self, username, password):
self.username = username
self.password = password
def __repr__(self):
return "<[User] username:`{}`, password:`{}`".format(self.username, self.password)
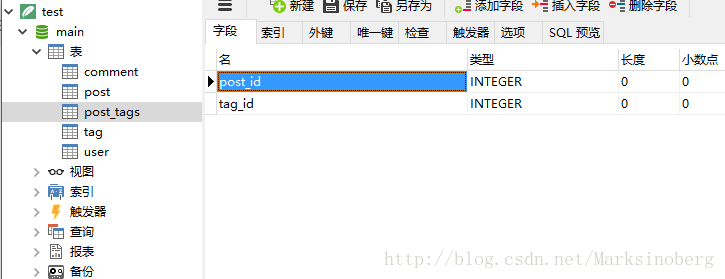
tags = db.Table('post_tags',
db.Column('post_id', db.Integer(), db.ForeignKey('post.id')),
db.Column('tag_id', db.Integer(), db.ForeignKey('tag.id')))
class Post(db.Model):
id = db.Column(db.Integer(), primary_key=True)
title = db.Column(db.String(255))
text = db.Column(db.Text())
publish_time = db.Column(db.DateTime())
user_id = db.Column(db.Integer(), db.ForeignKey('user.id'))
comments = db.relationship("Comment", backref='post', lazy='dynamic')
tags = db.relationship('Tag',
secondary=tags,
backref=db.backref('posts', lazy='dynamic'))
def __init__(self, title):
self.title = title
self.publish_time = datetime.datetime.now()
def __repr__(self):
return "<[Post] title:`{}`>".format(self.title)
class Comment(db.Model):
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255))
text = db.Column(db.Text())
date = db.Column(db.DateTime())
post_id = db.Column(db.Integer(), db.ForeignKey('post.id'))
def __init__(self, name):
self.name = name
self.date = datetime.datetime.now()
def __repr__(self):
return "<[Comment] name:`{}`>".format(self.name)
class Tag(db.Model):
id = db.Column(db.Integer(), primary_key=True)
title = db.Column(db.String(255))
def __init__(self, title):
self.title = title
def __repr__(self):
return "<[Tag] title:`{}`>".format(self.title)
相应的,main.py也需要做简单的修改。
# coding: utf8
from model import app, db, User, Post, Tag, Comment
from flask.ext.script import Manager, Server
# 通过拓展来管理flask应用
manager = Manager(app)
# 添加自定义命令,通过python main.py server就可以开启
manager.add_command('server', Server)
# 创建在命令行里面的上下文环境
@manager.shell
def make_shell_context():
return dict(app=app, db=db, User=User,
Post=Post, Comment=Comment, Tag=Tag)
if __name__ == '__main__':
manager.run()然后就可以执行
python main.py shell进入到命令行后,执行
db.create_all()我们所做的模型设计就会被反馈到数据库中。
接下来为博客系统添加一些初始化运作素材,写几个文章,发几条评论什么的。为了方便,就在数据库客户端上直接写了。
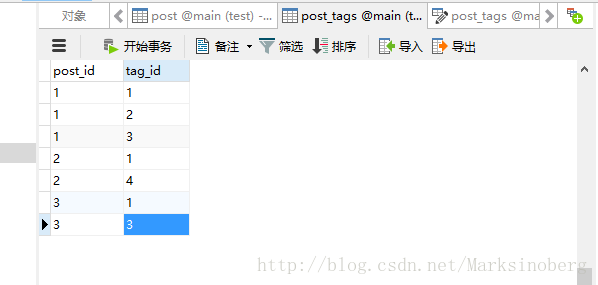
在命令行里查询一下
>>> Tag.query.all()
[<[Tag] title:`Python`>, <[Tag] title:`Flask`>, <[Tag] title:`SQLAlchemy`>, <[Tag] title:`随笔`>]
>>>发现没什么错误,接下来就可以查找了。比如查找某个特定名称用户的第一篇文章下的所有的评论。
>>> User.query.filter_by(username='flask-admin').first().posts[0].tags
[<[Tag] title:`Python`>, <[Tag] title:`Flask`>, <[Tag] title:`SQLAlchemy`>]
>>>接下来用原生的SQL语句实现同样的效果。
SELECT
tag.title
FROM
tag,
post,
post_tags
WHERE
post.user_id = (
SELECT
user.id
FROM
user
WHERE
user.username = 'flask-admin'
)
AND post.id = post_tags.post_id
AND tag.id = post_tags.tag_id
AND post.id = 1;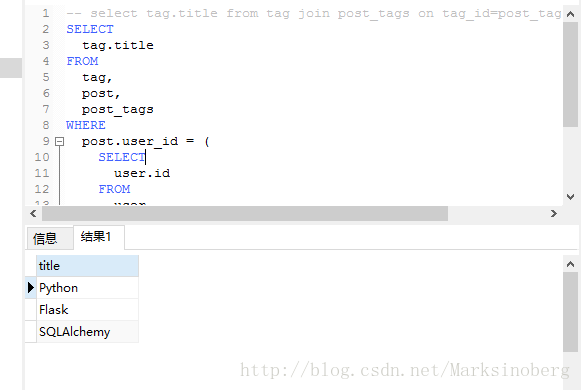
下面给评论添加一些数据。
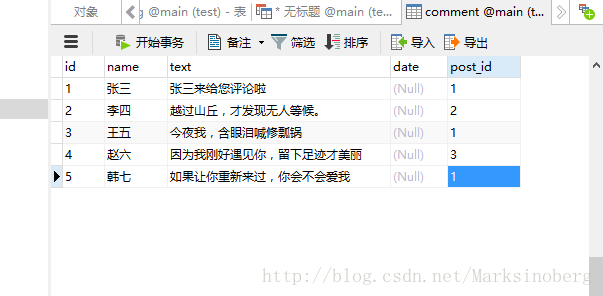
然后提交,在命令行中进行数据的验证。发现新加的数据已经反馈到了数据库。
>>> Comment.query.all()
[<[Comment] name:`张三`>, <[Comment] name:`李四`>, <[Comment] name:`王五`>, <[Comment] name:`赵六`>, <[Comment] name:`韩七`>]
>>> for comment in Comment.query.all():
... print(comment.name, comment.text, comment.date)
...
张三 张三来给您评论啦 None
李四 越过山丘,才发现无人等候。 None
王五 今夜我,含眼泪喊修瓢锅 None
赵六 因为我刚好遇见你,留下足迹才美丽 None
韩七 如果让你重新来过,你会不会爱我 None
>>>下面使用ORM方式来查询特定用户名的第一篇文章下的评论信息。
>>> for item in User.query.filter_by(username='flask-admin').first().posts[0].comments:
... print(item.name, '说:', item.text)
...
张三 说: 张三来给您评论啦
王五 说: 今夜我,含眼泪喊修瓢锅
韩七 说: 如果让你重新来过,你会不会爱我
>>>然后同样的,使用原生的SQL语句,进行查询。
SELECT
comment.name,
comment.text
FROM
comment,
user,
post
WHERE
user.username = 'flask-admin'
AND post.user_id = user.id
AND post.id = 1
AND comment.post_id = post.id;结果如下:
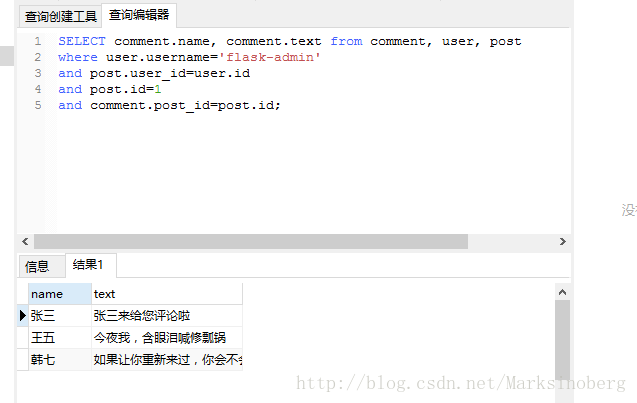
对比之后不难发现,貌似使用ORM的方式的逻辑更加清晰。可能是习惯了吧。
总结
在使用flask-sqlalchemy拓展的时候,可能最让人疑惑的地方就是backref了吧。对此,我自己的理解就是一个反向引用,在面向对象的设计中,不管是一对多还是多对一,双方都是要有联系的。
通过用户可以找到该用户的所有文章,同样的,知道一篇文章,也能知道它的作者。这就是backref。
对比原生SQL和ORM,我倒是觉得,两者各有优点吧。
- 原生的SQL对于创建表结构更加简洁,易懂。
- 使用ORM在查询相关的内容时,逻辑更加的清晰,而且基于流的操作更顺手。
不管是使用ORM还是使用原生的SQL,掌握原生的SQL是必备的基础。因为ORM底层还是转换成原生的SQL来工作的。