前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
多线程+代理池爬取天天基金网、股票数据(无需使用爬虫框架)
简介
提到爬虫,大部分人都会想到使用Scrapy工具,但是仅仅停留在会使用的阶段。为了增加对爬虫机制的理解,我们可以手动实现多线程的爬虫过程,同时,引入IP代理池进行基本的反爬操作。
本次使用天天基金网进行爬虫,该网站具有反爬机制,同时数量足够大,多线程效果较为明显。
IP代理池
多线程
爬虫与反爬
首先,开始分析天天基金网的一些数据。经过抓包分析,可知: ./fundcode_search.js包含所有基金的数据,同时,该地址具有反爬机制,多次访问将会失败的情况。
同时,经过分析可知某只基金的相关信息地址为:fundgz.1234567.com.cn/js/ + 基金代码 + .js
分析完天天基金网的数据后,搭建IP代理池,用于反爬作用。搭建代理池,由于该作者提供了一个例子,所以本代码里面直接使用的是作者提供的接口。如果你需要更快速的获取到普匿IP,则可以自行搭建一个本地IP代理池。
搭建完IP代理池后,我们开始着手多线程爬取数据的工作。一旦使用多线程,则需要考虑到数据的读写顺序问题。这里使用python中的队列queue进行存储基金代码,不同线程分别从这个queue中获取基金代码,并访问指定基金的数据。由于queue的读取和写入是阻塞的,所以可以确保该过程不会出现读取重复和读取丢失基金代码的情况。
现在,开始编写如何获取指定基金的代码。首先,该函数必须先判断queue是否为空,当不为空的时候才可进行获取基金数据。同时,当发现访问失败时,则必须将我们刚刚取出的基金代码重新放回到队列中去,这样才不会导致基金代码丢失。
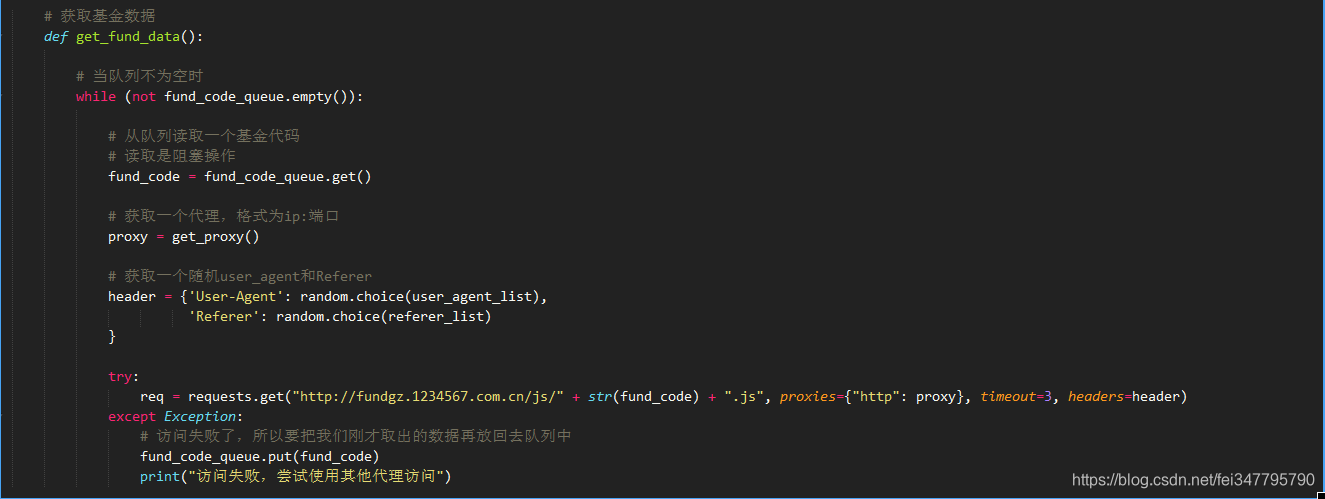
当访问成功时,则说明能够成功获得基金的相关数据。当我们在将这些数据存入到一个.csv文件中,会发现数据出现错误。这是由于多线程导致,由于多个线程同时对该文件进行写入,导致出错。所以需要引入一个线程锁,确保每次只有一个线程写入。
至此,大部分工作已经完成了。为了更好地实现伪装效果,我们对header进行随机选择。
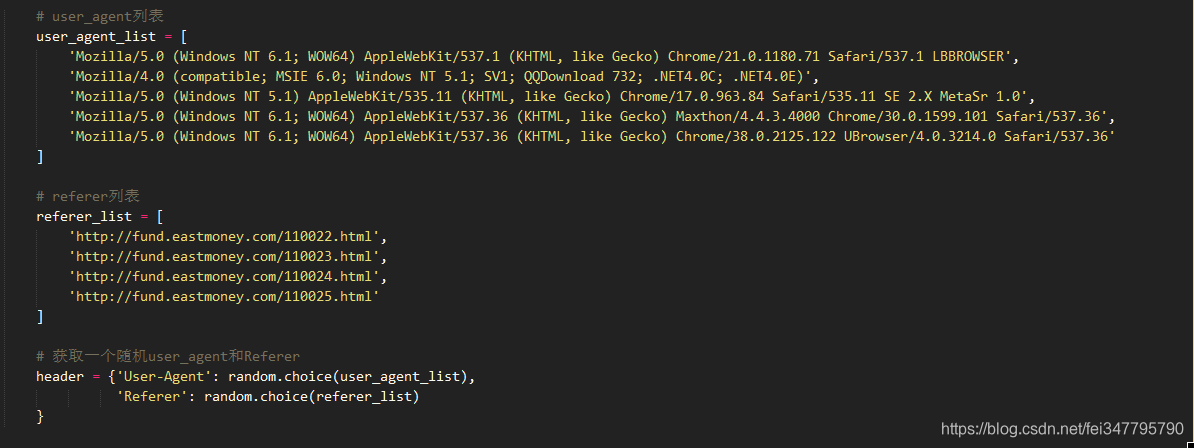
最后,在main中,开启线程即可。
通过对多线程和IP代理池的实践操作,能够更加深入了解多线程和爬虫的工作原理。当你在使用一些爬虫框架的时候,就能够做到快速定位错误并解决错误。
数据格式
000056,建信消费升级混合,2019-03-26,1.7740,1.7914,0.98,2019-03-27 15:00
000031,华夏复兴混合,2019-03-26,1.5650,1.5709,0.38,2019-03-27 15:00
000048,华夏双债增强债券C,2019-03-26,1.2230,1.2236,0.05,2019-03-27 15:00
000008,嘉实中证500ETF联接A,2019-03-26,1.4417,1.4552,0.93,2019-03-27 15:00
000024,大摩双利增强债券A,2019-03-26,1.1670,1.1674,0.04,2019-03-27 15:00
000054,鹏华双债增利债券,2019-03-26,1.1697,1.1693,-0.03,2019-03-27 15:00
000016,华夏纯债债券C,2019-03-26,1.1790,1.1793,0.03,2019-03-27 15:00
功能截图