前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
代码走起来,爬虫套路上吧
简单的requests,复杂的scrapy 总有一款适合你的
哇哦~从2011年到2019年都有唉
月份点进去,呈现了大概这些信息,最高气温,最低气温,天气,风向,风力,好了数据都有了
http://lishi.tianqi.com/sanya/201101.html

到这个地方不着急,慢慢来,一个天天写爬虫的人必须要对URL敏感,一看就嗨,小时候喜欢找规律的人长大都能写爬虫
URL 是这样子的
http://lishi.tianqi.com/sanya/201111.html
http://lishi.tianqi.com/sanya/201102.html
http://lishi.tianqi.com/sanya/201103.html
http://lishi.tianqi.com/sanya/201104.html
http://lishi.tianqi.com/[三亚的拼音]/年月.html
OK,这就简单了,走起,看起来就简单,那我就使用pyspider了 ,好久没有,都有点遗忘了呢
怎么运行呢?
一顿操作,数据就下载到了
没有特别复杂的地方,基本就属于常规操作了
def __init__(self):
self._city = "sanya"
def get_date_list(self,begin,end):
date_list = [x.strftime("%Y%m") for x in list(pd.date_range(start=begin,end=end,freq="M"))]
return date_list
@every(minutes=24 * 60)
def on_start(self):
# 我需要生成201101~201812的所有链接
date_list = self.get_date_list("2011-01-01","2019-01-01")
for item in date_list:
self.crawl('http://lishi.tianqi.com/%s/%s.html' %(self._city,item) , callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
items = []
for each in response.doc('.tqtongji2 > ul:not(.t1)').items():
date = each("li:eq(0)").text()
hot = each("li:eq(1)").text()
cold = each("li:eq(2)").text()
weather = each("li:eq(3)").text()
wind_direction = each("li:eq(4)").text()
wind_power = each("li:eq(5)").text()
item = {
"date":date,
"hot":hot,
"cold":cold,
"weather":weather,
"wind_direction":wind_direction,
"wind_power":wind_power}
items.append(item)
return items
基本数据分析
首先看一下数据的基本面
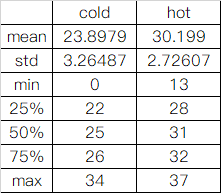
- 75% 都是26度的天气,很舒服
- 都发现了异常数据,例如最低气温最小的竟然为0,最高气温为13,不合理
- 最热竟然是37度,还不如我大河北温度,奇怪了?
excel 读取
def read_xlsx():
df = pd.read_excel("天气数据.xlsx",names =["cold","date","hot","weather","wind","wind_s"])
return df
我要知道,三亚天气的一个走势,这个地方直接按照时间进行图标制作吧
按照时间排序
df = read_xlsx()
opt_df = df[['date','cold','hot']]
opt_df = opt_df.sort_values(by='date')
可以明显的看到波峰和波谷,这个地方只能知道三亚的天气是有波动的,距离我得到最后的结果进了一点点

按照单独的一年绘制,得到一个很混乱的图,还是没有得到我想要的结果
opt_df = opt_df.set_index("date")
for i in range(2011,2019):
data = opt_df[str(i)]
plt.plot(range(1,len(data)+1), data['cold'])
plt.show()
每个颜色表示不同的年分,看来还是要用子图了。
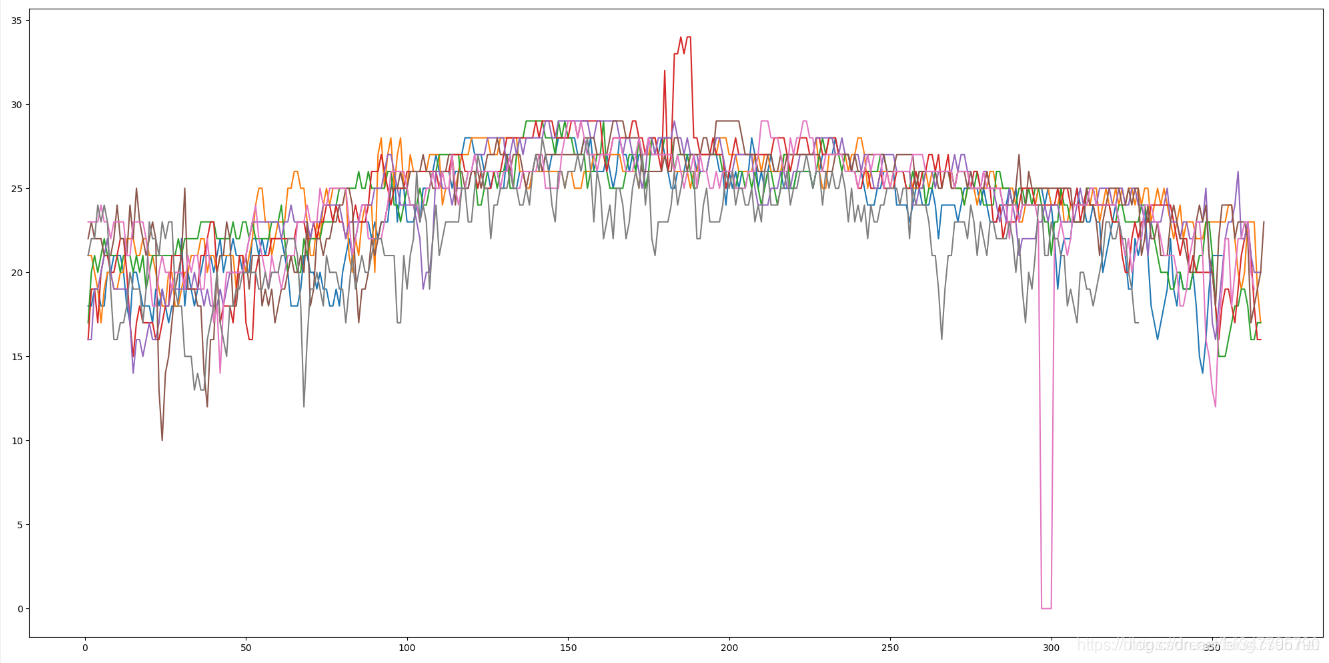
从上到下,我从2011年依次罗列到2018年
opt_df = opt_df.set_index("date")
for i in range(2011,2019):
data = opt_df[str(i)]
plt.subplot(8,1,i-2010)
plt.grid(True)
plt.plot(range(1,len(data)+1), data['cold'])
plt.plot(range(1, len(data) + 1), data['hot'])
plt.title(str(i)+u"年,温度曲线")
plt.tight_layout()
plt.savefig("filename.png")
plt.show()
一个小的注意事项是:解决使用 plt.savefig 保存图片时一片空白
原因
其实产生这个现象的原因很简单:在 plt.show() 后调用了 plt.savefig() ,在 plt.show() 后实际上已经创建了一个新的空白的图片(坐标轴),这时候你再 plt.savefig() 就会保存这个新生成的空白图片。
知道了原因,就不难知道解决办法了,解决办法有两种:
在 plt.show() 之前调用 plt.savefig();
import matplotlib.pyplot as plt
""" 一些画图代码 """
plt.savefig("filename.png")
plt.show()
画图的时候获取当前图像(这一点非常类似于 Matlab 的句柄的概念):
# gcf: Get Current Figure
fig = plt.gcf()
plt.show()
fig1.savefig('tessstttyyy.png', dpi=100)

细细的看了一下,发现好稳定。。。。走势变化不大,那么,在去细化,我们拆解2018年的,然后推断2019年的,这个地方需要的展示12个月份的天气了,代码走起。
d2018 = opt_df["2018"]
print(d2018)
for i in range(1,13):
data = opt_df["2018-"+str(i)]
plt.subplot(12, 1, i)
plt.grid(True)
plt.plot(range(1, len(data) + 1), data['cold'])
plt.plot(range(1, len(data) + 1), data['hot'])
plt.title(str(i) + u"月,温度曲线")
plt.yticks([0,5,10,15,20,25,30,35,40])
plt.xticks(range(1,32))
plt.tight_layout()
plt.savefig("filename.png")
plt.show()

