前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
一、分析需求和网站结构
allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页。
要想得到书籍的详细信息和ISBN码,我们需要遍历所有的页码,进入到书籍列表,然后从书籍列表进入到每本书的详情页里,这样就能够抓取详情信息和ISBN码了。
二、从分页里遍历每一页书籍列表
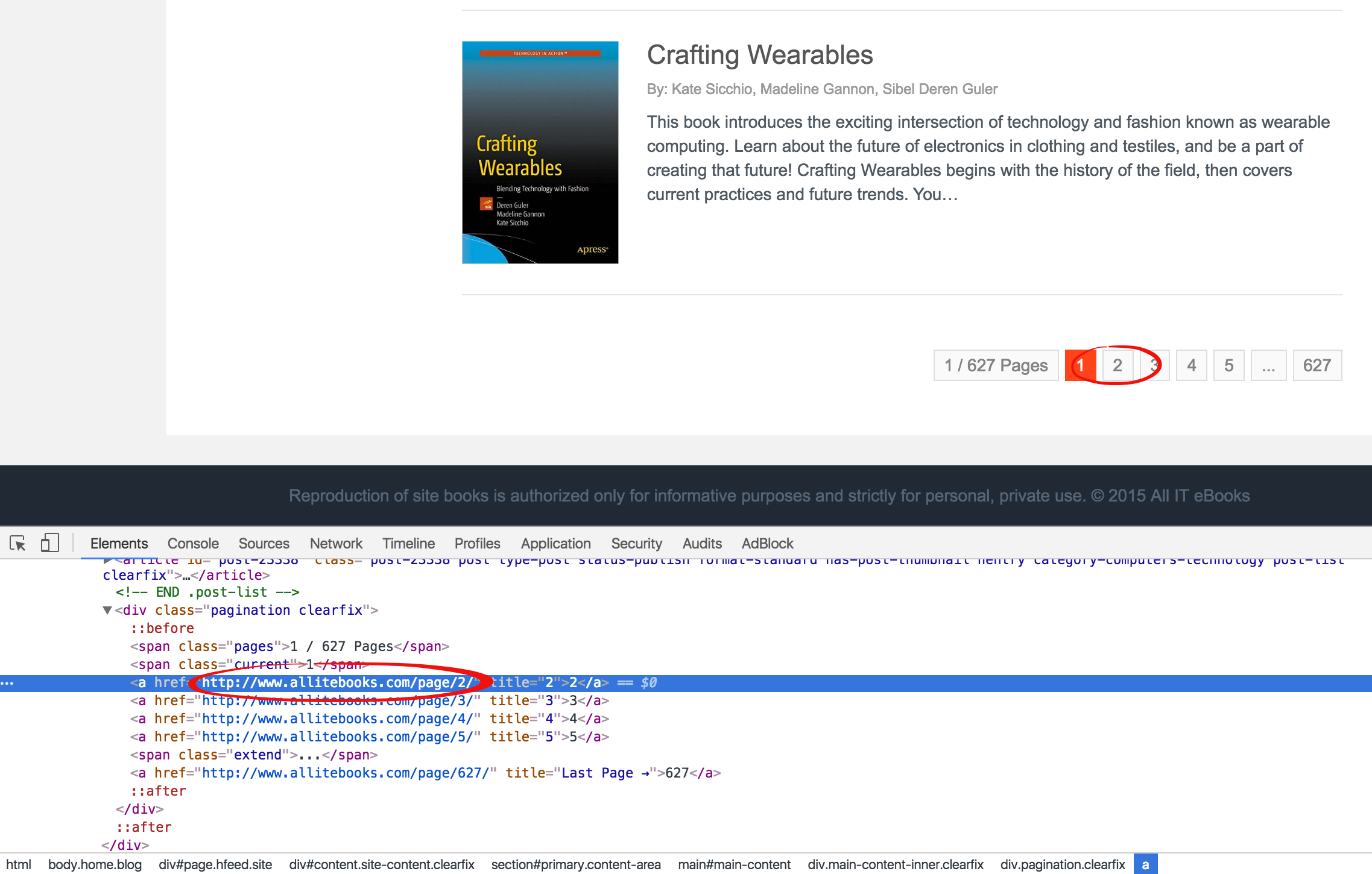
通过查看分页功能的HTML代码,通过class="current"可以定位当前页码所在span标签,此span标签的下一个兄弟a标签就是下一页链接所在的标签,
而通过对比最后一页的span可以发现,在最后一页中,通过class="current"找到的span标签却没有下一个兄弟a标签。所以我们可以通过这一点判断出是否已经到最后一页了。代码如下:

三、从书籍列表里找到详情页的链接
在书籍列表点击书名或者封面图都可以进入详情,则书名和封面图任选一个,这里选择书名。
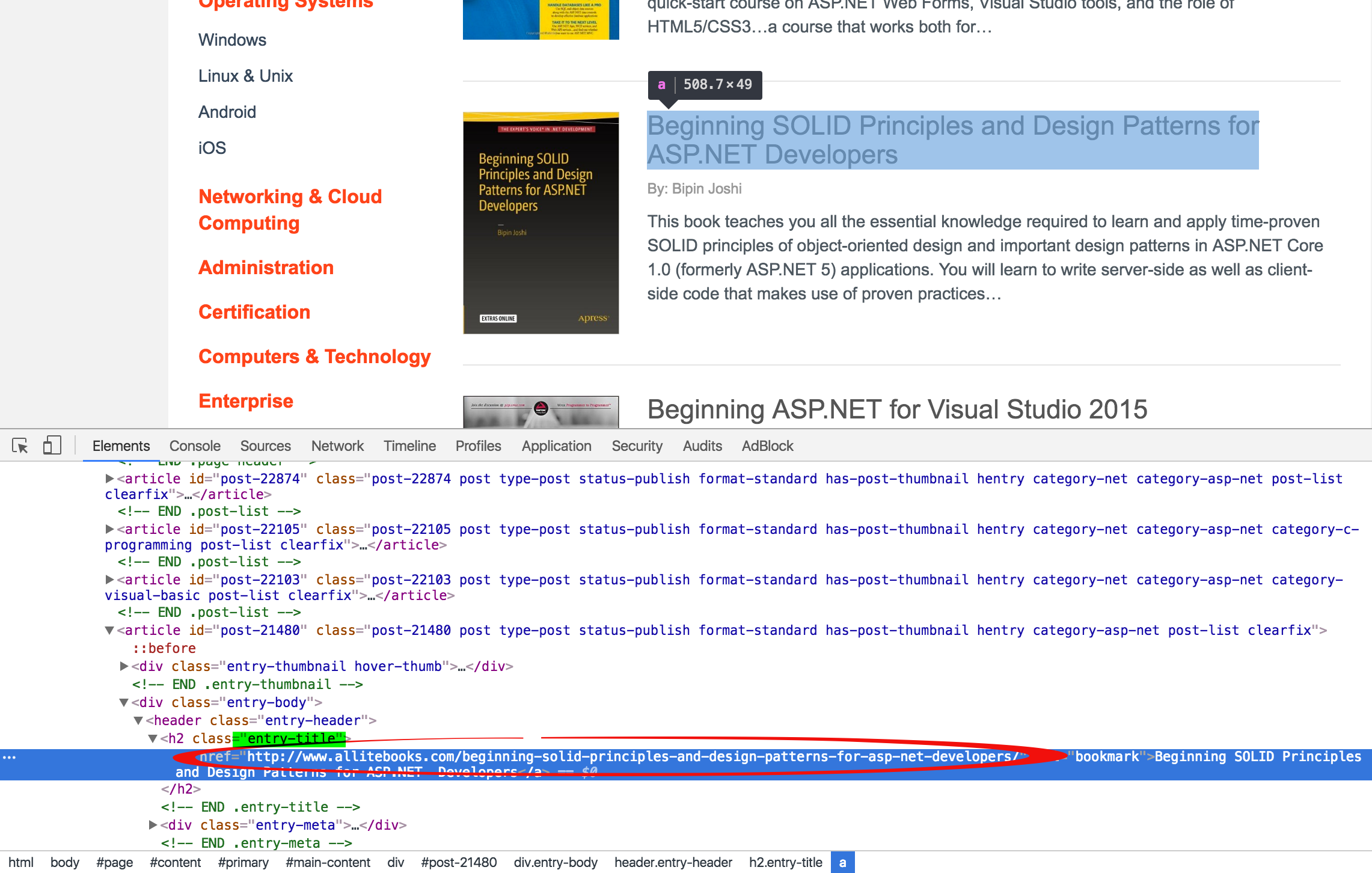
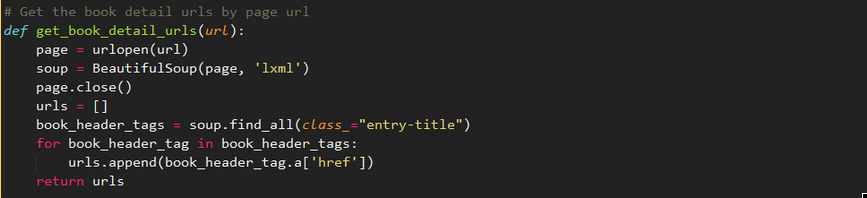
我们可以通过查找class="entry-title"定位到书名所在的h2标签,然后通过此标签的a属性即可获得链接所在的a标签,再通过a标签的string属性可得到链接。
代码如下:
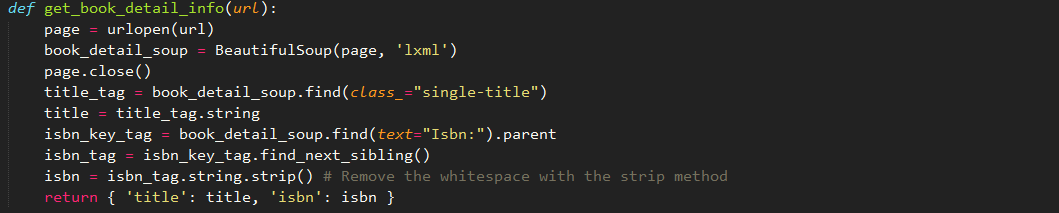
四、从书籍详情页里抓取标题和ISBN码
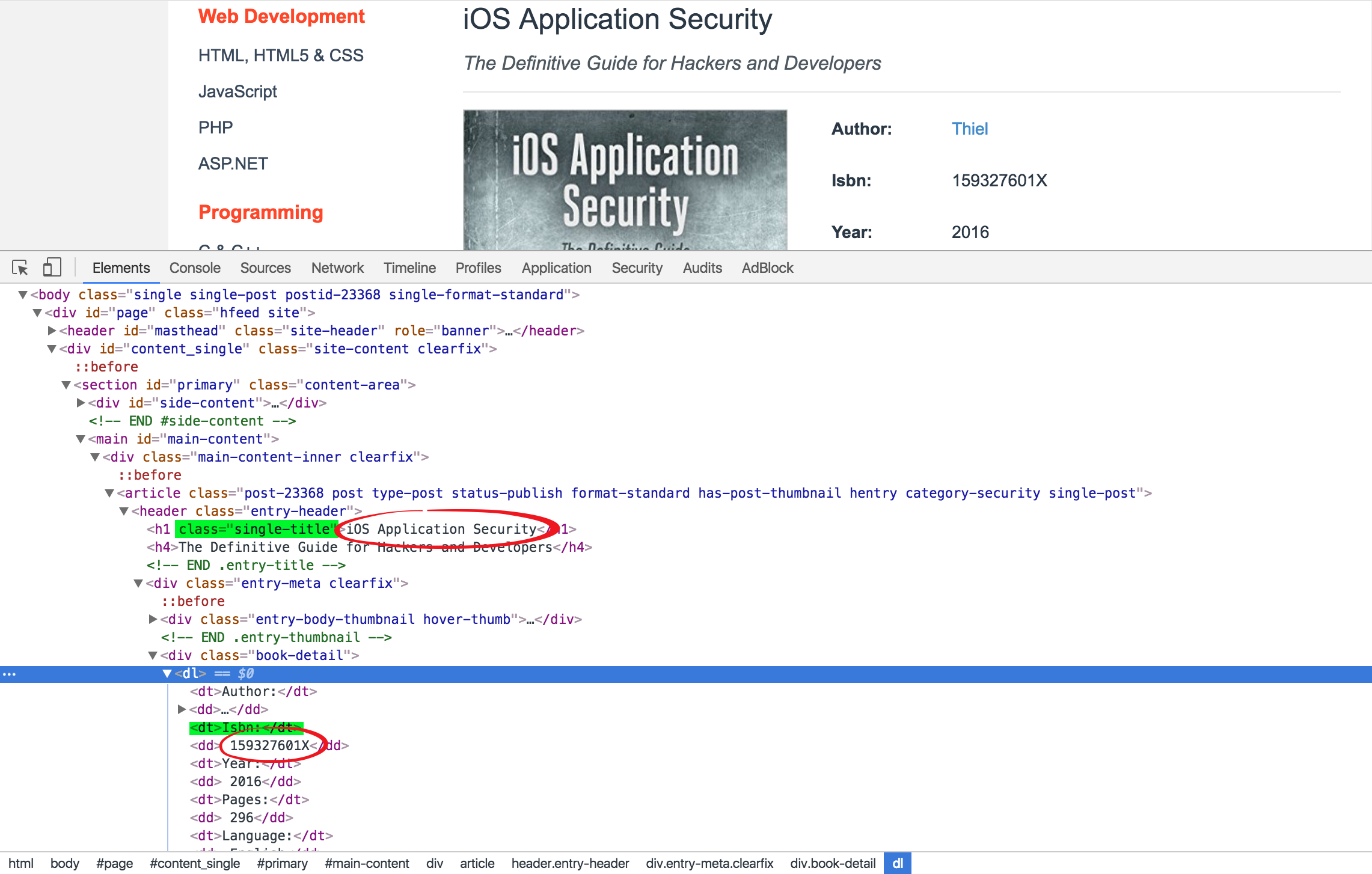
通过查看书籍详情页的HTML代码,我们可以通过查找class="single-title"定位到标题所在的h1标签获得标题,然后通过查找text="Isbn:"定位到"Isbn:"的所在的dt标签,此标签的下一个兄弟节点就是书籍ISBN码所在的标签,通过此标签的string属性可获得ISBN码内容。
代码如下:
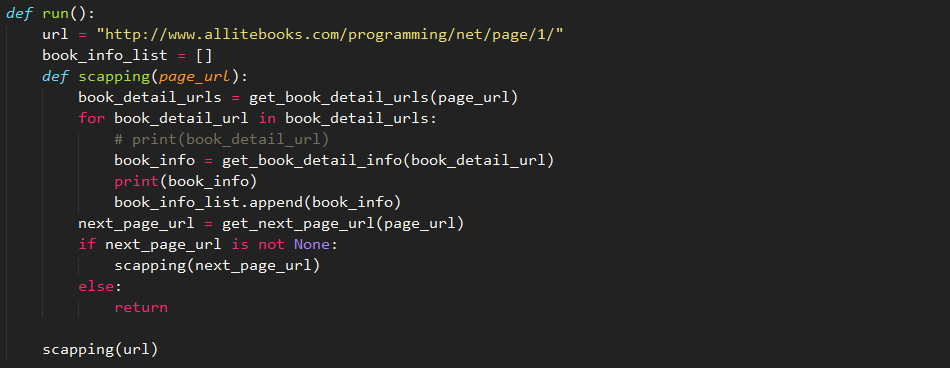
五、将三部分代码整合起来
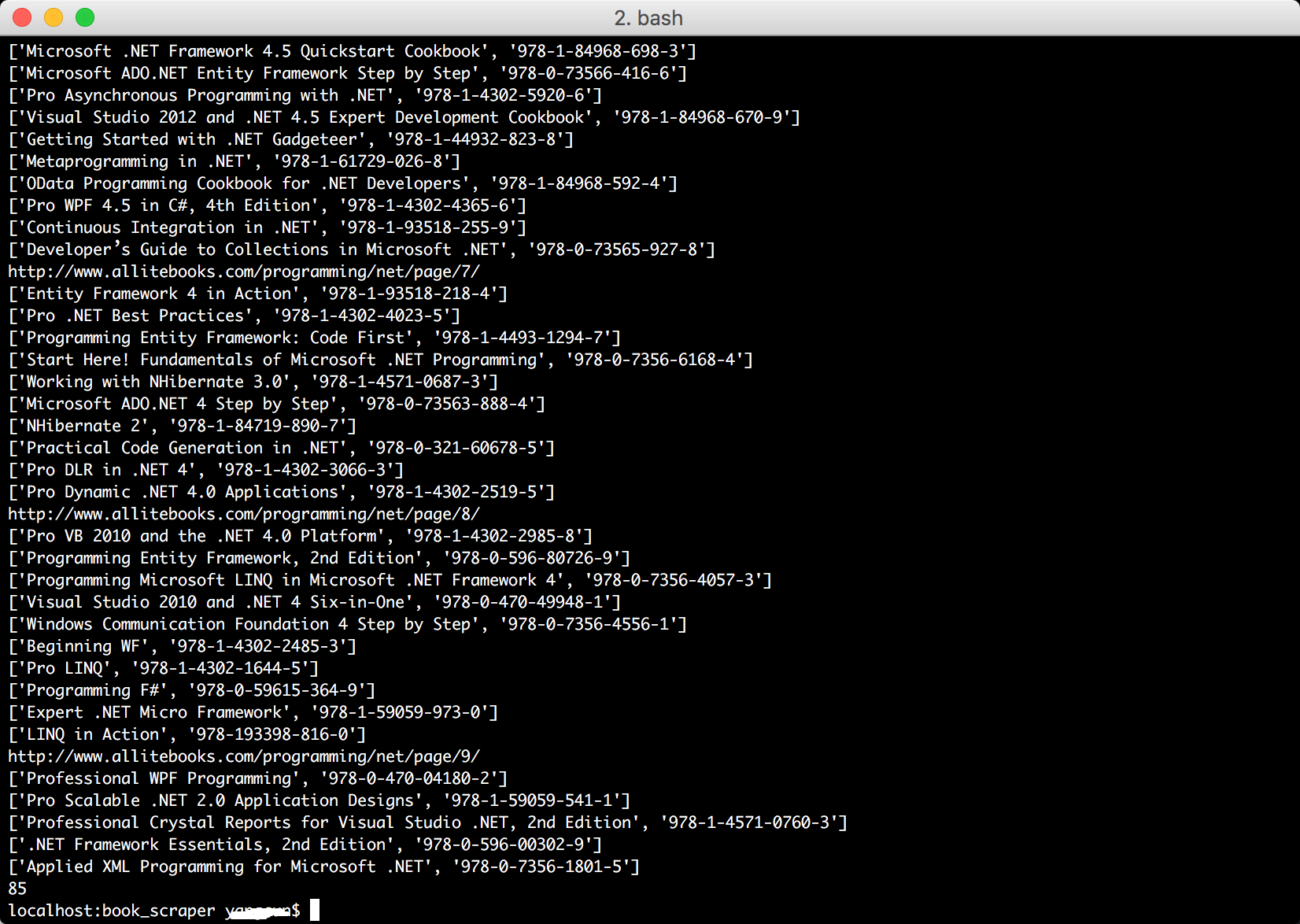
运行结果
六、将结果写入文件,以供下一步处理使用
