摘要
昨天下午的时候,真的是无语至极。本以为CSDN上博友们应都是与人为善类型的。没想到都博客专家级别的了,出口竟是如此不堪。难道请教问题就得是一副高高在上,别人必须给你解决问题,给你代码吗?
对于此类人,我不做过多评价。我只会在心里默默说一句,好自为之吧。希望此后永远不会有交集!
言归正传,写爬虫的时候。难免会使用代理IP技术。于Python中调用代理IP实则是一件轻松的事,但是有一个不大不小的问题,那就是代理IP的有效性。
往往做爬虫的时候会事先爬取很多的代理ip作为备用,但是有些可能还用,有些可能就失效了。所以程序会因此变得不甚稳定。于是在爬虫运行之前,保证代理IP的高可用性,是有一定的必要的。
今日,就来做这么一件“清洗”工作。
原理
当然,测试代理IP有效性的方法有很多。我想到的无非也就其中一种,不具权威性,仅供参考罢了。
我个人认为,测试代理IP有效性还是得从服务器端下手,毕竟代理IP是要去访问真正的服务器端的。所以在服务器端进行验证最合适不过了。服务器端验证完毕之后,将结果返回给客户端,如此“清洗”工作就可以据此完成。保留有效的代理IP,去除失效的代理IP。
接下来,按部就班的实现就行了。
服务器端
服务器端使用什么语言都是可以的,我这里正好有php环境,自然选择了PHP了。
$_SERVER
$_SERVER变量中包含了客户端来访的全部信息,所以仅仅需要把相关的部分剖取出来就够了。
脚本
<?php
echo "Client IP:".$_SERVER['REMOTE_ADDR'];是不是足够简单。
不过为了接下来客户端“清洗”方便,我们仅仅把客户端IP输出就行了。这样免得客户端在进行字符串分割处理。
<?php
echo $_SERVER['REMOTE_ADDR'];简单的测试一下:
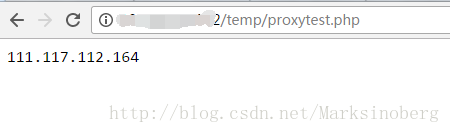
此时,仅仅使用浏览器作为客户端,所以没用到代理IP。可见,服务器端搭建依然成功了。接下来就是在客户端进行验证了。
客户端
客户端这块,毕竟爬虫使用Python的还是比较多的,而且对我自己而言,Python也顺手,所以就是用Python好了。
在我印象中,涉及到代理部分的库以urllib2和requests最为常见。下面简单的贴下代码。
urllib2
在urllib2中使用的代理IP分为http类型和https类型,需要分别处理一下。
- http类型:
proxy=urllib2.ProxyHandler({'http': '代理IP'})
opener=urllib2.build_opener(proxy)
urllib2.install_opener(opener)- https类型:
proxy=urllib2.ProxyHandler({'https': '代理IP'})
opener=urllib2.build_opener(proxy)
urllib2.install_opener(opener)
requests
相比之下,requests 就更为方便了。不管是http类型还是https类型都是兼容的。统统放到一个字典内说明即可。
#coding: utf8
import requests
proxies = {
"http": "115.231.105.109:8081",
"http": "101.230.214.25:8080",
"https": "218.29.111.106:9999",
}
result = requests.get('http://101.200.58.242/temp/proxytest.php', proxies=proxies)
print result.content完整代码
# coding: utf8
import requests
# 本机IP
localip = "111.117.112.164"
# 待清洗代理IP数据池
proxies = [
{"http": "115.231.105.109:8081" },
{"http": "218.76.106.78:3128" },
{"http": "183.185.0.18:9797"},
{"https": "218.29.111.106:9999" },
]
# 有效代理IP池
proxypool = []
# 清洗代理IP,去除无效的代理IP
for index in range(len(proxies)):
print proxies[index]
try:
result = requests.get('http://101.200.58.242/temp/proxytest.php', proxies=proxies[index])
except Exception as e:
continue
# 与本机IP对比,相等则说明没用到代理IP,为无效项
if result.content != localip:
proxypool.append(proxies[index])
print proxypool这样就可以简单的测试出代理IP的有效性了。当然效率确实不够高,有必要的话使用多线程来进行加速也是可以的。
演示
提示
在演示之前,我觉得还是有必要啰嗦一下的。
在做爬虫的时候,不管是公司内还是学校里。大部分都是在局域网内,这样获取本机的IP就需要动点心思了。当然,现在网络上资源很多,各种获取本机IP的接口。随便处理一下就可以了。如一开始我那样直接用浏览器访问自己的服务器来测试也是可以的。
下面介绍一个最常用的。直接在浏览器上输入ip。
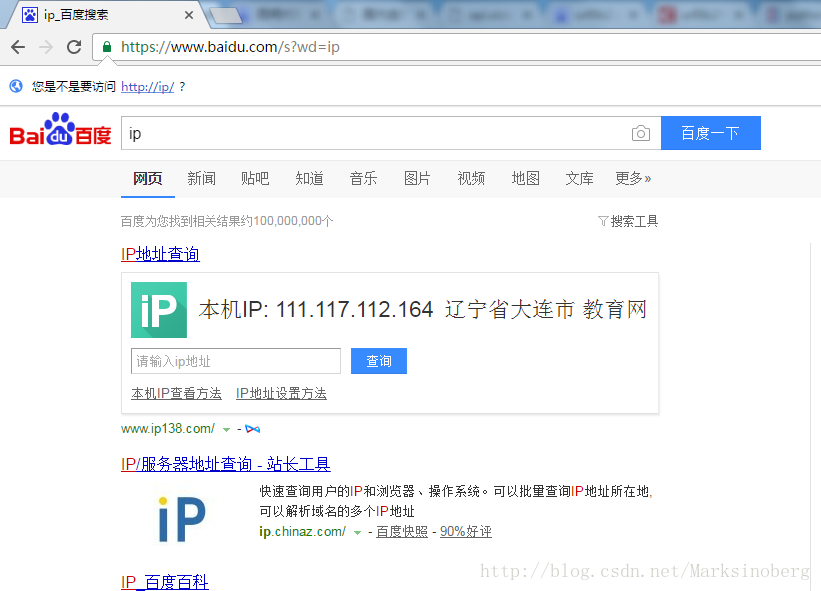
然后就可以使用这个本机IP作为过滤条件来进行清理工作了。当然了,这一步还可以更加的智能化,继续写点代码来完成,我在这就权当是抛砖引玉吧。博友有需要的话知道有这么个思路就行了。
清洗效果
最后来看看测试的效果吧,我是在网上随便找了个网站,直接手动复制的几个代理IP(代码中有记录)。然后直接测了一下,发现还不错,有三个是能用的。
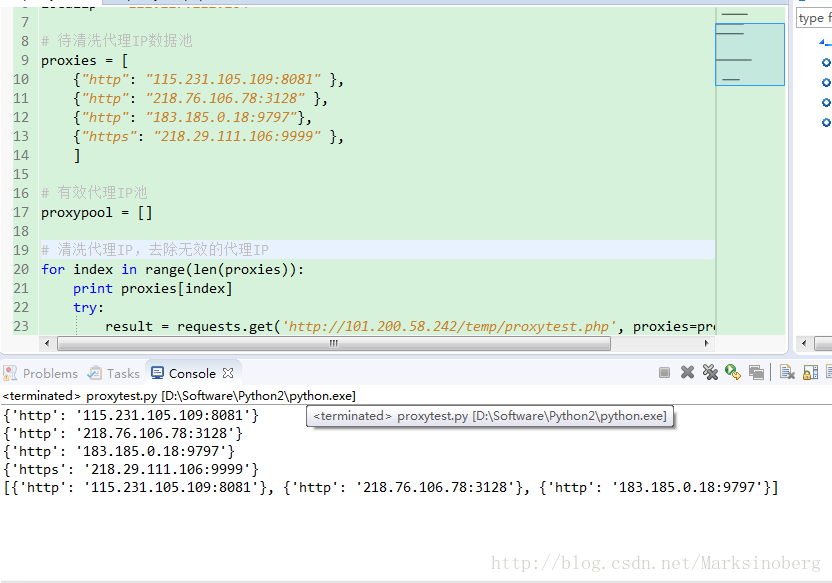
总结
最后回顾一下,本次试验代码量很少。但是思路还是蛮清晰的。实现起来也比较简单。
需要注意的是这个测试需要有服务器的支持,否则在本地localhost的时候代理IP不能有效的工作。
最后,还是觉得:
做事之前还是先学会做人的好。
社会上不是每一个人都能淡然面对他人的无礼的,总会有让你后悔的那天。与君共勉。