网易云音乐网页版API接口
前缀(主域名):http://music.163.com
1.1 获取歌词
- 请求地址:/api/song/lyric?id=xxxxx&lv=1&kv=1&tv=-1
- 请求参数:id:获取歌词对应的歌曲id
1.2 下载歌曲
- 请求地址:/song/media/outer/url?id=xxxx.mp3
- 请求参数:id:获取歌词对应的歌曲id
获取音乐信息
2.1 类封装音乐信息
class Musci_info(object):
def __init__(self, id):
self.id = id
2.2 获取音乐信息
图例分析


核心代码
'''
小编准备的python学习资料,加群:1136201545 即可免费获取!
'''
def get_music_info(self):
url = "https://music.163.com/#/artist?id={0}".format(self.id)
driver.get(url)
'''
frame标签有frameset、frame、iframe三种,frameset跟其他普通标签没有区别,不会影响到正常的定位,而frame与iframe对selenium定位而言是一样的,selenium有一组方法对frame进行操作。
driver.switch_to.frame() # 切到iframe里面
driver.switch_to.parent_frame() # 切回父级
driver.switch_to.default_content() # 切回主文档
'''
driver.switch_to.frame('contentFrame')
# 切到iframe里面,可以根据id或name值来定位,这里是根据name值定位,看上述图1
artist_name = driver.find_element_by_id('artist-name').text
print(artist_name)
path = os.getcwd() + "\\data\\{0}".format(artist_name)
# 在当前工作路径下创建一个/data/歌手名字文件夹,例如:...../data/薛之谦
# 调用os模块判断是否存在
if not os.path.exists(path):
os.makedirs(path)
# 找到歌手所有的歌曲,find_element...是找到了当前html标签,然后find_elements...多了个s,这里返回一个包含多个歌曲信息的list,每个list里面有多个tr标签。一个tr对应一个歌曲,看上述图2
tr_list = driver.find_element_by_id("hotsong-list").find_elements_by_tag_name("tr")
music_info = []
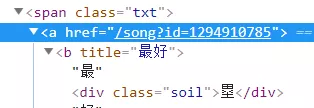
# 对每个tr标签进行遍历,寻找对应信息的标签内容,把音乐的名字及链接找出来,看上述图3
for i in range(len(tr_list)):
content = tr_list[i].find_element_by_class_name('txt')
href = content.find_element_by_tag_name('a').get_attribute('href')
title = content.find_element_by_tag_name('b').get_attribute('title')
music_info.append((title, href))
# 返回音乐信息及当前歌手的路径地址
return music_info, path
信息本地存储
核心代码
# 注意这里head的作用就是定义列的字段
def save_csv(self, music_info, path, head=None):
# 将音乐信息存储到 .../data/歌手/ 目录下面,并以xx.csv存储
data = pd.DataFrame(music_info, columns=head)
# index=False去掉DataFrame默认的index列
data.to_csv("{0}/singer{1}.csv".format(path, str(self.id)), encoding="utf-8", index=False)
运行结果

下载音乐及歌词
类封装下载
class Download_Music(object):
# 初始化上述的歌曲名字,id,及存储的路径
def __init__(self, music_name, music_id, path):
self.music_name = music_name
self.music_id = music_id
self.path = path
下载歌词
图例分析


核心代码
def get_lyric(self):
# 根据前面的歌词api设置
url = 'http://music.163.com/api/song/lyric?' + 'id=' + str(self.music_id) + '&lv=1&kv=1&tv=-1'
r = requests.get(url)
raw_json = r.text
ch_json = json.loads(raw_json)
raw_lyric = ch_json['lrc']['lyric']
# 正则去除[]及里面的时间...
del_str = re.compile(r'\[.*\]')
# re.sub共有五个参数。其中三个必选参数:pattern, repl, string,两个可选参数:count, flags
ch_lyric = re.sub(del_str, '', raw_lyric) # 实现正则的替换
return ch_lyric
下载歌曲
def download_mp3(self):
# 定义url,请求的api
url = 'http://music.163.com/song/media/outer/url?id=' + str(self.music_id) + '.mp3'
try:
print("正在下载:{0}".format(self.music_name))
# 通过urllib.request.urlretrieve进行下载歌曲
urllib.request.urlretrieve(url, '{0}/{1}.mp3'.format(self.path, self.music_name))
print("Finish...")
except:
print("Failed...")
实现
实现关键点一:提取歌曲id
方法一:
re.search 匹配包含
link = re.search(regex, mu['link']).group()
匹配后为id=1294910785,前面都为id=刚好3位,index从0开始,
也就是说[3:]即为所需要的id数据。
# .*是贪婪模式 尽可能多的匹配数据
regex = re.compile(r'id=.*') # .*贪婪模式匹配
link = re.search(regex, mu['link']).group()[3:]
或者采用以下分组解决
方法二:
regex = re.compile(r'(id)(=)(.*)')
link = re.search(regex, mu['link']).group() # id=1294910785
link = re.search(regex, mu['link']).group(0) # id=1294910785
link = re.search(regex, mu['link']).group(1) # id
link = re.search(regex, mu['link']).group(2) # =
link = re.search(regex, mu['link']).group(3) # 1294910785
也就是说直接使用
regex = re.compile(r'(id)(=)(.*)')
link = re.search(regex, mu['link']).group(3)
便可以实现获取id的效果了
实现关键点二:pandas读取数据引擎设置
由于此处文件夹命名有可能带中文,所以在mu_info=pd.read_csv()
这行代码中,容易出现问题。原因是调用pandas的read_csv()方法时,
默认使用C engine作为parser engine,而当文件名中含有中文的时候,
就会报错,这里一定要设置engine为python,即engine=‘python’
封装实现
def main(id):
singer_id = id
# 歌手id,自定义修改--根据自己爬取的歌手选择
mu_info = Musci_info(singer_id)
# 类初始化
music_info, path = mu_info.get_music_info()
# 调用方法,获取音乐信息及路径
print(music_info)
print(path)
mu_info.save_csv(music_info, path, head=['music', 'link'])
# 存储音乐的歌名及链接至csv文件
'''
'''
mu_info = pd.read_csv('{0}/singer{1}.csv'.format(path, str(singer_id)), engine='python', encoding='utf-8')
'''
通过iterrows遍历音乐信息的music文件
iterrows返回的是一个元组(index,mu)
'''
for index, mu in mu_info.iterrows():
music = mu['music'] # 取对应的歌曲
# 通过正则取出歌曲对应的链接中的id
regex = re.compile(r'(id)(=)(.*)')
print('--------------------')
link = re.search(regex, mu['link']).group(3)
print('--------------------')
print(link)
music = Download_Music(music, link, path)
music.save_txt()
music.download_mp3()
调用呈现
手动获取歌手id
调用代码
if __name__ == '__main__':
main(5781) # 填写歌手的id即可!
运行结果
