爬虫的基本思路
1、在前程无忧官网检索“大数据”的结果中,每条检索结果详情对应的URL存在a标签的href属性中,通过组合选择器可以找到每条检索结果详情的URL。
2、前程无忧的招聘岗位信息数据固定的放在HTML的各个标签内,通过id选择器、标签选择器和组合选择器可以诸如公司名、岗位名称和薪资等11个字段的数据。
3、基于上述1和2,可以通过解析检索“大数据”得到的URL得到其HTML,再从此HTML中的具体位置的a标签得到每个岗位的详情对应的URL;然后解析每个岗位的详情对应的URL得到其HTML,再从结果HTML的具体位置找到每个岗位的详情。具体位置怎么确定呢?通过组合选择器!
前程无忧爬虫具体代码
SpiderOf51job.py
import requests
from lxml import etree
import csv
import time
import random
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
fp = open('51job.csv', 'wt', newline='', encoding='GBK', errors='ignore')
writer = csv.writer(fp)
'''title,salary,company,companyinfo,companyplace,place,exp,edu,num,time,info'''
writer.writerow(('职位', '薪资', '公司', '公司信息', '公司地址', '地区', '工作经验', '学历', '人数', '时间', '岗位信息'))
def parseInfo(url):
headers = {
'User-Agent': 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/ADR-1301071546) Presto/2.11.355 Version/12.10'
}#更换请求头,防止被反爬虫
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
selector = etree.HTML(res.text)
title = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/p/text()')
salary = selector.xpath('//*[@id="pageContent"]/div[1]/p/text()')
company = selector.xpath('//*[@id="pageContent"]/div[2]/a[1]/p/text()')
companyinfo = selector.xpath('//*[@id="pageContent"]/div[2]/a[1]/div/text()')
companyplace = selector.xpath('//*[@id="pageContent"]/div[2]/a[2]/span/text()')
place = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/em/text()')
exp = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[2]/text()')
edu = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[3]/text()')
num = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[1]/text()')
time = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/span/text()')
info = selector.xpath('string(//*[@id="pageContent"]/div[3]/div[2]/article)')
#类选择器解析URL中对应HTML对应的字段内容
info = str(info).strip()
print(title, salary, company, companyinfo, companyplace, place, exp, edu, num, time, info)
writer.writerow((title, salary, company, companyinfo, companyplace, place, exp, edu, num, time, info))
def getUrl(url):
print('New page')
res = requests.get(url)
res.encoding = 'GBK'
# print(res.text)
if res.status_code == requests.codes.ok:
selector = etree.HTML(res.text)
urls = selector.xpath('//*[@id="resultList"]/div/p/span/a/@href')
# //*[@id="resultList"]/div/p/span/a
# id选择器找到当前网页每一个职位a标签对应的当前岗位具体信息URL列表
print(urls)
for url in urls:
parseInfo(url)
time.sleep(random.randrange(1, 4))
#设置线程休眠时间防止被反爬虫
if __name__ == '__main__':
key = '大数据'
# 第一页URL格式和后面的网页不一样
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,' + key + ',2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
getUrl(url)
# 后页[2,100)
urls = [
'https://search.51job.com/list/000000,000000,0000,00,9,99,' + key + ',2,{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(
i) for i in range(2, 100)]
for url in urls:
getUrl(url)
爬虫结果
爬虫结果我是以csv的格式存储的,看起来不太直观,所以我打算用wordcloud和直方图来可视化爬虫的结果。
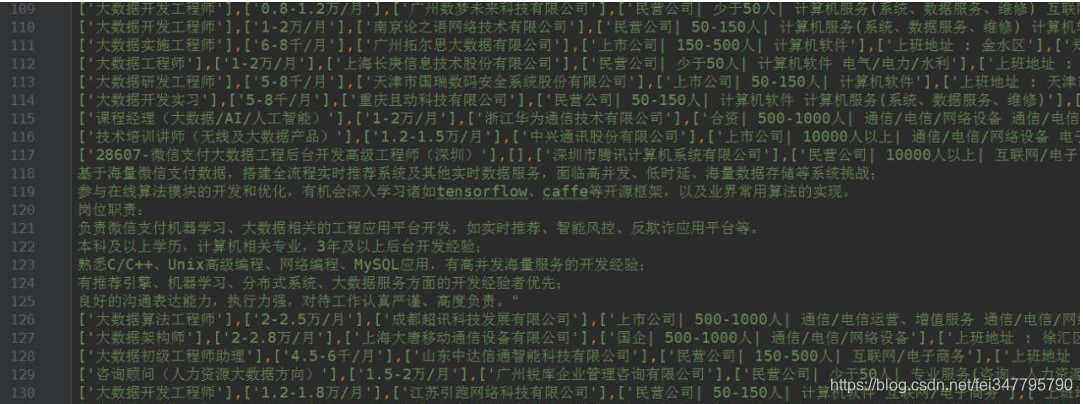
爬虫结果处理
一般来说,应聘者对一个工作的地点、工作名称、薪资和需要的技术最为关心,刚好上述爬虫的结果包含了这四个字段。
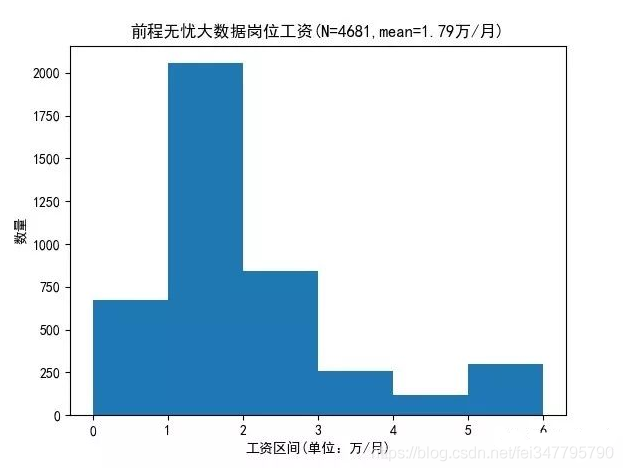
1、薪资结果的处理。在爬虫结果中,薪资在第二列,一般是诸如“1-2万/月”、“20万/年”和“500/天”的结果,先判断每个结果的最后一个字符是“年”、“月”和“天”的哪一个,确定处理的逻辑之后,再用re.sub函数将除了数字之外的字符替换为空格,最后对结果求均值就到了了每个结果的均值。
wordcloudPlotSalary.py
import re
import matplotlib.pyplot as plt
import csv
import numpy as np
data = []
with open("51job.csv",encoding='gbk') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
data_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到data中
data.append(row)
data = np.array(data) # 将list数组转化成array数组便于查看数据结构
header = np.array(data_header)
Jobinfo=data[:,10];
Salary=data[:,1];
name=data[:,0];
place=data[:,5];
word="".join(Salary);
font=r'C:\\Windows\\fonts\\msyh.ttf'#显示中文的关键步骤
# 去掉英文,保留中文
resultword=re.sub("[A-Za-z\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\<\>\?\~\。\@\#\\\&\*\%]", " ",word)
# 现在去掉了中文和标点符号
wl_space_split = resultword
salary_info=wl_space_split.split();
salary_list=[];
for s in salary_info:
if(s[-1])=="年":
ans=re.sub("[\u4e00-\u9fa5A-Za-z\/\-]", " ",s).split()
sum=0;
for i in ans:
sum+=float(i)
avg=sum/len(ans)/12
elif (s[-1])=="月":
ans = re.sub("[\u4e00-\u9fa5A-Za-z\/\-]", " ", s).split()
sum=0;
for i in ans:
sum+=float(i)
avg=sum/len(ans)
elif (s[-1])=="天":
ans = re.sub("[\u4e00-\u9fa5A-Za-z\/\-]", " ", s).split()
sum=0;
for i in ans:
sum+=float(i)
avg=sum/len(ans)*30
salary_list.append(avg)
salary_array = np.array(salary_list)
salary_array[salary_array>6]=-0.00001 #剔除大于6的异常数据或者不合实际的数据
plt.rcParams['font.sans-serif']=['SimHei']
plt.hist(salary_array, bins = [0,1,2,3,4,5,6])
plt.xlabel("工资区间(单位:万/月)") #设置X轴Y轴名称
plt.ylabel("数量")
plt.title("前程无忧大数据岗位工资(N="+str(len(salary_array))+",mean="+ str(round(salary_array.mean(),2))+ "万/月)")
plt.savefig('salaryHist.jpg')
plt.show();
2、需要的技术的处理。考虑到大数据要使用的技术绝大多数由外国人开发,如实我把大数据要使用的技术这一字段的中文全部替换为空格,然后用jieba提出掉一些无意义的助词,就得到了大数据要使用的技术的词云图。
wordcloudPlotJobinfo.py
import re
import jieba
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
import matplotlib.pyplot as plt
import csv
import numpy as np
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
data = []
with open("51job.csv",encoding='gbk') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
data_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
data.append(row)
data = np.array(data) # 将list数组转化成array数组便于查看数据结构
header = np.array(data_header)
Jobinfo=data[:,10];
Salary=data[:,1];
name=data[:,0];
place=data[:,5];
word="".join(Jobinfo);
font=r'C:\\Windows\\fonts\\msyh.ttf'#显示中文的关键步骤
# 去掉英文,保留中文
resultword=re.sub("[0-9\u4e00-\u9fa5\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%\-]", "",word)
# 现在去掉了中文和标点符号
wordlist_after_jieba = jieba.cut(resultword)
wl_space_split = " ".join(wordlist_after_jieba)
print(wl_space_split);
# 设置停用词
sw = set(STOPWORDS)
sw.add(",")
sw.add(";")
sw.add("Responsibilities")
sw.add("experience")
sw.add("knowledge")
sw.add("communication")
sw.add("skill")
sw.add("office")
sw.add("support")
# 关键一步
my_wordcloud = WordCloud(font_path=font,scale=4,stopwords=sw,background_color='white',
max_words = 100,max_font_size = 60,random_state=20).generate(wl_space_split)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片
my_wordcloud.to_file('Jobinfo.jpg')

3、工作地点和职位名称的处理
wordcloudPlotPlace.py
import numpy as np
from PIL import Image
import re
import jieba
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
# import wordcloud
import matplotlib.pyplot as plt
import csv
import numpy as np
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
data = []
with open("51job.csv",encoding='gbk') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
data_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
data.append(row)
data = np.array(data) # 将list数组转化成array数组便于查看数据结构
header = np.array(data_header)
Jobinfo=data[:,10];
Salary=data[:,1];
name=data[:,0];
place=data[:,5];
# 打开存放项目名称的txt文件
# with open('content.txt','r',encoding='utf-8') as f:
# word= (f.read())
# f.close()
str="";
word=str.join(place);
# 图片模板和字体
# image=np.array(Image.open('ditu.jpg'))#显示中文的关键步骤
font=r'C:\\Windows\\fonts\\msyh.ttf'
# 去掉英文,保留中文
resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%\-]", "",word)
#resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%]", "",word)
# 现在去掉了中文和标点符号
wordlist_after_jieba = jieba.cut(resultword)
wl_space_split = " ".join(wordlist_after_jieba)
print(wl_space_split);
# 设置停用词
sw = set(STOPWORDS)
sw.add("研发")
sw.add("系列")
sw.add("区")
# 关键一步
my_wordcloud = WordCloud(font_path=font,scale=4,stopwords=sw,background_color='white',
max_words = 100,max_font_size = 60,random_state=20).generate(wl_space_split)
#my_wordcloud = WordCloud(background_color='white',
# width=800,height=600,margin=2).generate(wl_space_split)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片
my_wordcloud.to_file('place.jpg')

职位名称词云:
wordcloudPlotName.py
import re
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
import matplotlib.pyplot as plt
import csv
import numpy as np
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
data = []
with open("51job.csv",encoding='gbk') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
data_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
data.append(row)
data = np.array(data) # 将list数组转化成array数组便于查看数据结构
header = np.array(data_header)
Jobinfo=data[:,10];
Salary=data[:,1];
name=data[:,0];
place=data[:,5];
word="".join(name);
# 图片模板和字体
#image=np.array(Image.open('model.jpg'))#显示中文的关键步骤
font=r'C:\\Windows\\fonts\\msyh.ttf'
# 去掉英文,保留中文
resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%\-]", " ",word)
#resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%]", "",word)
# 现在去掉了中文和标点符号
#wordlist_after_jieba = jieba.cut(resultword)
wl_space_split = resultword;
print(wl_space_split);
# 设置停用词
sw = set(STOPWORDS)
sw.add("广州")
sw.add("沈阳")
sw.add("武汉")
sw.add("双休")
sw.add("(周末双休)")
sw.add("五险一金")
sw.add("上海")
sw.add("杭州")
sw.add("急招")
sw.add("北京")
sw.add("周末双休")
# 关键一步
my_wordcloud = WordCloud(font_path=font,scale=4,stopwords=sw,background_color='white',
max_words = 100,max_font_size = 60,random_state=20).generate(wl_space_split)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片
my_wordcloud.to_file('name.jpg')

总结
1、前程无忧上大数据相关岗位出现频率最高的是:大数据开发工程师
2、开出的平均工资:18K/月
3、大数据就业岗位最多的城市是:上海、广州和深圳、
4、大数据工作最吃香的技能是:Hadoop、SQL和Python