前言💨
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文内容💨
Python爬虫入门教程23:A站视频的爬取,解密m3u8视频格式
Python爬虫入门教程25:绕过JS加密参数,实现批量下载抖某音无水印视频内容
Python爬虫入门教程27:爬取某电商平台数据内容并做数据可视化
Python爬虫入门教程28:爬取微博热搜榜并做动态数据展示
Python爬虫入门教程29:爬取某团烤肉店铺数据内容并做可视化展示
PS:如有需要 Python学习资料 以及 解答 的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境💨
- Python 3.6
- Pycharm
相关模块的使用💨
import csv
import requests
安装Python并添加到环境变量,pip安装需要的相关模块即可。
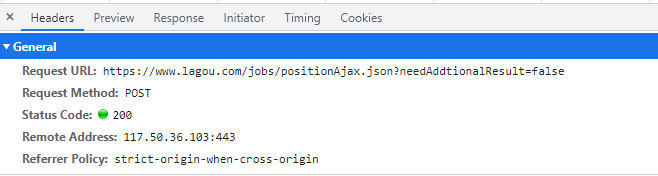
💥需求数据来源分析

通过开发者工具, 抓包分析之后知道数据是从哪可以获取之后, 可以查看一下请求的url地址以及请求方式等
💥代码实现
import csv
import requests
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'城市',
'公司名字',
'学历',
'经验',
'薪资',
'公司福利',
'详情页',
])
csv_writer.writeheader()
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
headers = {
'cookie': 'cookie',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, data=data, headers=headers)
result = response.json()['content']['positionResult']['result']
for index in result:
# pprint.pprint(index)
title = index['positionName'] # 标题
city = index['city'] # 城市
area = index['district'] # 区域
city_area = city + '-' + area
company_name = index['companyFullName'] # 公司名字
edu = index['education'] # 学历
money = index['salary'] # 薪资
exp = index['workYear'] # 经验
boon = index['positionAdvantage'] # 公司福利
href = f'https://www.lagou.com/jobs/{index["positionId"]}.html'
job_info = index['positionDetail'].replace('<br>\n', '').replace('<br>', '')
dit = {
'标题': title,
'城市': city_area,
'公司名字': company_name,
'学历': edu,
'经验': exp,
'薪资': money,
'公司福利': boon,
'详情页': href,
}
csv_writer.writerow(dit)
txt_name = company_name + '-' + title + '.txt'
with open(txt_name, mode='w', encoding='utf-8') as f:
f.write(job_info)
print(dit)
💥爬取数据展示