原文出处:https://www.cnblogs.com/zzry/p/5857751.html
延伸阅读:Sql Server优化---统计信息维护策略
某日同事丢给我一个看上去复杂的查询(实际就涉及两张表,套来套去)说只是换了日期条件,但一个查询5秒出数据,一个根本查不出来。现在整理下解决过程,及涉及的知识点。
若有不正之处,请多多谅解并欢迎批评指正,不甚感激。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/zzry/p/5857751.html
一.问题描述
环境:sqlserver 2008r2
现象:
查询涉及到两张表
ODS_TABLE_A 每日数据700万现在总计60多亿。 已建立索引+分区
MID_TABLE_B 每日数据20万 总计3000万。 已建立索引未分区
当etldate为 '2016-08-12' 及以前的时间时,本查询5秒出数据,
当etldate为 '2016-08-16' 及以后的时间时,本查询出不来数据。
贴上问题sql:做过数据字段处理,针对本篇主题注意点放在查询因为日期的选择不同导致查询时间变的超级慢,而不是改变sql写法比如用临时表,强制索引上。
----------《代码开始》
select
COUNT(distinct(case when COL_USERID3 is null then COL_USERID6 end)) as 'aa',
COUNT(distinct(case when COL_USERID3 is null and COL_USERID7 is not null then COL_USERID6 end)) as 'bb',
COUNT(distinct(case when COL_USERID3 is not null then COL_USERID6 end)) as 'cc',
COUNT(distinct(case when COL_USERID3 is not null and COL_USERID7 is not null then COL_USERID6 end)) as 'dd',
SUM(case when COL_USERID3 IS not null then ee end) as 'ee'
from
(
select c.COL_USERID3,c.ee,g.COL_USERID6
from
(
select b.COL_USERID2 as COL_USERID3,COUNT(b.COL_USERID2) as ee
from
(
select COL_USERID as COL_USERID1,min(EventTime) as time1
from ODS_TABLE_A
where EtlDate = '2016-08-12'
and colid LIKE 'heihei%'
group by COL_USERID
)as a
join
(
select COL_USERID as COL_USERID2,eventtime as time2
from ODS_TABLE_A
where EtlDate = '2016-08-12'
and ItemId = '1111111111101'
and colid like 'haha-%'
and colid not like 'haha-skill%'
and colid not like 'haha-fine%'
)as b
on a.COL_USERID1 = b.COL_USERID2 and a.time1 > b.time2
group by b.COL_USERID2
)as c
right join
(
select DISTINCT d.COL_USERID4 as COL_USERID6
from
(
select distinct COL_USERID as COL_USERID4
from MID_TABLE_B
where etldate = '2016-08-12'
)as d
join
(
select COL_USERID AS COL_USERID5
from ODS_TABLE_A
where EtlDate = '2016-08-12'
and colid LIKE 'heihei%'
)as f
on d.COL_USERID4 = f.COL_USERID5
)as g
on c.COL_USERID3 = g.COL_USERID6
)as i
left join
(
select COL_USERID as COL_USERID7
from MID_TABLE_B
where EtlDate = '2016-08-12'
and IsTodayPay = '1'
)as h
on i.COL_USERID6 = h.COL_USERID7
----------《代码结束》
二。解决过程
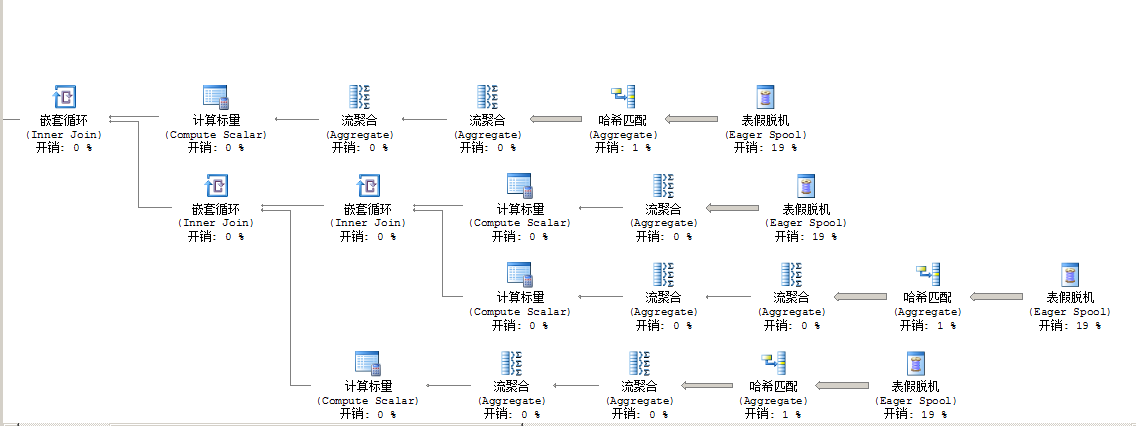
1.先看了下上述代码的执行计划如下图初看上去需要用索引的地方都用到了。应该没啥大问题。
可能你注意到系统提示的缺少索引信息,加上去一样效果,不能解决‘2016-08-16’ 查询慢的问题。

2.在修改下日期 ,就是把 【所有】 etldate=‘2016-08-12’ 的改成 etldate=‘2016-08-16’
看下执行计划:
对不起跑了半个小时没出来,查看估计的执行执行和上面的图类似。
减少涉及到数据集的量 加top 1 我再看执行计划:
不贴图了 结果就是比上面的图少了个 【并行度】
初步以为是优化器因为估计行数等不准的原因没选择并行度,赶紧找代码让它强行这样走。
找到一篇宋大师的:强制SQL Server执行计划使用并行提升在复杂查询语句下的性能
http://www.cnblogs.com/CareySon/p/3851113.html
二话不说加关键字
OPTION(querytraceon 8649) //并行提升在复杂查询语句下的性能
可是应用到实际发现查询效率无任何改善,久久不出结果。后来问宋大师(感谢宋大神)。他说有些操作是没法并行的,更新统计信息试试先。
一击命中!一击命中!一击命中!
执行如下代码:
update STATISTICS ODS_TABLE_A --(把ODS_TABLE_A 这个大表统计信息更新)
默认情况下,查询优化器已根据需要更新统计信息以改进查询计划;但在某些情况下,你可以通过使用 UPDATE STATISTICS 或存储过程 sp_updatestats 来比默认更新更频繁地更新统计信息,提高查询性能。针对文中此种情况新插入的数据没统计信息,大表自动更新统计信息触发自动更新机制频率不够,最好定期更新。
关于update STATISTICS 就不累述了 :给出相关技术贴连接
更新统计相关知识点传送门:https://msdn.microsoft.com/zh-cn/library/ms187348.aspx
至此问题解决。
三。总结
对于大表新插入的数据没及时更新统计信息,导致出现上面文中的现象,一个日期导致查询效率天壤之别的分水岭(查12号前5秒出数据,查12号后死活不出来。)
解决办法是大表自动更新统计信息触发自动更新机制频率不够,定期更新。