前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
通过requests库已经可以抓到网页源码,接下来要从源码中找到并提取数据。BeautifulSoup是python的一个库,其最主要的功能是从网页中抓取数据。BeautifulSoup目前已经被移植到bs4库中,也就是说在导入BeautifulSoup时需要先安装bs4库。安装好bs4库以后,还需安装lxml库。如果我们不安装lxml库,就会使用Python默认的解析器。尽管Beautiful Soup既支持Python标准库中的HTML解析器又支持一些第三方解析器,但是lxml库具有功能更加强大、速度更快的特点,因此推荐安装lxml库。安装Python第三方库后,输入下面的代码,运行结果如图1所示,即可开启Beautiful Soup之旅。

接下来对每行代码进行细致的解析:
1、理解Beautiful Soup
url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text,'lxml')
首先,HTML文档将被转换成Unicode编码格式,然后Beautiful Soup选择最合适的解析器来解析这段文档,此处指定lxml解析器进行解析。**解析后便将复杂的HTML文档转换成树形结构,并且每个节点都是Python对象。**这里将解析后的文档存储到新建的变量soup中,代码如下。接下来用select(选择器)定位数据,定位数据时需要使用浏览器的开发者模式,将鼠标光标停留在对应的数据位置并右击,然后在快捷菜单中选择“检查”命令,如图2所示。随后在浏览器右侧会弹出开发者界面,右侧高亮的代码对应着左侧高亮的数据文本。右击右侧高亮数据,在弹出的快捷菜单中选择"Copy一"Copy Selector命令,便可以自动复制路径。

#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(3) > a
由于这条路径是选中的第一条的路径,而我们需要获取所有的头条新闻,因此将li:nth-child(3)中冒号(包含冒号)后面的部分删掉,使用 soup.select引用这个人路径,代码如下。
Data=soup.select(‘[#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a’)
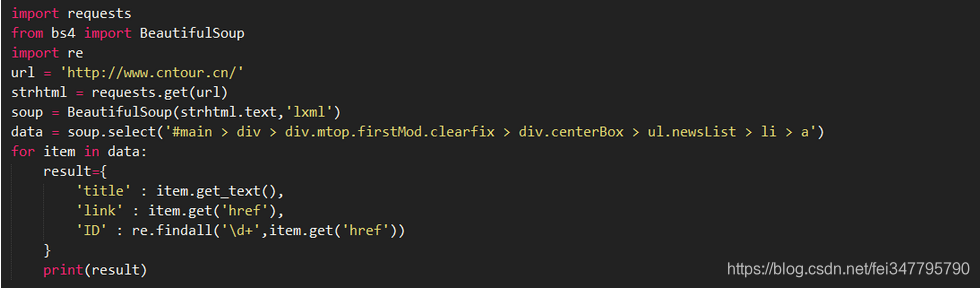
2、对数据进行提取
result={
'title' : item.get_text(),
'link' : item.get('href'),
'ID' : re.findall('\d+',item.get('href'))
}
首先明确要提取的数据是标题和链接,标题在标签中,提取标签的正文用get_text()方法。链接在标签的href属性中,提取标签中的href属性用get()方法,在括号中指定要提取的属性数据,即get('href)。在开发者模式中我们可以看到,每一篇文章的链接中都有一个数字ID。下面用正则表达式提取这个ID. 需要使用的正则符号如下。
\d 匹配数字
‘+’ 匹配前一个字符1次或多次
在Python中调用正则表达式时使用re库,这个库不用安装,可以直接调用。使用re库的findall方法第一个参数表示正则表达式,第二个参数表示要提取的文本。