前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
开发工具
- python 3.6.5
- pycharm
import requests
import re
import csv
目标网页分析

马山就要双十一了,有女朋友的朋友准备好了吗~

之前关于京东、淘宝的商品数据都是爬取了,今天爬取一下唯品会的商品数据,之前就听朋友说起唯品会的商品价格要便宜一些,三个平台的数据都爬取了,可以自行去对比

通过开发者工具可以看到,网页并没有返回我们想要的商品数据,所以打算直接复制网页数据进行搜索查找
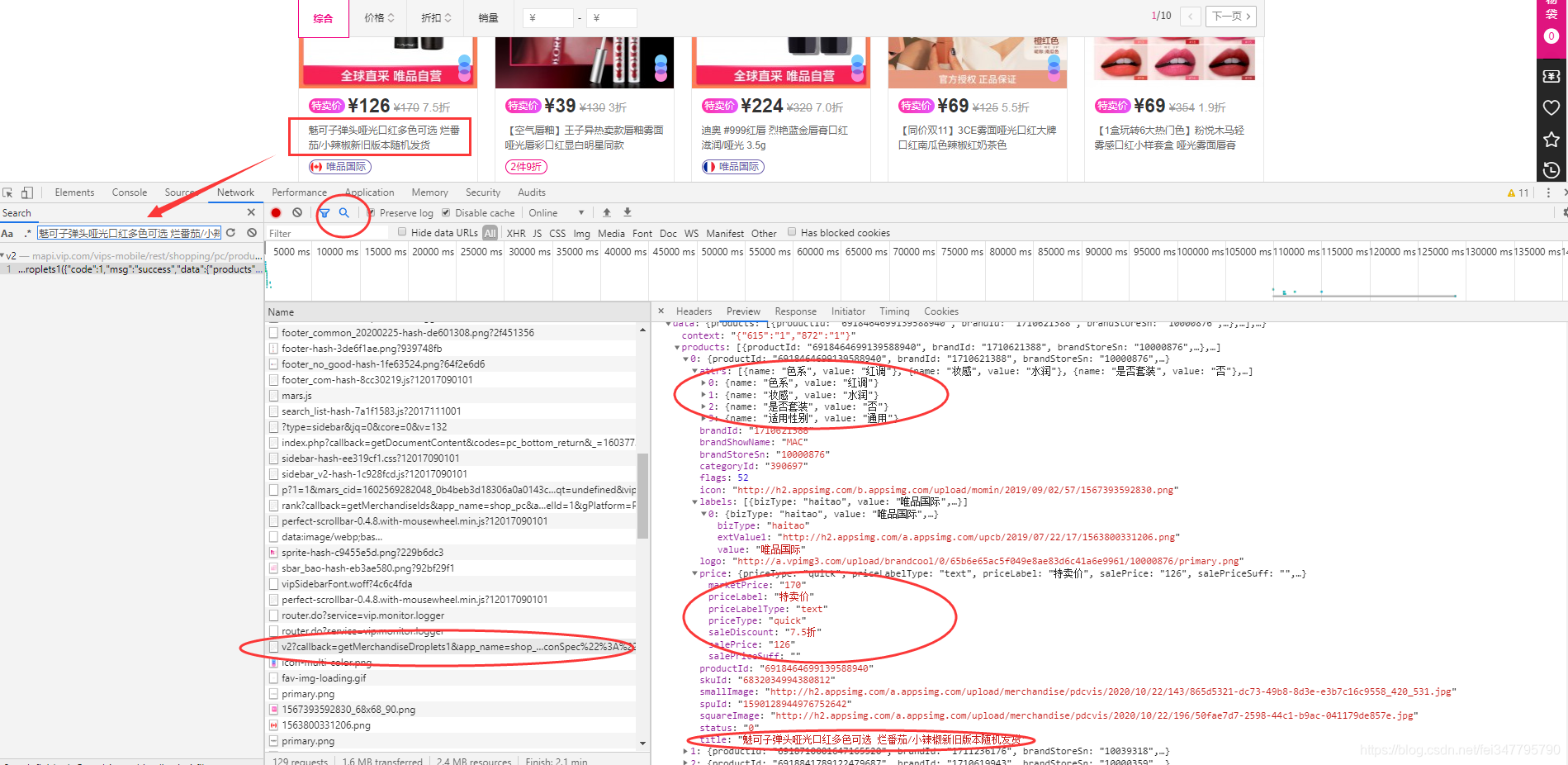
如上图所示,复制商品名字,在开发者工具里面直接搜索,可以看到相关的数据包,里面包含了商品标题、售价、原价、折扣以及商品的其他数据信息。
既然这个接口里面有想要的数据了,那接下来就是分析URL怎么样才能获取这个URL,因为这个数据包里面只有50条数据,然而唯品会一页是有120条数据的。
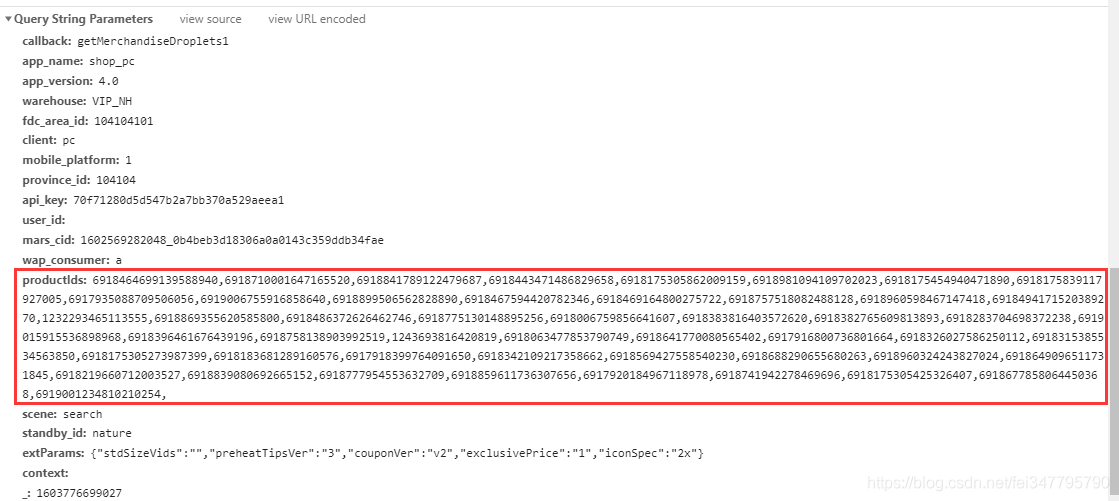
想要找到url的变化规律,那么就需要你自己多去看几个数据,同样的方法一个数据接口只要五十条数据,那么就可以选择第51条数据或者后面的数据去搜索,查找相对应的数据接口,通过一系列的对比发现,url中的参数productIds 的变化,参数中就是每个商品ID值了,那问题来了,怎么才能获取商品的ID值呢?其实方法和上面的一样,复制ID值找到相关的数据接口。

这里面就有这一整页 120个商品的id值,问题它又又双叒叕,总不能只爬取一页的数据吧,所以还要分析获取ID值每一页的url变化,还是一样想知道url的变化规律多看几页就知道了~
这里就省略了~
- 第一页

- 第二页

pageOffset参数的变化每120个数据翻一页嘛,ID都获取了,前面也看到每个商品数据接口对应的是50条数据,经过分析就知道 120个商品划分为是三个 50,50,20 分别传入相对应的商品ID就可以了。
实现代码
- 获取每页商品ID值
for page in range(0, 1201, 120):
url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/search/product/rank'
headers = {
'referer': 'https://category.vip.com/suggest.php?keyword=%E5%8F%A3%E7%BA%A2&ff=235%7C12%7C1%7C1&page=3',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
params = {
'callback': 'getMerchandiseIds',
'app_name': 'shop_pc',
'app_version': '4.0',
'warehouse': 'VIP_NH',
'fdc_area_id': '104104101',
'client': 'pc',
'mobile_platform': '1',
'province_id': '104104',
'api_key': '70f71280d5d547b2a7bb370a529aeea1',
'user_id': '',
'mars_cid': '1602569282048_0b4beb3d18306a0a0143c359ddb34fae',
'wap_consumer': 'a',
'standby_id': 'nature',
'keyword': '口红',
'lv3CatIds': '',
'lv2CatIds': '',
'lv1CatIds': '',
'brandStoreSns': '',
'props': '',
'priceMin': '',
'priceMax': '',
'vipService': '',
'sort': '0',
'pageOffset': '{}'.format(page),
'channelId': '1',
'gPlatform': 'PC',
'batchSize': '120',
'_': '1603721644362',
}
response = requests.get(url=url, params=params, headers=headers)
ids = re.findall('"pid":"(.*?)"', response.text, re.S)
- 获取商品数据
def get_data(num_id):
data_url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2'
headers = {
'referer': 'https://category.vip.com/suggest.php?keyword=%E5%8F%A3%E7%BA%A2&ff=235%7C12%7C1%7C1&page=3',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
params = {
'callback': 'getMerchandiseDroplets2',
'app_name': 'shop_pc',
'app_version': '4.0',
'warehouse': 'VIP_NH',
'fdc_area_id': '104104101',
'client': 'pc',
'mobile_platform': '1',
'province_id': '104104',
'api_key': '70f71280d5d547b2a7bb370a529aeea1',
'user_id': '',
'mars_cid': '1602569282048_0b4beb3d18306a0a0143c359ddb34fae',
'wap_consumer': 'a',
'productIds': '{}'.format(num_id),
'scene': 'search',
'standby_id': 'nature',
'extParams': '{"stdSizeVids":"","preheatTipsVer":"3","couponVer":"v2","exclusivePrice":"1","iconSpec":"2x"}',
'context': '',
'_': '1603721644366',
}
response_2 = requests.get(url=data_url, params=params, headers=headers)
titles = re.findall('"title":"(.*?)"', response_2.text, re.S) # 标题
salePrice = re.findall(',"salePrice":"(.*?)",', response_2.text, re.S) # 售价
marketPrice = re.findall('"marketPrice":"(.*?)"', response_2.text, re.S) # 原价
saleDiscount = re.findall('"saleDiscount":"(.*?)"', response_2.text, re.S) # 折扣
smallImage = re.findall('"smallImage":"(.*?)"', response_2.text, re.S) # 商品图片地址
lis = zip(titles, salePrice, marketPrice, saleDiscount, smallImage)
dit = {}
for li in lis:
dit['商品名字'] = li[0]
dit['售价'] = li[1]
dit['原价'] = li[2]
dit['折扣'] = li[3]
dit['商品图片地址'] = li[4]
print(dit)
- 保存数据
f = open('唯品会商品数据.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['商品名字', '售价', '原价', '折扣', '商品图片地址'])
csv_writer.writeheader()
csv_writer.writerow(dit)
其实数据接口里面还有其他的一些数据,但是这里只是为了演示就没有获取那么多数据了。
实现效果图


一共是1094条数据
特别说明:
相关代码都在上面,但是如果你是直接复制粘贴,是运行不了,肯定是会报错的~
授人以鱼不如授人以渔,特别对于一些自学python的小伙伴而说,顶多就是复制代码然后运行,运行成功出现结果,心中大喊:6666~
然后并没有什么用别说什么,想看到代码学习一下,相对应的代码都在上面,如果自己真的有去思考,没道理不会。