作者:小小明
Pandas数据处理专家,帮助一万用户解决数据处理难题。
最近碰到一个需求:
虽然我没完全看懂啥意思,但大意就是:
1.读取word文档,将其中所有的表格都写入到一个excel文件中
2.对写好的excel做出一些修改(包括改某几个单元格的值和删除行),然后将修改后的excel数据回填到word表对应的位置
对于第一个需求,直接用pandas写出即可
对于第二个需求,先生成模板,再用docxtpl模板渲染
关于docxtpl,我已经根据官方文档,制作了一份操作手册:https://blog.csdn.net/as604049322/article/details/112008531
好了,就按照这个大致理解的需求开始干:
读取word文档表格写入到excel
python代码:
from docx import Document
import pandas as pd
doc = Document(r"test.docx")
writer = pd.ExcelWriter("test.xlsx")
for i, table in enumerate(doc.tables):
header = [cell.text for cell in table.rows[0].cells]
result = []
for row in table.rows[1:]:
tmp = []
for cell in row.cells:
tmp.append(cell.text)
result.append(tmp)
df = pd.DataFrame(result, columns=header)
df.to_excel(writer, sheet_name=f"{i}", index=False)
writer.save()
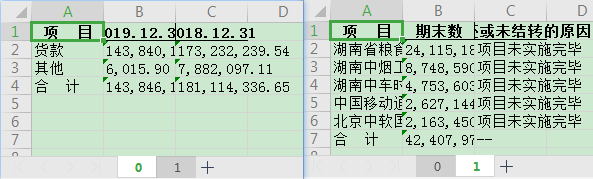
经过上面代码处理,就将这样一个word文档:
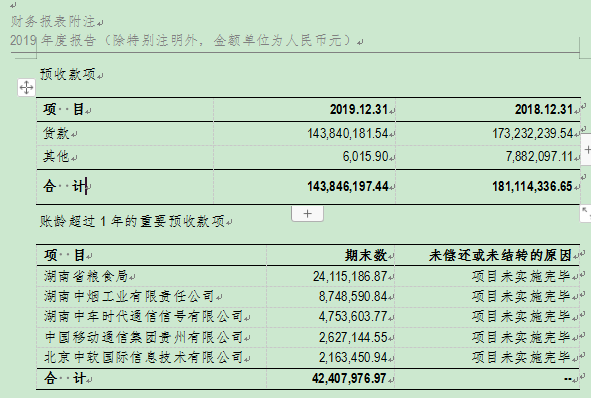
提取出来了这样的一个excel文件:
整体效果已经达到,但是我觉得如果能顺便设置好列宽就好看点,要设置好列宽,我的思路是计算出每列的字符串的最大长度,但不能直接用字符长度,每个中文字符会占用两个长度,所以我直接取gbk编码后的字节长度:
from docx import Document
import pandas as pd
import numpy as np
doc = Document(r"test.docx")
writer = pd.ExcelWriter("test.xlsx")
workbook = writer.book
for i, table in enumerate(doc.tables):
header = [cell.text for cell in table.rows[0].cells]
result = []
for row in table.rows[1:]:
tmp = []
for cell in row.cells:
tmp.append(cell.text)
result.append(tmp)
df = pd.DataFrame(result, columns=header)
df.to_excel(writer, sheet_name=f"{i}", index=False)
worksheet = writer.sheets[f"{i}"]
# 计算表头的字符宽度
column_widths = (
df.columns.to_series()
.apply(lambda x: len(x.encode('gbk'))).values
)
# 计算每列的最大字符宽度
max_widths = (
df.astype(str)
.applymap(lambda x: len(x.encode('gbk')))
.agg(max).values
)
# 计算整体最大宽度
widths = np.max([column_widths, max_widths], axis=0)
for i, width in enumerate(widths):
worksheet.set_column(i, i, width)
writer.save()
结果:
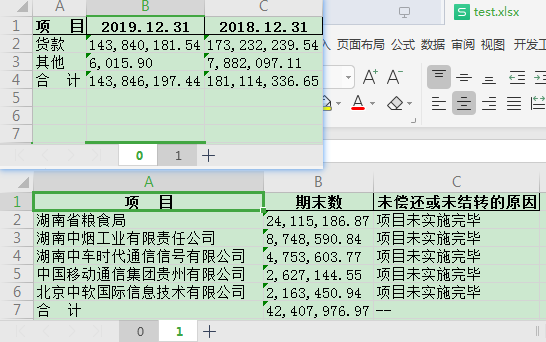
有了一个合适的列宽,我看的舒服多了,至少我自己是满意了,要用代码加什么好看的样式也简单。
好了,现在开始处理需求2:
读取修改过的excel回填到word文档中
读取word并生成word模板
要回填到word文档中,我们应该事先生成能够被doctpl解析的模板,我的思路是每个表格除了表头以外全部删除,然后动态生成以下格式的模板:
| xxx | xxx | xxx |
|---|---|---|
| {%tr for cells in rows0 %} | ||
| {{ cells[0] }} | {{ cells[1] }} | {{ cells[2] }} |
| {%tr endfor %} | ||
| {{ footers0[0] }} | {{ footers0[1] }} | {{ footers0[2] }} |
到时候再直接根据excel的数据渲染就行,那么如何生成word模板呢?
直接看看我的代码吧:
from docx import Document
def set_font_style(after_font_style, before_font_style):
after_font_style.bold = before_font_style.bold
after_font_style.italic = before_font_style.italic
after_font_style.underline = before_font_style.underline
after_font_style.strike = before_font_style.strike
after_font_style.shadow = before_font_style.shadow
after_font_style.size = before_font_style.size
after_font_style.color.rgb = before_font_style.color.rgb
after_font_style.name = before_font_style.name
doc = Document("test.docx")
for i, table in enumerate(doc.tables):
# 缓存最后一行的行对象
last_row = table.rows[-1]._tr
# 删除除表头外的所有行
for row in table.rows[1:]:
table._tbl.remove(row._tr)
# 表格添加一行,第一个单元格文本指定为指定的内容
table.add_row().cells[0].text = '{%tr for cells in rows'+str(i)+' %}'
# 再添加一行用于保存中间的模板
row = table.add_row()
for j, cell in enumerate(row.cells):
cell.text = '{{ cells[%d] }}' % j
# 再添加一行用于保存endfor模板
table.add_row().cells[0].text = '{%tr endfor %}'
# 将直接缓存的最后一行添加到行尾
table._tbl.append(last_row)
# 表格的行尾修改完样式后,还原回以前的样式
for j, cell in enumerate(table.rows[-1].cells):
before_font_style = cell.paragraphs[0].runs[0].font
cell.text = '{{ footers%d[%d] }}' % (i, j)
after_font_style = cell.paragraphs[0].runs[0].font
set_font_style(after_font_style, before_font_style)
doc.save("test_template.docx")
模板生成的效果:
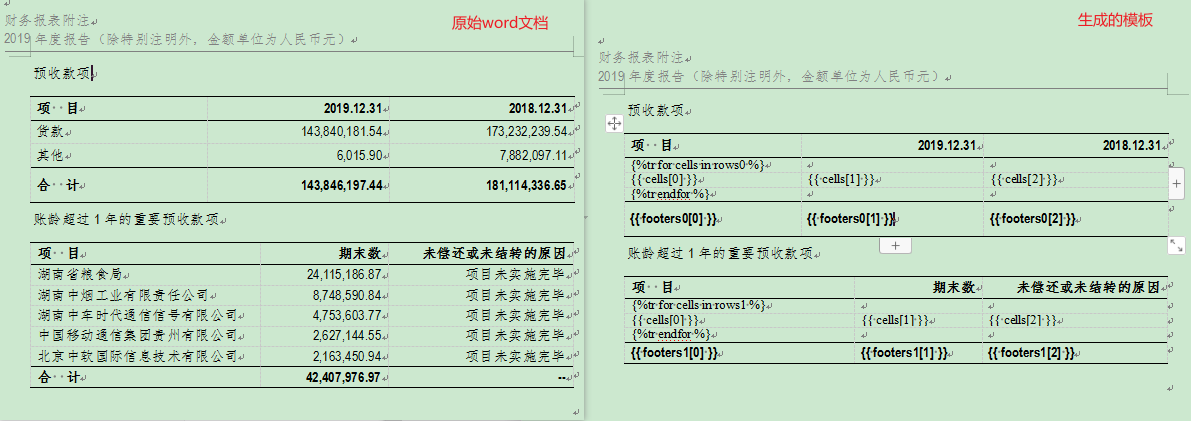
根据word模板回填word
有了模板就可以开始根据模板回填word了,首先我把excel修改成这样:
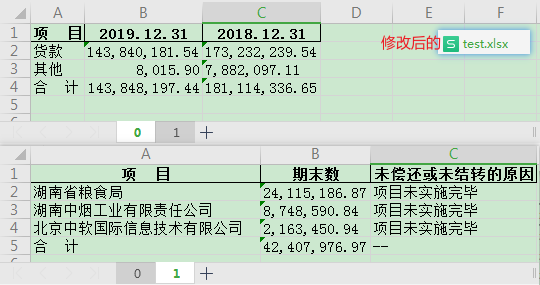
就是一个表改了两个值,另一个表删了两行,保存后,执行以下代码:
from docxtpl import DocxTemplate
import pandas as pd
tpl = DocxTemplate('test_template.docx')
excel = pd.ExcelFile("test.xlsx")
context = {}
for sheet_name in excel.sheet_names:
data = pd.read_excel(excel, sheet_name).values
context[f'rows{sheet_name}'] = data[:-1].tolist()
context[f'footers{sheet_name}'] = data[-1].tolist()
tpl.render(context)
tpl.save('result.docx')
回填结果:
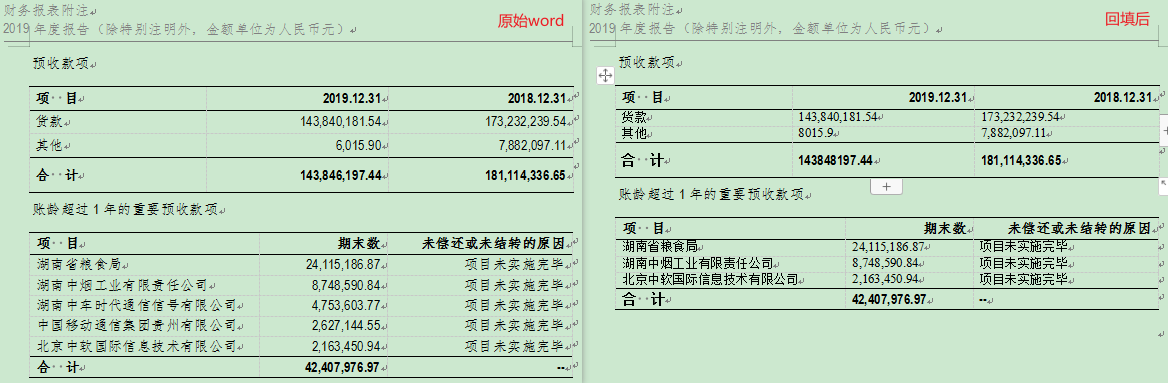
好了,到现在为止,我个人觉得已经大体上完成效果了。当然还不够完美,很多样式适配都还没有去做,首先是行高丢失,然后是修改数值后的千分符丢失,这都要等正式开发后去适配,我这里不公布正式开发的代码。
总结
你对doctpl怎么看呢?欢迎你在下方评论或留言表达你的看法。