作者:周萝卜
警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系删除!!!
昨天爬了豆瓣上成龙出道以来的电影得分,发现大哥近些年电影水平确实有些下滑。今天再来搞猫眼,爬一爬猫眼上《龙牌之谜》的用户评论,看看这个口碑不佳的作品,用户的想法是怎么样的
分析猫眼网站
我们首先进入到猫眼,找到对应的电影,地址为:maoyan.com/films/34347页面拖到最下面,发现只有10条最热门的评论,其他评论去哪了?
浏览器手机模式
这里可以使用浏览器手机模式,在 Chrome 浏览器下,按 F12 打开开发者工具,再点击下图中的按钮,即可进入到手机模式
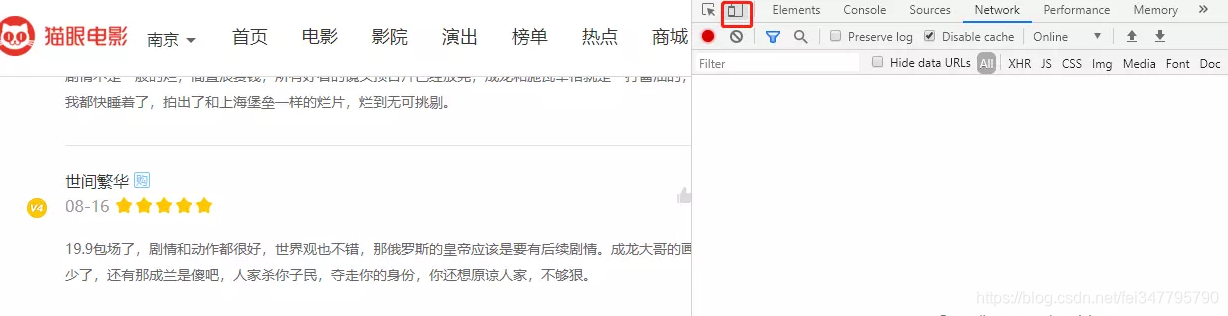
此时再重新刷新网页,发现我们已经神奇的进入到了猫眼的 M 站了
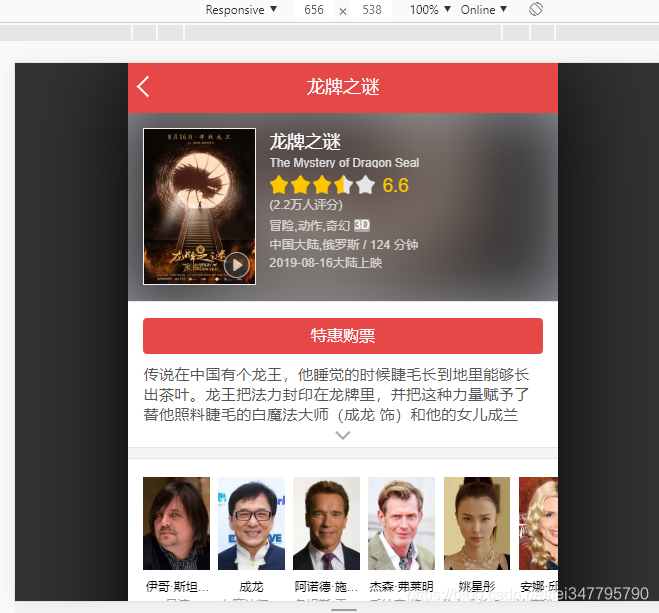
现在再拖动网页到最下部,点击查看全部评论,就可以进入到评论页面,查看全部的评论了。
寻找加载评论的接口
接下来我们继续下拉页面,发现评论是动态加载的。此时经验就非常重要了,我们让页面多加载加载评论几次,就能够发现一个“可疑”的请求,如下
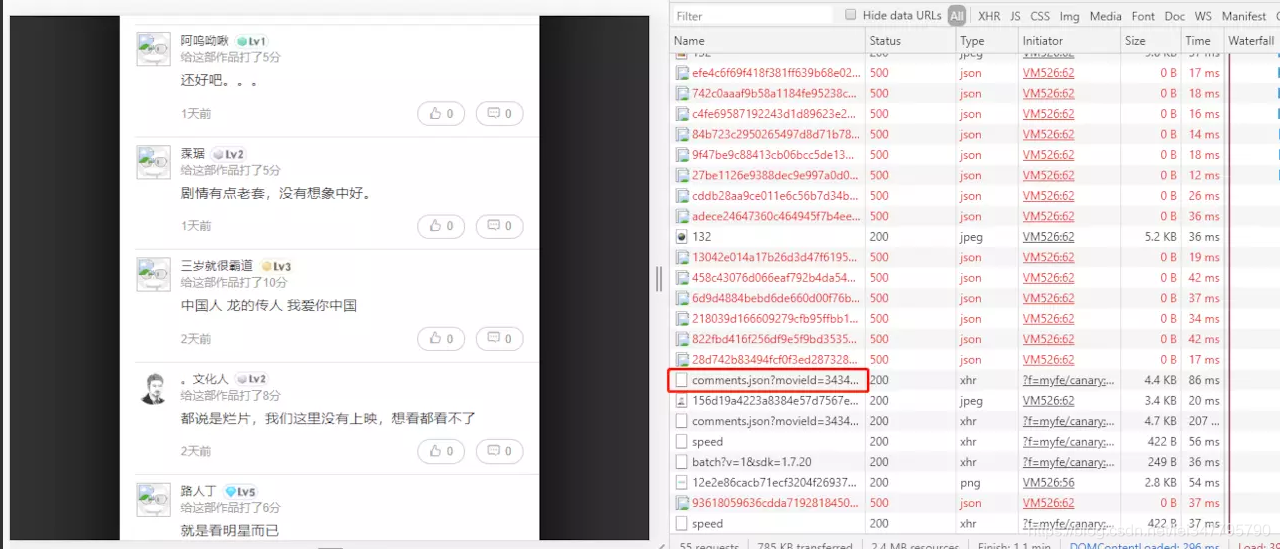
它是以 comments 命名的啊,差不多就是它了。
接下来再查看其 response,确实就是评论内容,而且是清爽的 json 数据,很开心!
分析接口参数
我们先来观察下这个接口
http://m.maoyan.com/review/v2/comments.json?movieId=343473&userId=-1&offset=30&limit=15&ts=1567064825883&type=3
- movieid 很显然就是电影的 id,不动
- userid 是 -1,应该是我们没有登陆的原因
- offset 经过尝试,相当于是 page 的作用,且每次的步长为 15
- limit 应该是每次返回数据的数量
其他参数暂时不明
我们把该接口信息放到 postman 中,尝试着调用下
我去掉了 movieid 以外的所有参数,发现是可以调用成功的
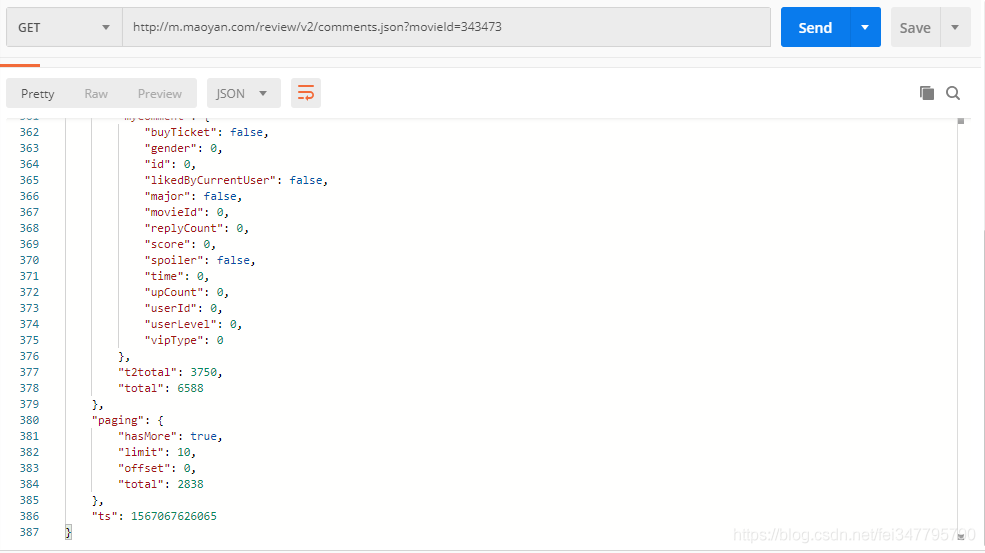
查看接口返回数据的最后面,发现一个 paging 字段
"paging": {
"hasMore": true,
"limit": 10,
"offset": 0,
"total": 2838
}
已经清楚的告诉了我们,还有更多数据(“hasMore”: true),每页限制为10(“limit”: 10),当前是第0页(“offset”: 0),总共的数据为2838条(“total”: 2838)。
最后经过测试,type = 3 会每次都会返回 hotComments 这个字段,而当 type = 2 时,则不会返回该字段,于是我选择使用 type 为2来发送请求,那么最终我决定使用的请求 url 就是如下:
http://m.maoyan.com/review/v2/comments.json?movieId=343473&offset=60&limit=15&type=2
offset 作为变量,循环替换即可。
编写爬虫代码
- 提取 json 数据
def get_json(res):
data_list = []
res_json = json.loads(res)
data = res_json['data']['comments']
for d in data:
content = d['content']
gender = d['gender']
userLevel = d['userLevel']
score = d['score']
try:
if len(d['tagList']) == 0:
ticket = 0
elif len(d['tagList']) == 1:
if d['tagList'][0]['id'] == 4:
ticket = 1
else:
ticket = 0
elif len(d['tagList']) == 2:
ticket == 1
except:
ticket = 0
tmp = [content, gender, userLevel, score, ticket]
data_list.append(tmp)
return data_list
解析 json 就比较简单了,只要做好异常处理即可。
因为评论中有很多 emoji 表情,可以使用正则过滤掉
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+", flags=re.UNICODE)
emoji_pattern1.sub(r'', str1)
最后保存数据到 csv 文件
def save_to_csv(data):
with open('maoyan_data.csv', 'w', encoding='utf-8') as f:
f.write('content,gender,userlevel,score,ticket\n')
for d in data:
try:
row = '{},{},{},{},{}'.format(d[0], d[1], d[2], d[3], d[4])
f.write(row)
f.write('\n')
except:
continue
最后得到的数据如下:

数据可视化分析
- 性别分布
我们先来看下评论者的性别分布式怎样的
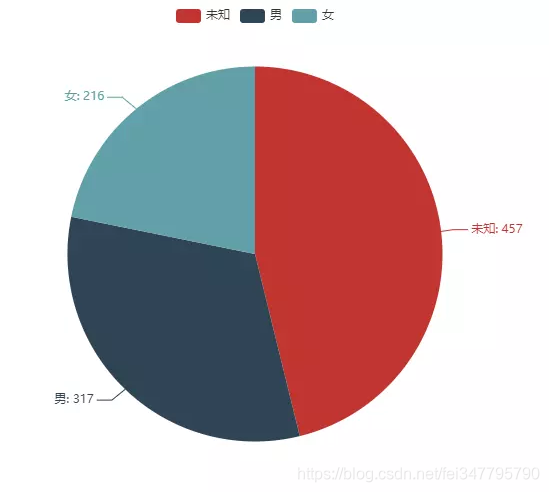
可以看出,男性观众的比例还是多一些,不过大多数都是每有设置性别,隐私工作做得很不多哦
-
用户等级
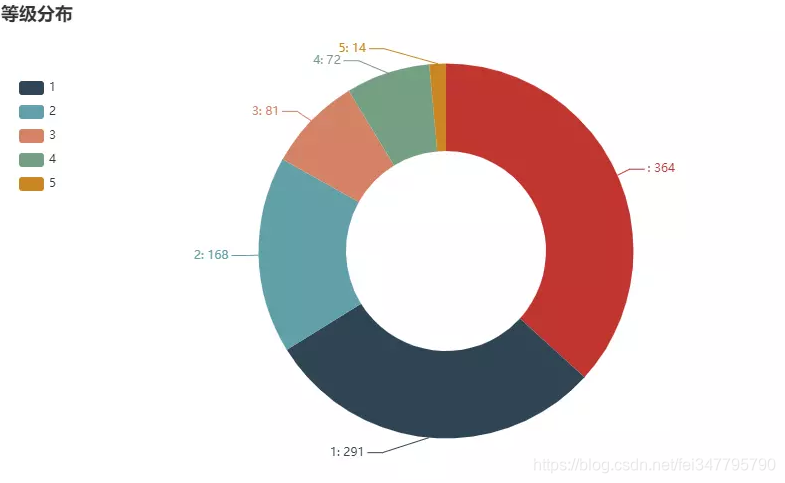
不出所料,大部分都是 level-0的用户,普通大众最普通,天下何止千千万。 -
评分分布
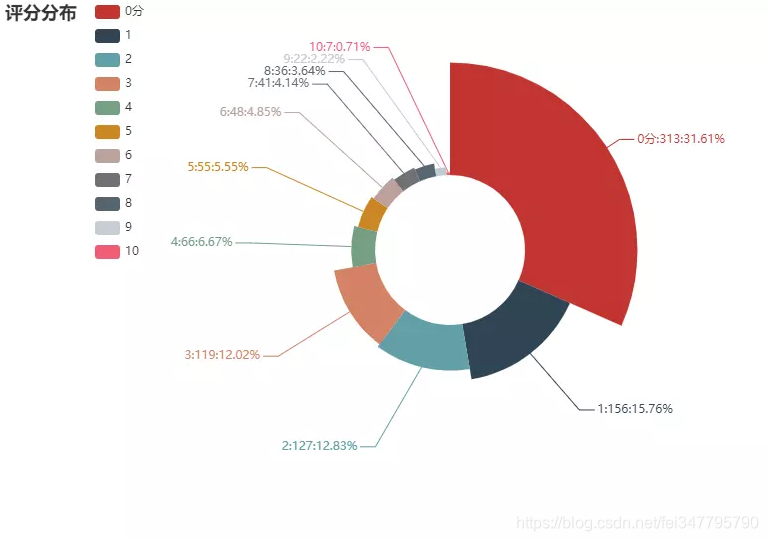
看到结果之后扎心不,打分数量最高的是0分,不知道如果可以打负分,那么情况会是怎么样
- 评论词云
最后,我们再来做一个词云,看看评论中的高频词汇都有哪些

老规矩,不对评论做过多点评 不过还是忍不住要说一句,评论里面“好看”这个词出现的频率还是非常高的,看评论里有人说是水军,拿钱了,不知道你怎么看呢
完整代码
- analyse.py
from pyecharts.charts import Pie
from pyecharts import options as opts
import pandas as pd
from wordcloud import WordCloud
import jieba
from PIL import Image
import numpy as np
'''
python学习交流群:1136201545更多学习资料可以加群获取
'''
font = r'C:\Windows\Fonts\FZSTK.TTF'
# STOPWORDS = set(map(str.strip, open('stopwords.txt', encoding='utf-8').readlines()))
def comment_wordcloud(data):
df_list = data['content'].tolist()
cut_word = "".join(jieba.cut(str(df_list), cut_all=False))
img = Image.open('ciyun.jpg')
img_array = np.array(img)
wc = WordCloud(width=1800, height=1500, background_color='white', font_path=font, mask=img_array)
wc.generate(cut_word)
wc.to_file('word.png')
def get_data():
data = pd.read_csv('maoyan_data.csv', encoding='utf-8')
return data
def gender_pie(data):
gender_list = []
for i, j in enumerate(data['gender'].value_counts()):
if i == 0:
i = '未知'
elif i == 1:
i = '男'
else:
i = '女'
gender_list.append([i, j])
pie = Pie()
pie.add("", gender_list)
pie.set_global_opts(title_opts=opts.TitleOpts(title="性别分布"))
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
pie.render("性别分布.html")
def level_pie(data):
level_list = [[i, j] for i, j in enumerate(data['userlevel'].value_counts())]
pie = Pie()
pie.add("", level_list, radius=["40%", "75%"])
pie.set_global_opts(
title_opts=opts.TitleOpts(title="等级分布"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_top="15%", pos_left="2%"
))
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
pie.render("等级分布.html")
def score_pie(data):
score_list = []
for i, j in enumerate(data['score'].value_counts()):
if i == 0:
i = '0分' # 当数据项名称为0时,不在图表中展示,这个疑为 echarts 的 bug
score_list.append([i, j])
pie = Pie()
pie.add("", score_list, radius=["30%", "75%"], center=["50%", "50%"], rosetype="radius")
pie.set_global_opts(
title_opts=opts.TitleOpts(title="评分分布"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_left="10%"
))
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}:{d}%"))
pie.render("评分分布.html")
if __name__ == '__main__':
data = get_data()
# gender_pie(data)
comment_wordcloud(data)
- main.py
import requests
import re
import time
import os
'''
python学习交流群:821460695更多学习资料可以加群获取
'''
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+", flags=re.UNICODE)
def fire():
page = 0
for i in range(15, 1200, 15):
print("开始爬取第 %s 页" % page)
url = 'http://m.maoyan.com/review/v2/comments.json?movieId=343473&offset={}&limit=15&type=2'.format(i)
res = requests.get(url).json()
if not res['paging']['hasMore']:
print("爬取完成")
break
data = get_json(res)
save_to_csv(data)
time.sleep(1)
page += 1
def get_json(res):
data_list = []
data = res['data']['comments']
for d in data:
content = d['content'].replace('\n', '').strip().replace(',', ',')
content = emoji_pattern.sub(r'', content)
gender = d['gender']
userLevel = d['userLevel']
score = d['score']
ticket = 0
try:
if len(d['tagList']) == 0:
ticket = 0
elif len(d['tagList']) == 1:
if d['tagList'][0]['id'] == 4:
ticket = 1
else:
ticket = 0
elif len(d['tagList']) == 2:
ticket == 1
else:
ticket = 0
except:
ticket = 0
tmp = [content, gender, userLevel, score, ticket]
data_list.append(tmp)
return data_list
def save_to_csv(data):
if not os.path.exists(r'maoyan_data.csv'):
with open('maoyan_data.csv', 'a+', encoding='utf-8') as f:
f.write('content,gender,userlevel,score,ticket\n')
for d in data:
try:
row = '{},{},{},{},{}'.format(d[0], d[1], d[2], d[3], d[4])
f.write(row)
f.write('\n')
except:
continue
else:
with open('maoyan_data.csv', 'a+', encoding='utf-8') as f:
for d in data:
try:
row = '{},{},{},{},{}'.format(d[0], d[1], d[2], d[3], d[4])
f.write(row)
f.write('\n')
except:
continue
if __name__ == '__main__':
fire()