1. 知乎文章图片写在前面
今天开始尝试爬取一下知乎,看一下这个网站都有什么好玩的内容可以爬取到,可能断断续续会写几篇文章,今天首先爬取最简单的,单一文章的所有回答,爬取这个没有什么难度。
找到我们要爬取的页面,我随便选了一个
https://www.zhihu.com/question/292393947
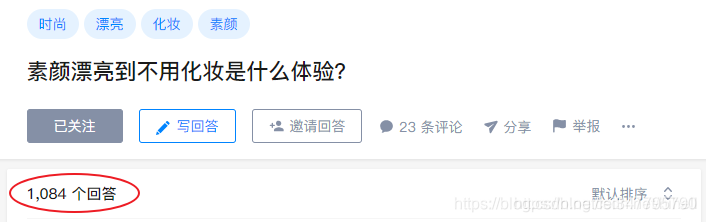
1084个回答,数据量可以说非常小了,就爬取它吧。
2. 知乎文章图片选取操作库和爬取地址
爬取使用requests 存储使用 mongodb 就可以了
爬取地址经过分析之后,找到了一个可以返回json的数据接口
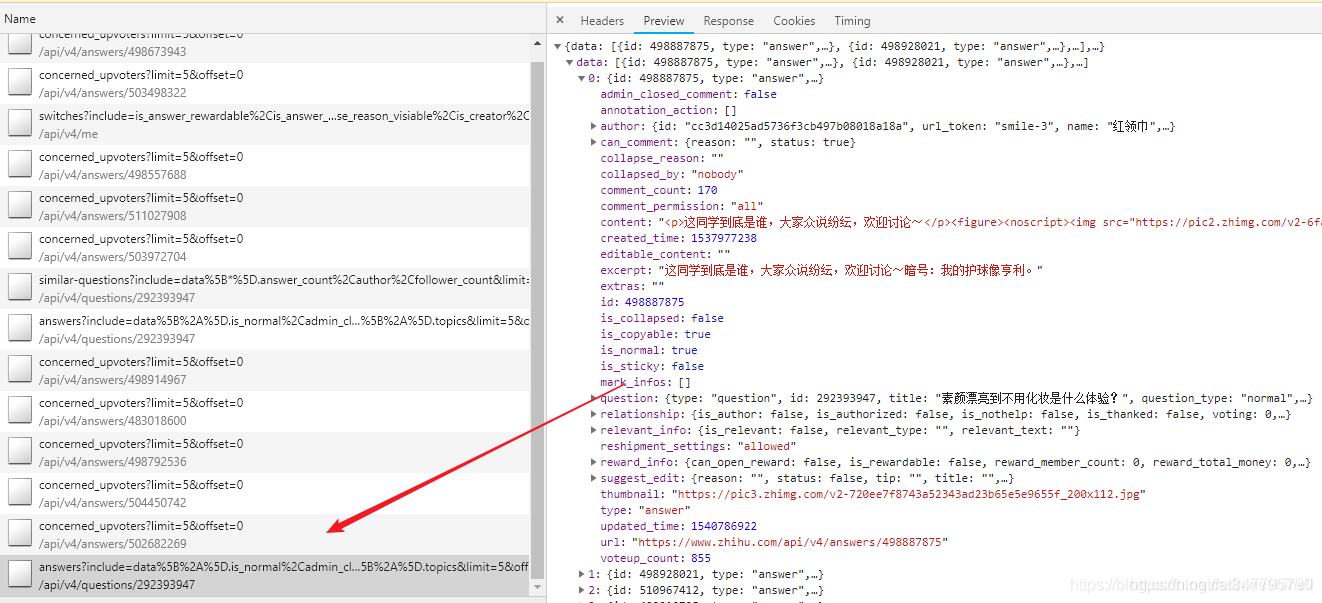
提取链接,看一下各参数的意思,方便我们程序模拟
https://www.zhihu.com/api/v4/questions/292393947/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=10&sort_by=default
上面的连接进行了URL编码,去找个解码工具解析一下,编程下面的URL就比较好解释了,answers后面跟了一堆的参数,应该是返回的关键字,找到limit每页显示的数据量,offset偏移量,我们下拉滚动条,发现这个在不断的叠加+5,sort_by 就是排序。
https://www.zhihu.com/api/v4/questions/292393947/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&limit=5&offset=10&sort_by=default
做好上面的工作,接下来就是爬取了,我简化了一下爬取的地址,只保留了一些关键的信息
include=comment_count,content,voteup_count,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&limit=5&offset=0&sort_by=default
3. 知乎文章图片编写代码
分析完毕之后,发现代码非常简单了
import requests
from fake_useragent import UserAgent
'''
遇到不懂的问题?Python学习交流群:1136201545满足你的需求,资料都已经上传群文件,可以自行下载!
'''
############## 数据存储
import pymongo
import time
DATABASE_IP = '127.0.0.1'
DATABASE_PORT = 27017
DATABASE_NAME = 'sun'
client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT)
db = client.sun
db.authenticate("dba", "dba")
collection = db.zhihuone # 准备插入数据
##################################
class ZhihuOne(object):
def __init__(self,totle):
self._offset = 0
self._totle = totle
#self._ua = UserAgent()
def run(self):
print("正在抓取 {} 数据".format(self._offset))
headers = {
"upgrade-insecure-requests":"1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)"
}
with requests.Session() as s:
try:
with s.get("https://www.zhihu.com/api/v4/questions/292393947/answers?include=comment_count,content,voteup_count,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&limit=5&offset={}&sort_by=default".format(self._offset),headers=headers,timeout=3) as rep:
data = rep.json()
if data:
collection.insert_many(data["data"])
except Exception as e:
print(e.args)
finally:
if self._offset <= self._totle:
self._offset = self._offset + 5 # 每次+5
print("防止被办,休息3s")
time.sleep(3)
self.run()
else:
print("所有数据获取完毕")
if __name__ == '__main__':
# 偏移量是0,5,10 i=1 (i-1)*5
zhi = ZhihuOne(1084)
zhi.run()