前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
环境:
macOS10.12.3
Python2.7
Scrapy1.3.3
一、软件(python)、框架(scrapy)的安装
mac自带Python,根据Scrapy官网建议,最好下载最新的Python版本安装
1、安装pip工具包的支撑环境
各个电脑的情况不一样,支撑包的情况也不一样,反正一句话:缺什么就装什么,我采用Homebrew
2、pip源修改(镜像地址)
这个一定要做,默认地址访问速度特别慢,FQ了都很慢,最后我的总结是:有一半的时间都是因为这个原因导致的
首先创建配置文件,默认情况下Mac端好像是没有pip的配置文件的,我们需要自行创建。
打开终端,在HOME下创建.pip目录:
echo $HOME
mkdir .pip
接下来创建配置文件pip.conf:
touch pip.conf
接下来编辑配置文件,随便使用什么编辑器打开刚刚新建的pip.conf文件,输入以下两行:
[global]
index-url = http://pypi.mirrors.ustc.edu.cn/simple
输入完成后保存退出即可,至此,pip源就修改完了
国内的镜像较多,参考:http://it.taocms.org/08/8567.htm、http://www.jianshu.com/p/a03aab073a35哪个行就用哪个
3、HOME目录进行Command Line Tools安装,终端下执行
xcode-select--install
4、安装Scrapy,
终端执行pip install Scrapy
如果提示失败,自行看失败原因,例如跟six有关,就升级six包:sudo pip install six
通过pip你可以安装、升级大部分支撑包,简单一句:缺哪个就安装哪个包,哪个包版本不对,就升级哪个。这里有Scrapy依赖包的关系和版本:https://pypi.python.org/pypi/Scrapy/1.3.3,链接根据需要访问不同的Scrapy版本页面
我遇到的另一个问题主要是Scrapy需要支撑包版本问题,和终端账户问题。建议多尝试,采用root账户统一安装
二、编写爬虫爬取mzitu全站图片:
Scrapy官方文档和http://cuiqingcai.com/4421.html写的很清楚了,我就不班门弄斧,直接贴出代码:
run.py,运行程序:
fromscrapy.cmdlineimport execute
execute(['scrapy','crawl','mzitu'])
items.py:用来定义Item有哪些属性
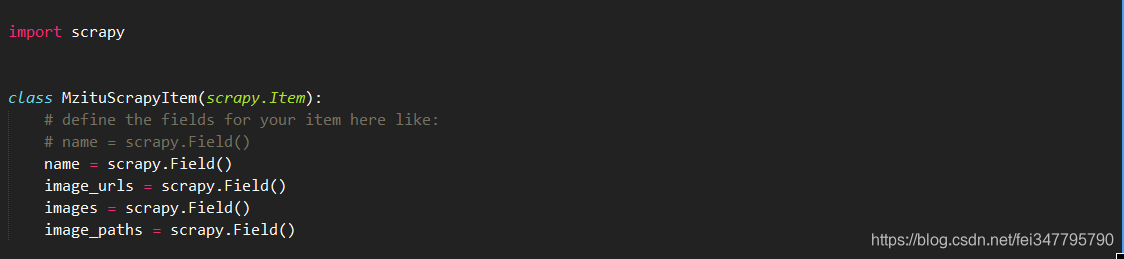
pipelines.py
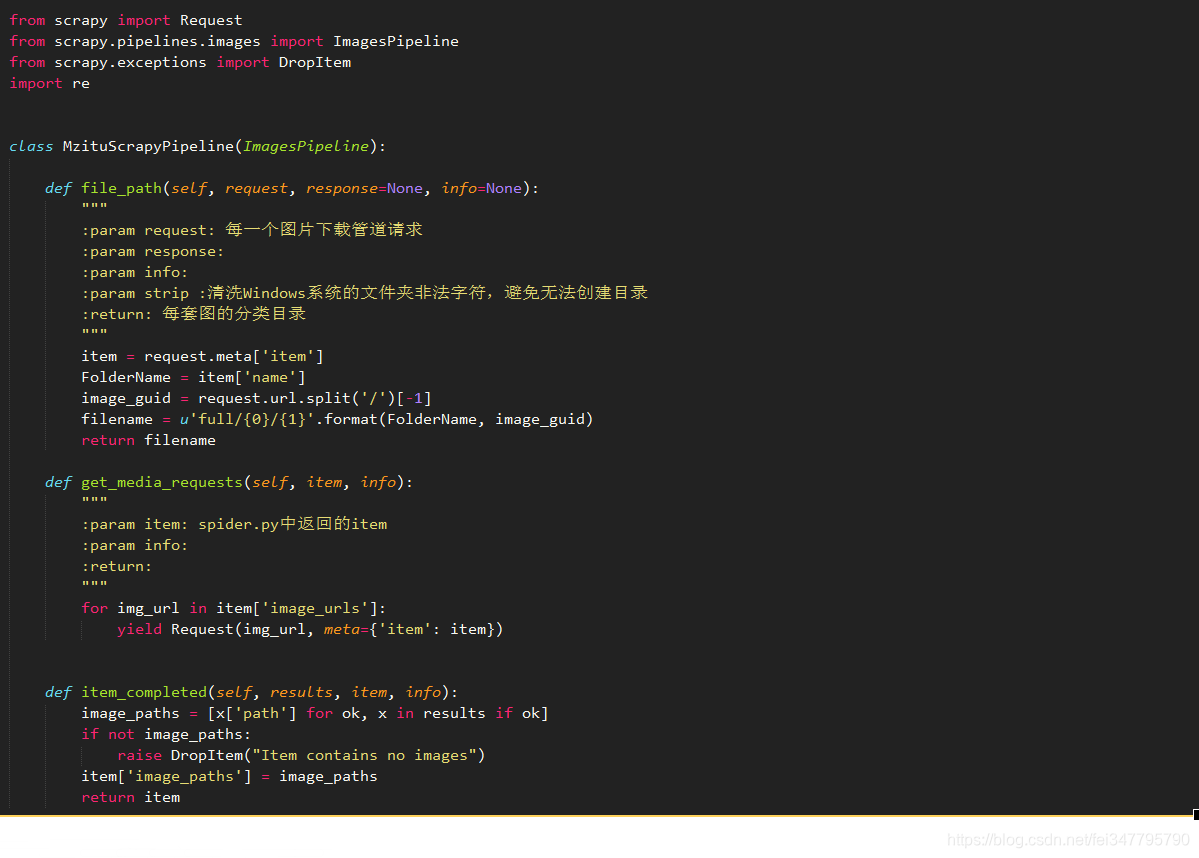
settings.py,项目设置文件:
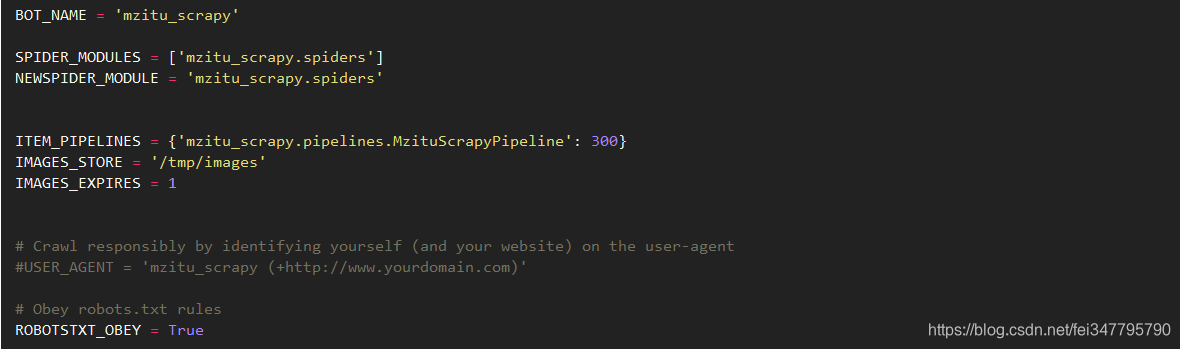
spider.py,主程序:
项目结构如下:
最后终端进入项目目录,执行:
python run.py crawl mzitu_scrapy
如果遇到问题多找百度答案,坑还是不少的
我这里提几点:
1、Scrapy是默认给文件按照hash来命名的,想要文件原来的名字就覆写file_path方法,网络上写的覆写方法完全没有问题
2、如果想给文件归类放不同的文件夹怎么办?所谓文件夹不过是路径而已,一样是修改file_path,只不过要给n个文件写入同一个文件夹,我的思路就是一个item[name]对应n个文件,该name就是文件夹名称。注意http://cuiqingcai.com/4421.html的主程序是错的,文件夹名称和文件根本对不上,有严重的逻辑问题。为了这个问题我找了好久答案,一直都以为是覆写file_path方法的思路是错的,最后才发现原来主程序中name和文件对不上导致的
3、xpath语法可以上http://www.w3school.com.cn/xpath/index.asp现学,不难,可以结合chrome的一个xpath插件(xpath helper)在按照xpath语法修改(我基本是用该插件来验证写的语句对不对)
最后,如果你因为防火墙的问题,纠结上不了chrome应用商店,安装不了xpath helper。想办法FQ即可。