前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
准备工作
要爬数据一般第一步是要确认爬虫的入口网页,也就是从哪里开始爬,沿着入口网页找到下一个URL,找-爬-找,不断循环重复直到结束。一般来说入口网页的分析都可以在scrapy内部进行处理,如果事先就已经可以明确知道所有要请求的网页地址,那么也可以直接把url列表扔进scrpay里,让它顺着列表一直爬爬爬就行了。
本次为了说的清晰一点,爬虫部分不用再次解释,所以分步进行,先把要爬的所有url准备好等下可以直接使用。之前说过了,WordPress所有的插件名称列表在这里可以找到 http://plugins.svn.wordpress.org/ ,这网页是一个非常简单的静态网页,就是一个巨大的ul列表,每一个li就是一个插件名字:
<ul>
<li><a href="0-delay-late-caching-for-feeds/">0-delay-late-caching-for-feeds/</a></li>
<li><a href="0-errors/">0-errors/</a></li>
<li><a href="001-prime-strategy-translate-accelerator/">001-prime-strategy-translate-accelerator/</a></li>
<li><a href="002-ps-custom-post-type/">002-ps-custom-post-type/</a></li>
<li><a href="011-ps-custom-taxonomy/">011-ps-custom-taxonomy/</a></li>
<li><a href="012-ps-multi-languages/">012-ps-multi-languages/</a></li>
这里的href就是插件的slug,是wordpress.org用来确定插件的唯一标示。解析这种html对Python来说简直是小菜一碟,比如最常用的 BeautifulSoup 或者 lxmp,这次决定尝试一个比较新的库,Requests-HTML: HTML Parsing for Humans ,这也是开发出Requests库的大神kennethreitz的又一力作,用于解析 HTML 文档的简直不要太爽了。
slug得到后,按照API的url格式地址组合起来,全部写入一个文件中就可以了。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('http://plugins.svn.wordpress.org/')
links = r.html.links
slugs=[ link.replace('/','') for link in links ]
plugins_urls=[ "https://api.wordpress.org/plugins/info/1.0/{}.json".format(slug) for slug in slugs ]
with open('all_plugins_urls.txt','a') as out:
out.write("\n".join(plugins_urls))
作为对比,可以看下用 BeautifulSoup 的方法:
import requests
from bs4 import BeautifulSoup
html=requests.get("http://plugins.svn.wordpress.org/").text
soup=BeautifulSoup(html,features="lxml")
lis=soup.find_all('li')
baseurl="https://api.wordpress.org/plugins/info/1.0/"
with open('all_plugins_urls.txt','a') as out:
for a in soup.find_all('a', href=True):
out.write( baseurl + a['href'].replace('/','') + ".json"+"\n")
就这么一个简单对比还是比较明显的,简单明了。最终,这一步的输出结果就是这个all_plugins_urls.txt文件了,总共有79223个插件。
有了这个列表,其实下面的Scrapy步骤其实完全可以不用,直接拿wget都可以全部简单粗暴的怼下来7万个json文件:
wget -i all_plugins_urls.txt
或者用requests简单的遍历请求一下就完事了,就可以得到所有插件的数据,进而可以直接进入数据分析阶段了。为了作为演示吧,也算作是一个简单的scrapy的介绍,对于没有接触过scrapy的朋友来说,可以是一个很初步的入门介绍。
安装 scrapy
这一步最简单的方式就是pip安装
pip install Scrapy
scarpy -V # 验证一下
新建项目 (Project):新建一个新的爬虫项目
scrapy 提供了完善的命令工具可以方便的进行各种爬虫相关的操作。一般来说,使用 scrapy 的第一件事就是创建你的Scrapy项目。我的习惯是首先新建一个文件夹(用要爬的网站来命名,这样可以方便的区分不同网站的爬虫项目)作为总的工作区, 然后进入这个文件夹里新建一个 scrapy 的项目,项目的名字叫做 scrap_wp_plugins,可以改成你想要的名字
mkdir ~/workplace/wordpress.org-spider
cd ~/workplace/wordpress.org-spider
scrapy startproject scrap_wp_plugins
这样就会自动创建好类似如下的文件结构:
├── scrap_wp_plugins
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
4 directories, 7 files
对我们这个需求来说,除了settings.py需要做一点点修改,其余文件都先不用管它,在这个简单的不能再简单的项目里都用不到。
目前只是一个空架子,啥也干不了,因为还没有爬虫文件,你可以完全纯手写,也可以用模板来生成一个。我们就用scrapy的命令行自动生成一个爬虫,语法格式是这样:
Syntax: scrapy genspider [-t template]
template 是要使用的爬虫的模板,默认的就是用最基本的一个。
name 就是爬虫的名字,这个可以随便取,等下要开始爬的时候会用到这个名字。好比给你的小蜘蛛取名叫“春十三”,那么在召唤它的时候你就可以大喊一声:“上吧!我的春十三!”
domain 是爬虫运行时允许的域名,好比说:“上吧!我的春十三!只沿着这条路线上!”
所以执行如下命令即可:
cd scrap_wp_plugins
scrapy genspider plugins_spider wordpress.org
这样就会在spiders文件夹下生出一个叫plugins_spider.py的爬虫文件,也就是在这里面可以填充一些爬取逻辑和内容解析。
制作爬虫(Spider):制作爬虫开始爬取网页
首先我们打开scrap_wp_plugins/plugins_spider.py看下里面的内容:
# -*- coding: utf-8 -*-
import scrapy
class PluginsSpiderSpider(scrapy.Spider):
name = 'plugins_spider'
allowed_domains = ['wordpress.org']
start_urls = ['http://wordpress.org/']
def parse(self, response):
pass
可以看出这就是一个最简单scrapy的Spider的类而已,自动填入了上一步用来创建爬虫时的一些参数。
name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字,就是上一步的命令行里写的plugins_spider.
start_urls:爬虫开始爬的一个URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些URLS开始。其他URL将会从这些起始URL中继承性生成。具体来说,在准备工作那一部分,我们已经得到了一个urls的列表文件all_plugins_urls.txt,现在只需要把这个文件读取进来就好了。
parse():爬虫的方法,调用时候传入从每一个URL传回的Response对象作为参数,response将会是parse方法的唯一的一个参数,
这个方法负责解析返回的数据、匹配抓取的数据(解析为item)并跟踪更多的URL。在本项目中,因为返回的是json,不需要解析任何html,这里为了省事我就直接把json整个存储起来已备后面数据分析的时候再选择需要的字段,当然你也可以根据需要选择过滤掉不需要的json字段。
所以,我们的第一个爬虫就呼之欲出了!请看代码,麻雀虽小五脏俱全
# -*- coding: utf-8 -*-
import scrapy
import json
import jsonlines
运行爬虫
改完上面的爬虫代码,现在就可以让爬虫跑起来了,“上吧!比卡丘!”
scrapy crawl plugins_spider
哦嚯。。。
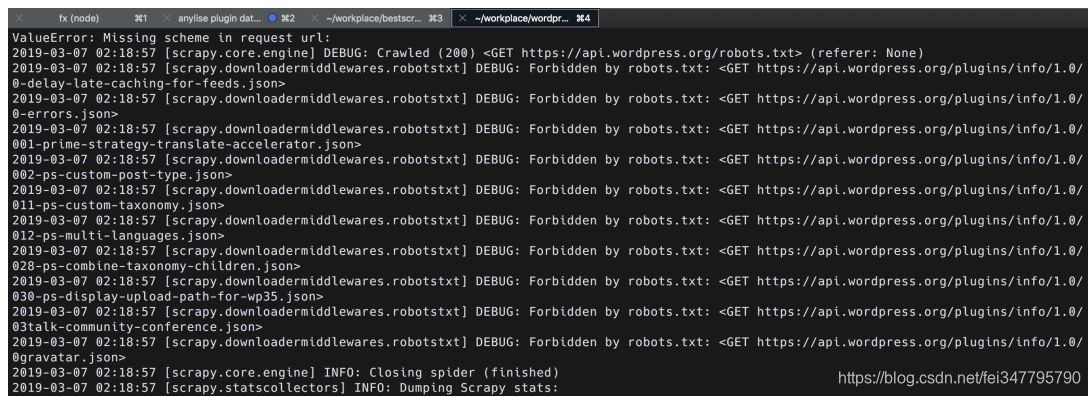
意外发生了。。。啥也没爬下来??自信看下报错信息,原来是 https://api.wordpress.org/robots.txt 规定了不允许爬虫,而scrapy默认设置里是遵守robot协议的,所以简单绕过就行了,打开 setttings.py, 找到下面这行,把True改为False,意思是:“爱咋咋地,我不理你的robots.txt ”
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
现在就可以愉快的爬取了。还有一点温馨提示,如果爬取数量比较多,不想中途因为断网或者其他什么鬼知道的意外中断,导致下次又要重新来过,可以加上scrapy的执行日志来保存爬虫状态,下次就会从中断处开始继续爬取
scrapy crawl plugins_spider -s JOBDIR=spiderlog --logfile log.out &
这样就可以安心的去睡个觉,一早起来就能看到热呼呼新鲜出路的WordPress所有的插件信息了。