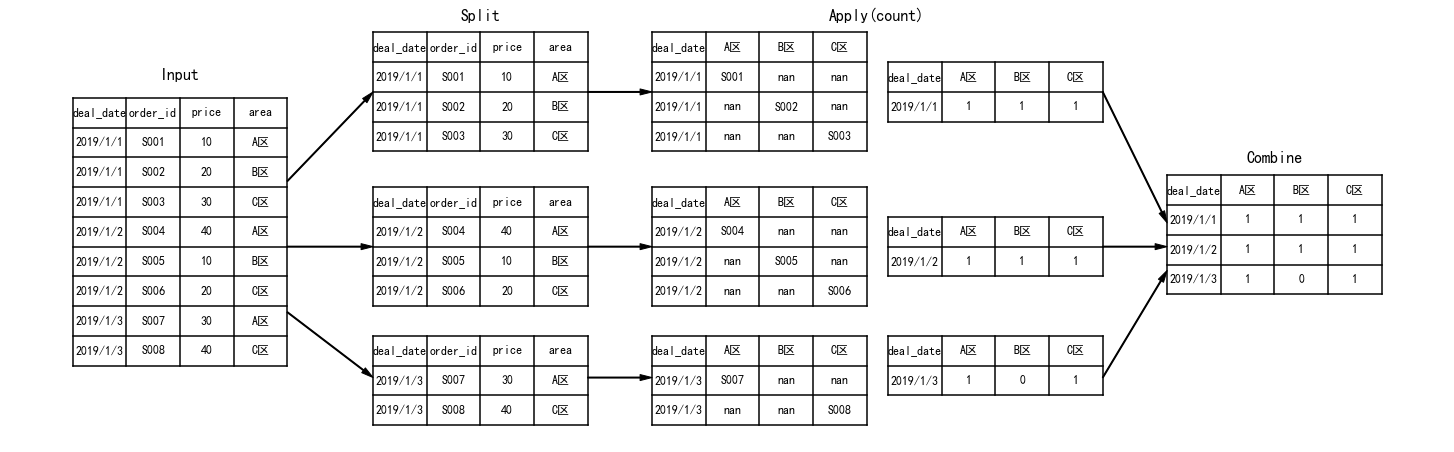
Matplotlib绘制分组聚合流程图
首先创建一个绘制Dataframe的代码:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
# 解决中文显示问题
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
def draw_dataframe(df, loc=None, width=None, ax=None, linestyle=None,
textstyle=None):
loc = loc or [0, 0]
width = width or 1
x, y = loc
if ax is None:
ax = plt.gca()
ncols = len(df.columns) + 1
nrows = len(df.index) + 1
dx = dy = width / ncols
if linestyle is None:
linestyle = {'color': 'black'}
if textstyle is None:
textstyle = {'size': 12}
textstyle.update({'ha': 'center', 'va': 'center'})
# 画表格的垂直线
for i in range(ncols + 1):
plt.plot(2 * [x + i * dx], [y, y + dy * nrows], **linestyle)
# 画表格的水平线
for i in range(nrows + 1):
plt.plot([x, x + dx * ncols], 2 * [y + i * dy], **linestyle)
# 绘制索引标签
for i in range(nrows - 1):
plt.text(x + 0.5 * dx, y + (i + 0.5) * dy,
str(df.index[::-1][i]), **textstyle)
# 绘制列标签
for i in range(ncols - 1):
plt.text(x + (i + 1.5) * dx, y + (nrows - 0.5) * dy,
str(df.columns[i]), style='italic', **textstyle)
# 绘制索引的名称
if df.index.name:
plt.text(x + 0.5 * dx, y + (nrows - 0.5) * dy,
str(df.index.name), style='italic', **textstyle)
# 插入数据文本
for i in range(nrows - 1):
for j in range(ncols - 1):
plt.text(x + (j + 1.5) * dx,
y + (i + 0.5) * dy,
str(df.values[::-1][i, j]), **textstyle)
然后开始绘制:
fig = plt.figure(figsize=(20, 6), facecolor='white')
ax = plt.axes([0, 0, 1, 1])
ax.axis('off')
draw_dataframe(data.set_index('deal_date'), [0, 0])
ys = [1.8, 0.5, -0.5]
result = []
for i, (deal_date, split) in enumerate(data.groupby('deal_date')):
draw_dataframe(split.set_index('deal_date'), [1.4, ys[i]])
split.loc[split.area == 'A区', 'A区'] = split.order_id
split.loc[split.area == 'B区', 'B区'] = split.order_id
split.loc[split.area == 'C区', 'C区'] = split.order_id
split = split.set_index('deal_date')[['A区', 'B区', 'C区']]
draw_dataframe(split, [2.7, ys[i]])
sum = split.count().to_frame(deal_date).T
sum.index.name = 'deal_date'
draw_dataframe(sum, [3.8, ys[i] + 0.25])
result.append(sum)
result = pd.concat(result)
draw_dataframe(result, [5.1, 0.6])
style = dict(fontsize=16, ha='center', weight='bold')
plt.text(0.5, 2.4, "Input", **style)
plt.text(1.9, 2.9, "Split", **style)
plt.text(3.75, 2.9, "Apply(count)", **style)
plt.text(5.6, 1.7, "Combine", **style)
arrowprops = dict(facecolor='black', width=1, headwidth=6)
plt.annotate('', (1.4, 2.3), (1.0, 1.55), arrowprops=arrowprops)
plt.annotate('', (1.4, 1), (1.0, 1), arrowprops=arrowprops)
plt.annotate('', (1.4, -0.1), (1.0, 0.45), arrowprops=arrowprops)
plt.annotate('', (2.7, 2.3), (2.4, 2.3), arrowprops=arrowprops)
plt.annotate('', (2.7, 1), (2.4, 1), arrowprops=arrowprops)
plt.annotate('', (2.7, -0.1), (2.4, -0.1), arrowprops=arrowprops)
plt.annotate('', (5.1, 1.2), (4.8, 2.3), arrowprops=arrowprops)
plt.annotate('', (5.1, 1), (4.8, 1), arrowprops=arrowprops)
plt.annotate('', (5.1, 0.8), (4.8, -0.1), arrowprops=arrowprops)
plt.show()
结果: