日常工作中,我们经常需要将office三件套,Word、Excel和PPT转换成PDF。当然办公软件自身都带有这样的功能,但当我们需要一次性转换大量的office文件时,用代码就比较方便。
其实这类代码有其他作者写过,但是呢,要么每个组件用一个库,用么代码没法正常跑。今天呢,我将带大家完全只使用win32调用vba的API来完成这个转换。
另外,将完成PDF书签的写入和提取操作以及批量加水印的操作。关于水印我们可以加背景底图水印或悬浮文字水印。
本文目录:
文章目录
office三件套转换为 PDF 格式
office三件套包括Word、Excel、PowerPoint ,为了调用office程序自身的API需要先确保已经安装pywin32,没有安装可以使用以下命令安装:
pip install pywin32
以下命令的导包:
import win32com.client as win32
import os
下面我们逐个查询API来测试:
将 Word 文档转换为 PDF
Document对象有个ExportAsFixedFormat方法:
https://docs.microsoft.com/zh-cn/office/vba/api/word.document.exportasfixedformat
所使用到的几个重要参数:

下面我们测试一下:
word_app = win32.gencache.EnsureDispatch('Word.Application')
file = word_app.Documents.Open(os.path.abspath("成立100周年大会讲话.doc"), ReadOnly=1)
file.ExportAsFixedFormat(os.path.abspath("成立100周年大会讲话.pdf"),
ExportFormat=17, Item=7, CreateBookmarks=1)
file.Close()
word_app.Quit()
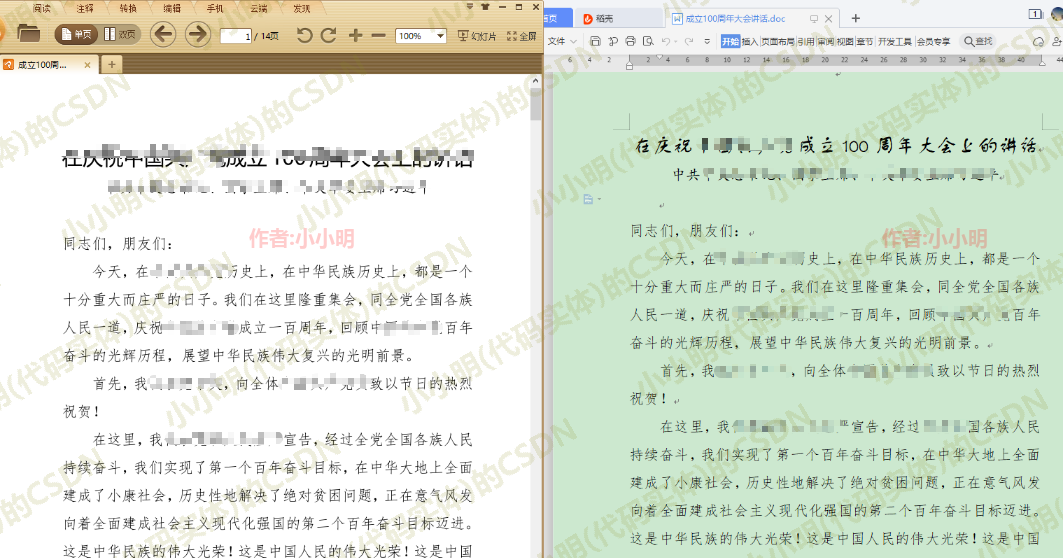
可以看到转换成功。
将 Excel 表格转换为 PDF
对于Excel主要有两个API:
https://docs.microsoft.com/zh-cn/office/vba/api/excel.workbook.exportasfixedformat
和
https://docs.microsoft.com/zh-cn/office/vba/api/excel.worksheet.exportasfixedformat
分别针对整个Excel文件和单个工作表。
我们默认都认为要转换所有工作表,所以只用workbook的导出API。
第一个参数是XlFixedFormatType 枚举类型,0表示PDF。
其他参数可以根据实际需要微调。
测试一下:
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
file = excel_app.Workbooks.Open(os.path.abspath("nsheet.xlsx"), ReadOnly=1)
file.ExportAsFixedFormat(0, os.path.abspath("nsheet.pdf"))
file.Close()
excel_app.Quit()
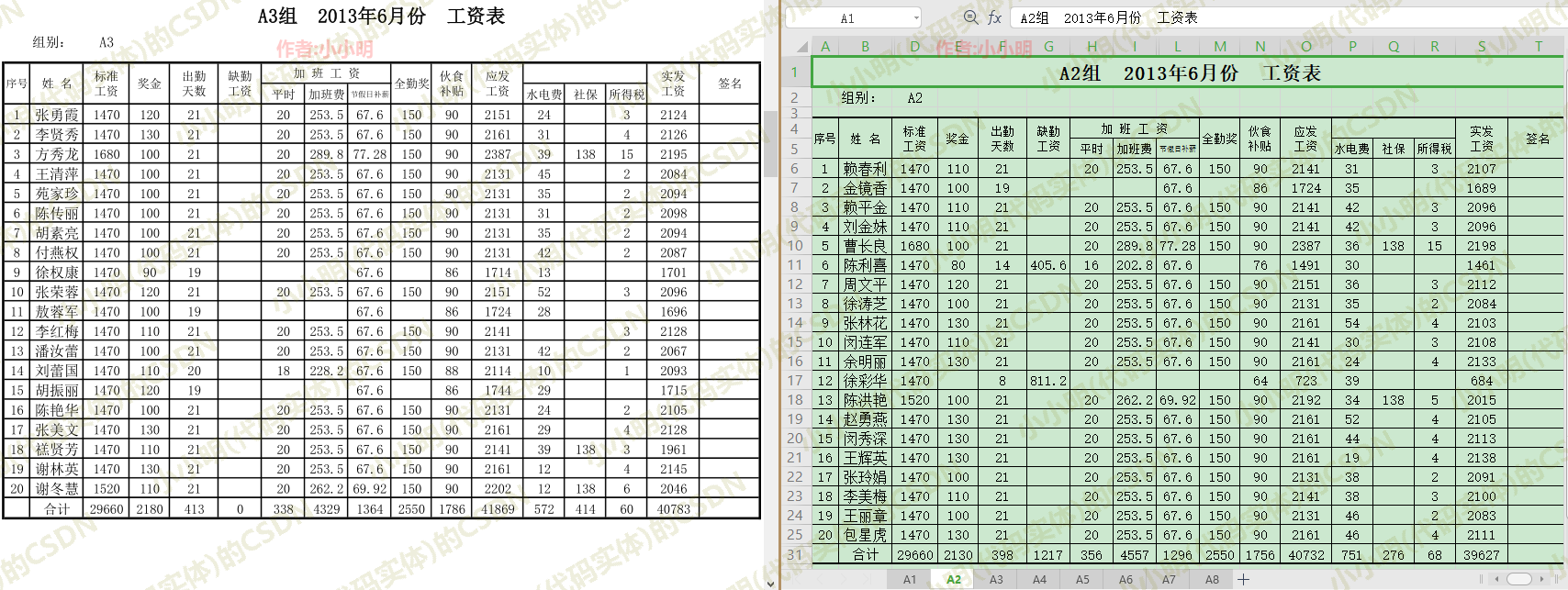
可以看到每一张工作表都导入到PDF文件的一页中。
将 PowerPoint 幻灯片转换为 PDF
对于PPT,官方虽然提供了导出API:Presentation.ExportAsFixedFormat 方法。但经过实测发现会报出The Python instance can not be converted to a COM object的类型错误。
这是因为PPT的saveAs保存API提供了直接另存为PDF的方法,详见:
https://docs.microsoft.com/zh-cn/office/vba/api/powerpoint.presentation.saveas
而ppSaveAsPDF常量的值为32,可以在https://docs.microsoft.com/zh-cn/office/vba/api/powerpoint.ppsaveasfiletype中查询到。
下面测试一下:
ppt_app = win32.gencache.EnsureDispatch('PowerPoint.Application')
file = ppt_app.Presentations.Open(os.path.abspath("第1章 机器学习和统计学习.pptx"), ReadOnly=1)
file.SaveAs(os.path.abspath("第1章 机器学习和统计学习.pdf"), 32)
file.Close()
ppt_app.Quit()
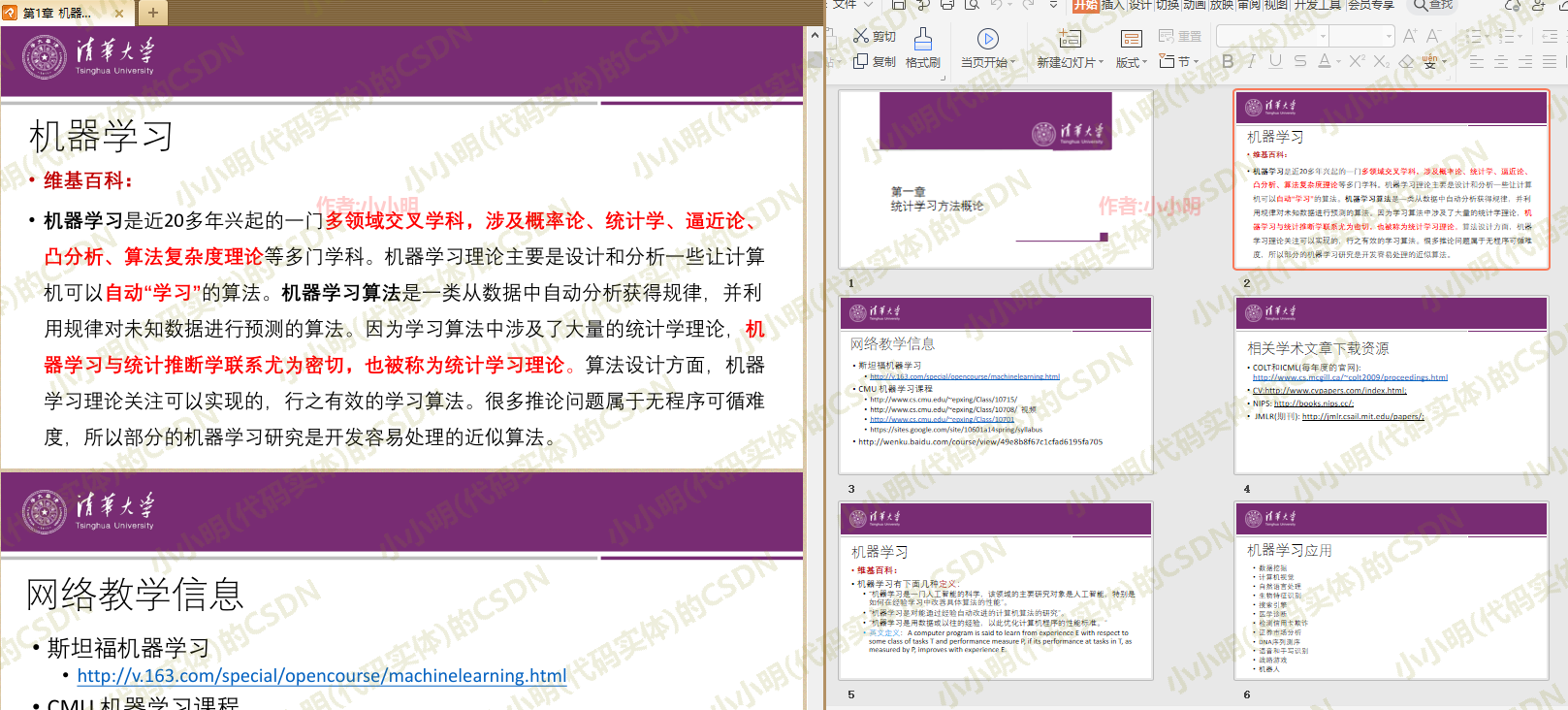
也可以。
批量转换成PDF
下面我们将上面测试好的代码封装起来,让其能够对任何一个office三件套之一的文件都能转换PDF,程序员封装为在原文件相对目录下生成相同文件名的PDF文件(可以根据实际需求修改代码):
office_type = {
"Word": [".doc", ".docx"],
"Excel": [".xlsx", ".xls", ".xlsm"],
"PowerPoint": [".pptx", ".ppt"]
}
cache = {}
for app_name, exts in office_type.items():
for ext in exts:
cache[ext] = app_name
def office_file2pdf(filename):
filename_no_ext, ext = os.path.splitext(filename)
app_name = cache.get(ext)
if app_name == "Word":
app = win32.gencache.EnsureDispatch('Word.Application')
file = app.Documents.Open(os.path.abspath(filename), ReadOnly=1)
try:
file.ExportAsFixedFormat(os.path.abspath(f"{filename_no_ext}.pdf"),
ExportFormat=17, Item=7, CreateBookmarks=1)
finally:
file.Close()
elif app_name == "Excel":
app = win32.gencache.EnsureDispatch('Excel.Application')
file = app.Workbooks.Open(os.path.abspath(filename), ReadOnly=1)
try:
file.ExportAsFixedFormat(
0, os.path.abspath(f"{filename_no_ext}.pdf"))
finally:
file.Close()
elif app_name == "PowerPoint":
app = win32.gencache.EnsureDispatch('PowerPoint.Application')
file = app.Presentations.Open(os.path.abspath(filename), ReadOnly=1)
try:
file.SaveAs(os.path.abspath(f"{filename_no_ext}.pdf"), 32)
finally:
file.Close()
开头先定义了各类文件所对应的格式,后面定义了一个同源。
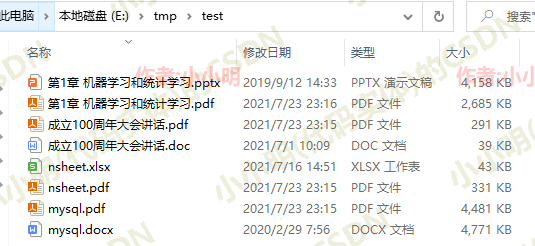
下面批量转换一下指定文件夹:
from glob import glob
path = "E:\tmp\test"
for filename in glob(f"{path}/*"):
office_file2pdf(filename)
win32.gencache.EnsureDispatch('Word.Application').Quit()
win32.gencache.EnsureDispatch('Excel.Application').Quit()
win32.gencache.EnsureDispatch('PowerPoint.Application').Quit()
生成后:
PDF书签的提取与写入
后面我们打算使用PyPDF2来批量加水印,比较尴尬的是用这个库只能重新创建PDF文件,导致书签丢失,所以我们需要事先能提取标签并写入才行。顺便就可以写出一套可以给PDF加书签的方法。
PyPDF2库的安装:
pip install PyPDF2
PDF书签提取
from PyPDF2 import PdfFileReader
def get_pdf_Bookmark(filename):
"作者CSDN:https://blog.csdn.net/as604049322"
if isinstance(filename, str):
pdf_reader = PdfFileReader(filename)
else:
pdf_reader = filename
pagecount = pdf_reader.getNumPages()
# 用保存每个标题id所对应的页码
idnum2pagenum = {}
for i in range(pagecount):
page = pdf_reader.getPage(i)
idnum2pagenum[page.indirectRef.idnum] = i
# 保存每个标题对应的标签数据,包括层级,标题和页码索引(页码-1)
bookmark = []
def get_pdf_Bookmark_inter(outlines, tab=0):
for outline in outlines:
if isinstance(outline, list):
get_pdf_Bookmark_inter(outline, tab+1)
else:
bookmark.append(
(tab, outline['/Title'], idnum2pagenum[outline.page.idnum]))
outlines = pdf_reader.getOutlines()
get_pdf_Bookmark_inter(outlines)
return bookmark
测试提取书签:
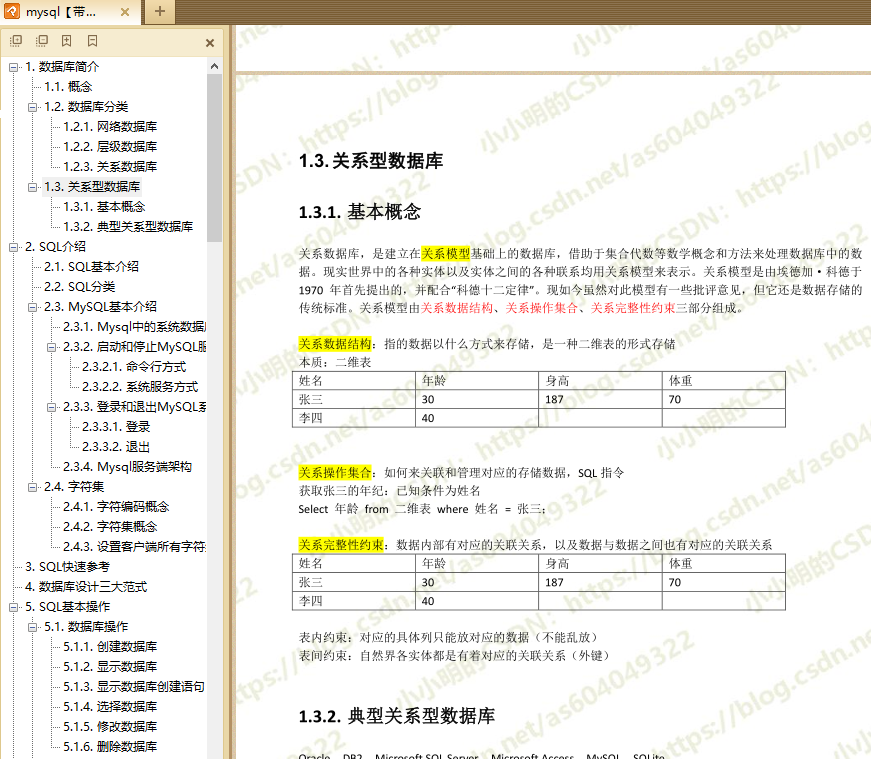
bookmark = get_pdf_Bookmark(filename='mysql.pdf')
bookmark
[(0, '1. 数据库简介', 0),
(1, '1.1. 概念', 0),
(1, '1.2. 数据库分类', 0),
(2, '1.2.1. 网络数据库', 0),
(2, '1.2.2. 层级数据库', 0),
(2, '1.2.3. 关系数据库', 0),
(1, '1.3. 关系型数据库', 1),
(2, '1.3.1. 基本概念', 1),
(2, '1.3.2. 典型关系型数据库', 1),
......
PDF书签保存到文件
def write_bookmark2file(bookmark, filename="bookmark.txt"):
with open(filename, "w") as f:
for tab, title, pagenum in bookmark:
prefix = "\t"*tab
f.write(f"{prefix}{title}\t{pagenum+1}\n")
write_bookmark2file(bookmark)

从文件读取PDF书签数据
有时我们希望自定义标签,所以可以从文件读取书签数据:
def read_bookmark_from_file(filename="bookmark.txt"):
bookmark = []
with open(filename) as f:
for line in f:
l2 = line.rfind("\t")
l1 = line.rfind("\t", 0, l2)
bookmark.append((l1+1, line[l1+1:l2], int(line[l2+1:-1])-1))
return bookmark
测试:
read_bookmark_from_file()
读取结果与上面提取到的书签一致。
向PDF写入书签数据
下面我们测试从一个PDF读取书签后原本复制并保存。
先原样复制PDF:
from PyPDF2 import PdfFileReader, PdfFileWriter
filename = 'mysql.pdf'
pdf_reader = PdfFileReader(filename)
pdf_writer = PdfFileWriter()
for page in pdf_reader.pages:
pdf_writer.addPage(page)
读取书签并写入:
bookmark = read_bookmark_from_file()
last_cache = [None]*(max(bookmark, key=lambda x: x[0])[0]+1)
for tab, title, pagenum in bookmark:
parent = last_cache[tab-1] if tab > 0 else None
indirect_id = pdf_writer.addBookmark(title, pagenum, parent=parent)
last_cache[tab] = indirect_id
pdf_writer.setPageMode("/UseOutlines")
最后保存看看:
with open("tmp.pdf", "wb") as out:
pdf_writer.write(out)
可以看到书签已经完美保留:
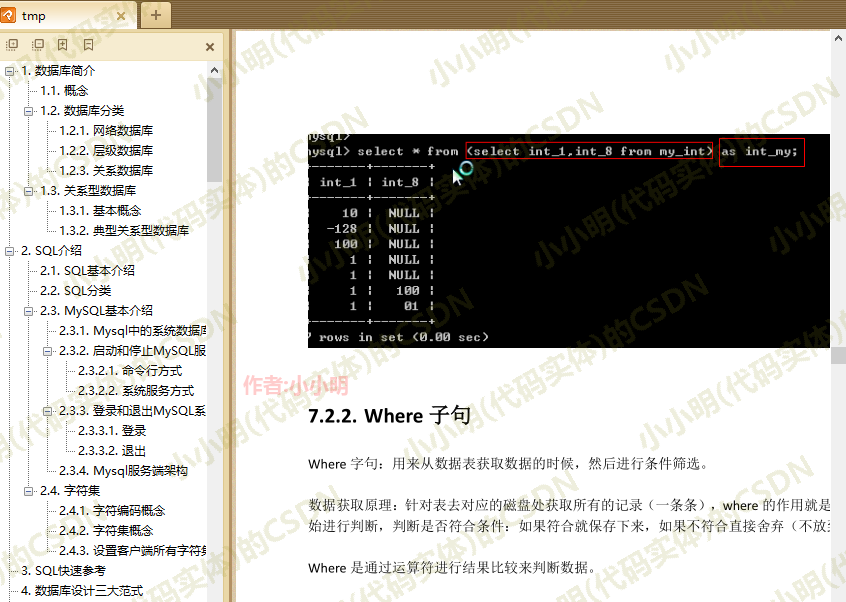
给PDF加水印
对于给PDF加水印,我个人还是推荐一些在线的免费工具或WPS。这些工具基本都支持加悬浮的透明水印。除非你确实有批量给PDF文件加水印的需求。
需要注意使用python的PyPDF2库给PDF加水印,采用的是叠加模式,实际并不能算是加水印,而是加背景。
具体原理是用一张需要作为水印的PDF打底,然后将原本的PDF文件一页页叠加到上面。
首先我们需要生成水印PDF:
生成水印PDF文件
代码:
import math
from PIL import Image, ImageFont, ImageDraw, ImageEnhance, ImageChops
def crop_image(im):
'''裁剪图片边缘空白'''
bg = Image.new(mode='RGBA', size=im.size)
bbox = ImageChops.difference(im, bg).getbbox()
if bbox:
return im.crop(bbox)
return im
def set_opacity(im, opacity):
'''设置水印透明度'''
assert 0 <= opacity <= 1
alpha = im.split()[3]
alpha = ImageEnhance.Brightness(alpha).enhance(opacity)
im.putalpha(alpha)
return im
def get_mark_img(text, color="#8B8B1B", size=30, opacity=0.15):
width = len(text) * size
mark = Image.new(mode='RGBA', size=(width, size+20))
ImageDraw.Draw(im=mark) \
.text(xy=(0, 0),
text=text,
fill=color,
font=ImageFont.truetype('msyhbd.ttc', size=size))
mark = crop_image(mark)
set_opacity(mark, opacity)
return mark
def create_watermark_pdf(text, filename="watermark.pdf", img_size=(840, 1150), color="#8B8B1B", size=30, opacity=0.15, space=75, angle=30):
mark = get_mark_img(text, color, size, opacity)
im = Image.new(mode='RGB', size=img_size, color="white")
w, h = img_size
c = int(math.sqrt(w**2 + h**2))
mark2 = Image.new(mode='RGBA', size=(c, c))
y, idx = 0, 0
mark_w, mark_h = mark.size
while y < c:
x = -int((mark_w + space)*0.5*idx)
idx = (idx + 1) % 2
while x < c:
mark2.paste(mark, (x, y))
x = x + mark_w + space
y = y + mark_h + space
mark2 = mark2.rotate(angle)
im.paste(mark2, (int((w-c)/2), int((h-c)/2)), # 坐标
mask=mark2.split()[3])
im.save(filename, "PDF", resolution=100.0, save_all=True)
create_watermark_pdf("小小明的CSDN:https://blog.csdn.net/as604049322")
生成效果:

当然我们也可以借助word或WPS生成这样的水印PDF。
然后就可以批量给每一页加水印了:
PyPDF2库批量加水印
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
from copy import copy
def pdf_add2watermark(filename, save_filepath, watermark='watermark.pdf'):
watermark = PdfFileReader(watermark).getPage(0)
pdf_reader = PdfFileReader(filename)
pdf_writer = PdfFileWriter()
for page in pdf_reader.pages:
new_page = copy(watermark)
new_page.mergePage(page)
new_page.compressContentStreams()
pdf_writer.addPage(new_page)
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
filename = 'mysql.pdf'
save_filepath = 'mysql【带水印】.pdf'
pdf_add2watermark(filename, save_filepath)
可以看到水印已经成功的加上,就是缺少目录(书签)。
拷贝书签
下面我们将书签从原始文件拷贝到加过水印的PDF文件中:
from PyPDF2 import PdfFileReader, PdfFileWriter
def get_pdf_Bookmark(filename):
"作者CSDN:https://blog.csdn.net/as604049322"
if isinstance(filename, str):
pdf_reader = PdfFileReader(filename)
else:
pdf_reader = filename
pagecount = pdf_reader.getNumPages()
# 用保存每个标题id所对应的页码
idnum2pagenum = {}
for i in range(pagecount):
page = pdf_reader.getPage(i)
idnum2pagenum[page.indirectRef.idnum] = i
# 保存每个标题对应的标签数据,包括层级,标题和页码索引(页码-1)
bookmark = []
def get_pdf_Bookmark_inter(outlines, tab=0):
for outline in outlines:
if isinstance(outline, list):
get_pdf_Bookmark_inter(outline, tab+1)
else:
bookmark.append((tab, outline['/Title'], idnum2pagenum[outline.page.idnum]))
outlines = pdf_reader.getOutlines()
get_pdf_Bookmark_inter(outlines)
return bookmark
def copy_bookmark2pdf(srcfile, destfile):
"作者CSDN:https://blog.csdn.net/as604049322"
bookmark = get_pdf_Bookmark(srcfile)
pdf_reader = PdfFileReader(destfile)
pdf_writer = PdfFileWriter()
for page in pdf_reader.pages:
pdf_writer.addPage(page)
last_cache = [None]*(max(bookmark, key=lambda x: x[0])[0]+1)
for tab, title, pagenum in bookmark:
parent = last_cache[tab-1] if tab > 0 else None
indirect_id = pdf_writer.addBookmark(title, pagenum, parent=parent)
last_cache[tab] = indirect_id
pdf_writer.setPageMode("/UseOutlines")
with open(destfile, "wb") as out:
pdf_writer.write(out)
copy_bookmark2pdf('mysql.pdf', 'mysql【带水印】.pdf')
成功实现既有水印又有书签。
上述代码涉及二次调用,而且涉及重复的磁盘读写操作,我们在一次读写磁盘时就直接把书签加上,现在重新封装一下:
加水印同时复制书签
将上述代码重新整理一下,并将递归转换为生成器调用:
from PyPDF2 import PdfFileReader, PdfFileWriter
from copy import copy
def get_pdf_Bookmark(pdf_file):
"作者CSDN:https://blog.csdn.net/as604049322"
if isinstance(pdf_file, str):
pdf_reader = PdfFileReader(filename)
else:
pdf_reader = pdf_file
pagecount = pdf_reader.getNumPages()
# 用保存每个标题id所对应的页码
idnum2pagenum = {}
for i in range(pagecount):
page = pdf_reader.getPage(i)
idnum2pagenum[page.indirectRef.idnum] = i
# 保存每个标题对应的标签数据,包括层级,标题和页码索引(页码-1)
def get_pdf_Bookmark_inter(outlines, tab=0):
for outline in outlines:
if isinstance(outline, list):
yield from get_pdf_Bookmark_inter(outline, tab+1)
else:
yield (tab, outline['/Title'], idnum2pagenum[outline.page.idnum])
outlines = pdf_reader.getOutlines()
return [_ for _ in get_pdf_Bookmark_inter(outlines)]
def write_bookmark2pdf(bookmark, pdf_file):
"作者CSDN:https://blog.csdn.net/as604049322"
if isinstance(pdf_file, str):
pdf_writer = PdfFileWriter()
else:
pdf_writer = pdf_file
last_cache = [None]*(max(bookmark, key=lambda x: x[0])[0]+1)
for tab, title, pagenum in bookmark:
parent = last_cache[tab-1] if tab > 0 else None
indirect_id = pdf_writer.addBookmark(title, pagenum, parent=parent)
last_cache[tab] = indirect_id
pdf_writer.setPageMode("/UseOutlines")
if isinstance(pdf_file, str):
with open(pdf_file, "wb") as out:
pdf_writer.write(out)
def pdf_add2watermark(filename, save_filepath, watermark='watermark.pdf'):
watermark = PdfFileReader(watermark).getPage(0)
pdf_reader = PdfFileReader(filename)
pdf_writer = PdfFileWriter()
for page in pdf_reader.pages:
new_page = copy(watermark)
new_page.mergePage(page)
new_page.compressContentStreams()
pdf_writer.addPage(new_page)
bookmark = get_pdf_Bookmark(pdf_reader)
write_bookmark2pdf(bookmark, pdf_writer)
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
filename = 'mysql.pdf'
save_filepath = 'mysql【带水印】.pdf'
pdf_add2watermark(filename, save_filepath)
可以看到经过压缩生成的加水印的PDF比原文件更小。
PyMuPDF给PDF加文字水印
前面我们使用PyPDF2库给PDF增加了背景底图性质的图片水印,那有什么方法可以给PDF增加文字型的水印呢?那就是通过PyPDF2库。
官方文档:https://pymupdf.readthedocs.io/en/latest/index.html
Github:https://github.com/pymupdf/PyMuPDF
安装:
pip install pymupdf
实现代码:
import fitz
with fitz.open("mysql【带水印】.pdf") as pdf_doc:
for page in pdf_doc:
page.insert_text((20, 40), "小小明的CSDN", fontsize=30, color=(1, 0, 0),
fontname="china-s", fill_opacity=0.2)
page.insert_text((20, page.rect.height-20), "https://blog.csdn.net/as604049322",
color=(1, 1, 1, 1), fontsize=20, fill_opacity=0.2)
pdf_doc.save('mysql【带水印】2.pdf')
上述代码给PDF每一页都增加了两个悬浮文字,其中纯链接的文字还有点击跳转的效果:
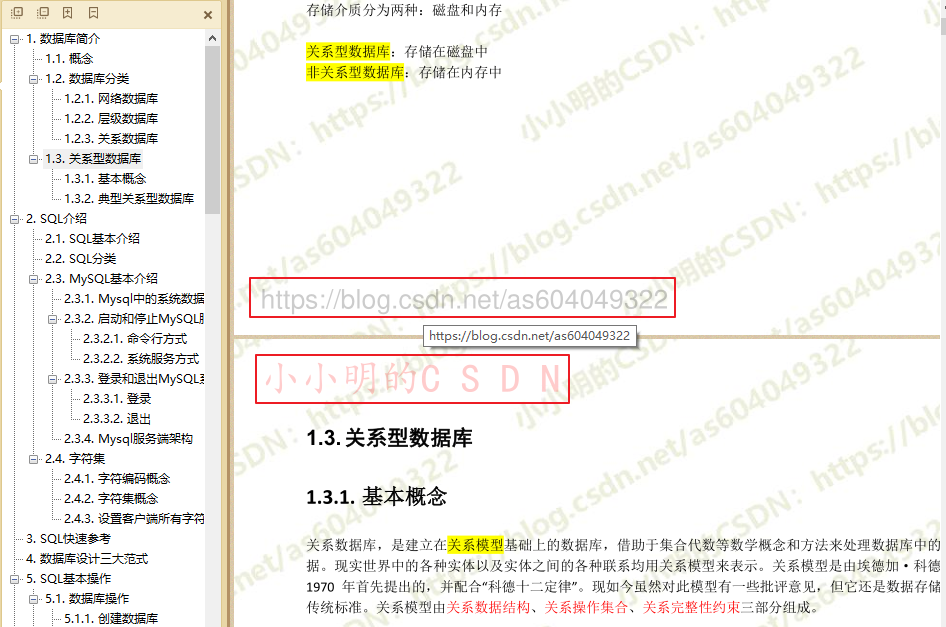
当然上述代码只是一种抛砖引玉的写法,想要增加更复杂的文字水印还需各位读者认真阅读官方文档和PyMuPDF的源码。
我所参考的文档主要有:
- https://pymupdf.readthedocs.io/en/latest/textwriter.html
- https://pymupdf.readthedocs.io/en/latest/page.html#Page.write_text
- https://pymupdf.readthedocs.io/en/latest/page.html#Page.insert_text
注意:Page.insert_text有个rotate参数可以对文字进行旋转,但该参数仅支持90度倍数的旋转。
如果直接给未经PyPDF2库压缩的PDF增加文字水印会导致文件大小增加较大,此时还可以使用PyPDF2库对PDF进行压缩输出:
PyPDF2库压缩PDF
def compress_pdf(filename, save_filepath):
pdf_reader = PdfFileReader(filename)
pdf_writer = PdfFileWriter()
for page in pdf_reader.pages:
page.compressContentStreams()
pdf_writer.addPage(page)
bookmark = get_pdf_Bookmark(pdf_reader)
write_bookmark2pdf(bookmark, pdf_writer)
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
结合前面PyPDF2读写书签的代码即可完成PDF的压缩。