正则表达式
- 通用的字符串表达框架
- 简介表达一组字符串的表达式
- 针对字符串表达“简洁”和“特征”思想的工具
- 判断某字符串的特征归属
正则表达式的语法

经典正则表达式实例

Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配。
正则表达式的表示类型
raw string类型(原生字符串类型),是不包含转义符 \ 的字符串
re库采用raw string类型表示正则表达式,表示为:r’text’
例如: r’[1-9]\d{5}’
r’\d{3}-\d{8}|\d{4}-\d{7}’
Re库主要功能函数

re.search(pattern,string,flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象;
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;

例子:
import re
match = re.search(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0)) #'100081'
re.match(pattern,string,flags=0)
从一个字符串的开始位置起匹配正则表达式,返回match对象
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;
例子:
import re
'''
这是小编准备的python爬虫学习资料,加群:1136201545 即可免费获取!
'''
m-atch = re.match(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0)) #NULL
match = re.match(r'[1-9]\d{5}','100081 BIT')
if match:
print(match.group(0)) #'100081'
re.findall(pattern,string,flags=0)
搜索字符串,以列表类型返回全部能匹配的子串
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;
例子:
import re
ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084')
print(ls) #['100081', '100084']
re.split(pattern,string,maxsplit=0,flags=0)
将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- maxsplit:最大分割数,剩余部分作为最后一个元素输出;
- flags:正则表达式使用时的控制标记;
例子:
import re
ls = re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')
print(ls) #['BIT', ' TSU', '']
ls2 = re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)
print(ls2) #['BIT', ' TSU10084']
re.finditer(pattern,string,flags=0)
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素都是match对象
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;
例子:
import re
for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(m.group(0)) #100081 100084
re.sub(pattern,repl,string,count=0,flags=0)
在一个字符串中替换所有匹配正则表达式的子串,并返回替换后的字符串
- pattern:正则表达式的字符串或原生字符串表示;
- repl:替换匹配字符串的字符串;
- string:待匹配字符串;
- count:匹配的最大替换次数
- flags:正则表达式使用时的控制标记;
例子:
import re
rst = re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT 100081,TSU 100084')
print(rst) # 'BIT :zipcode TSU :zipcode'
Re库的另一种用法
编译后的对象拥有的方法和re库主要功能函数相同
#函数式用法:一次性操作
rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
#面向对象用法:编译后的多次操作
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
re.compile(pattern,flags=0)
将正则表达式的字符串形式编译成正则表达式对象
- pattern:正则表达式的字符串或原生字符串表示;
- flags:正则表达式使用时的控制标记;
regex = re.compile(r’[1-9]\d{5}’)
Re库的match对象
import re
match = re.search(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0)) # '100081'
print(type(match)) # <class 're.Match'>
Match对象的属性
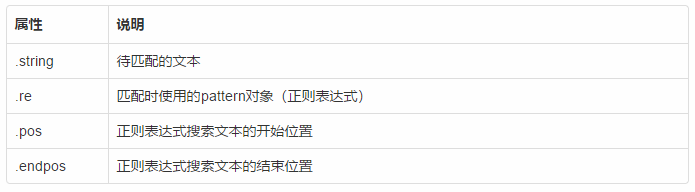
Match对象的方法
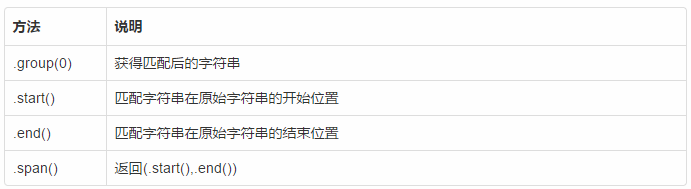
import re
m = re.search(r'[1-9]\d{5}', 'BIT100081 TSU100084')
print(m.string) # BIT100081 TSU100084
print(m.re) # re.compile('[1-9]\\d{5}')
print(m.pos) # 0
print(m.endpos) # 19
print(m.group(0)) # '100081' 返回的是第一次匹配的结果,获取所有使用re.finditer()方法
print(m.start()) # 3
print(m.end()) # 9
print(m.span()) # (3, 9)
Re库的贪婪匹配和最小匹配
Re库默认采用贪婪匹配,即输出匹配最长的子串。
import re
match = re.search(r'PY.*N', 'PYANBNCNDN')
print(match.group(0)) # PYANBNCNDN
最小匹配方法:
import re
match = re.search(r'PY.*?N', 'PYANBNCNDN')
print(match.group(0)) # PYAN
最小匹配操作符
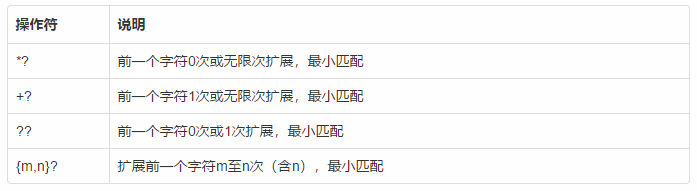
Re库实例之淘宝商品比价定向爬虫
功能描述:
目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格
理解:
- 淘宝的搜索接口
- 翻页的处理
技术路线:requests-re
程序的结构设计:
- 步骤1:提交商品搜索请求,循环获取页面
- 步骤2:对于每个页面,提取商品的名称和价格信息
- 步骤3:将信息输出到屏幕上
import requests
import re
'''
这是小编准备的python爬虫学习资料,加群:1136201545 即可免费获取!
'''
def getHTMLText(url):
#浏览器请求头中的User-Agent,代表当前请求的用户代理信息(下方有获取方式)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
try:
#浏览器请求头中的cookie,包含自己账号的登录信息(下方有获取方式)
coo = ''
cookies = {}
for line in coo.split(';'): #浏览器伪装
name, value = line.strip().split('=', 1)
cookies[name] = value
r = requests.get(url, cookies = cookies, headers=headers, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#解析请求到的页面,提取出相关商品的价格和名称
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 2 #爬取深度,2表示爬取两页数据
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)