作者:小小明
上期我演示了高效过滤停用词的方法,这期我将带你重温Python基础中set集合和字典的使用方法,并讲解字典和集合的实现原理。本期同步更新的还另有一篇《词频统计的3种方法》。
文章目录
下面我们复习一下set集合和字典的用法,温故而知新,最终探究,set集合能够加速过滤停用词的原理是什么。
set集合的基本用法
set集合的创建
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set([iterable])
iterable – 可迭代的对象,比如列表、字典、元组等等。
示例代码:
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 这里演示的是去重功能
# {'orange', 'banana', 'pear', 'apple'}
print('orange' in basket) # 快速判断元素是否在集合内
# True
print('crabgrass' in basket)
# False
Set集合的交集&并集&差集
示例代码:
# 下面展示两个集合间的运算.
a = set('abracadabra')
b = set('alacazam')
print(a)
# {'a', 'r', 'b', 'c', 'd'}
print("差集:", a - b) # 集合a中包含而集合b中不包含的元素
# {'r', 'd', 'b'}
print("并集:", a | b) # 集合a或b中包含的所有元素
# {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
print("交集:", a & b) # 集合a和b中都包含了的元素
# {'a', 'c'}
print("异或集", a ^ b) # 不同时包含于a和b的元素
# {'r', 'd', 'b', 'm', 'z', 'l'}
set的集合推导式
a = {x for x in 'abracadabra' if x not in 'abc'}
a
结果:
{'d', 'r'}
set集合的常用内置方法
| 方法 | 描述 |
|---|---|
| add() | 将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。 |
| s.discard( x ) | 删除集合中指定的元素,如果元素不存在,不会发生错误 |
| s.remove( x ) | 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| s.update( x ) | 参数可以是列表,元组,字典 |
字典生成式
set集合有集合推导式,而字典也有相应的字典生成式:
test_dict = {"Baidu": 1, "Google": 2, "Taobao": 3, "Zhihu": 4}
new_dict = {key: val for key, val in test_dict.items() if key != 'Zhihu'}
# 输出移除后的字典
new_dict
结果:
{'Baidu': 1, 'Google': 2, 'Taobao': 3}
字典常用内置方法
| 函数 | 描述 |
|---|---|
| dict.clear() | 删除字典内所有元素 |
| dict.copy() | 返回一个字典的浅复制 |
| dict.fromkeys(seq[, val])) | 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| dict.get(key,default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| key in dict | 如果键在字典dict里返回true,否则返回false |
| dict.items() | 以列表返回可遍历的(键, 值) 元组数组 |
| dict.keys() | 以列表返回一个字典所有的键 |
| dict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| dict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| dict.values() | 以列表返回字典中的所有值 |
| dict.pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| dict.popitem() | 随机返回并删除字典中的最后一对键和值。 |
set集合为什么可以加速筛选
字典和集合的基本概念
字典是一系列由键(key)和值(value)配对组成的元素的集合,而集合没有键和值的配对,是一系列无序的、唯一的元素组合,相当于没有值的字典。
在 Python3.7+,字典被确定为有序(注意:在 3.6 中无法 100% 确保其有序性),而 3.6 之前是无序的,其长度大小可变,元素可以任意地删减和改变。
相比于列表和元组,字典和集合性能较高,查找、添加和删除操作都能在常数时间复杂度内完成。集合不支持索引操作,因为它的本质是一个哈希表,而字典支持对指定键的索引操作。
创建字典的4种方法:
d1 = {'name': 'jason', 'age': 20, 'gender': 'male'}
d2 = dict({'name': 'jason', 'age': 20, 'gender': 'male'})
d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')])
d4 = dict(name='jason', age=20, gender='male')
d1 == d2 == d3 ==d4
结果:True
创建集合的2种方法:
s1 = {1, 2, 3}
s2 = set([1, 2, 3])
s1 == s2
结果:True
字典和集合常用的方法相信大部分读者都会就不演示了,但要注意的是,集合的 pop() 操作是删除集合中最后一个元素,可是集合本身是无序的,就无法知道会删除哪个元素,因此这个操作得谨慎使用。
对于set集合直接调用 sorted(set) 可返回一个排好序的列表:
s = {3, 4, 2, 1}
sorted(s) # 对集合的元素进行升序排序
结果:
[1, 2, 3, 4]
字典和集合的存储原理
前面我们看到了集合相对普通列表过滤操作的高效性,但集合为什么能够如此高效呢?
这取决于字典、集合内部的数据结构,它们的内部结构都是一张哈希表:
- 对于字典而言,这张表存储了哈希值(hash)、键和值这 3 个元素。
- 而对集合来说,这张表仅存储了单一的元素。
老版本Python的哈希表结构如下所示:
| 哈希值 (hash) | 键 (key) | 值 (value) |
|---|---|---|
| hash0 | key0 | value0 |
| hash1 | key1 | value1 |
| hash2 | key2 | value2 |
这种结构的哈希表随着扩张,它会变得越来越稀疏。
比如有这样一个字典:
{'name': 'xiaohua', 'date': '1999-01-01', 'gender': 'male'}
那么它会存储为类似下面的形式:
entries = [
['--', '--', '--']
[-230273521, 'date', '1999-01-01'],
['--', '--', '--'],
['--', '--', '--'],
[1231236123, 'name', 'xiaohua'],
['--', '--', '--'],
[9371539127, 'gender', 'male']
]
这样的设计结构显然非常浪费存储空间。
为了提高存储空间的利用率,现在的python的哈希表会把索引和哈希值、键、值单独分开存储,也就是下面这样新的结构:
| Indices | |||||||
|---|---|---|---|---|---|---|---|
| None | index | None | None | index | None | index | … |
| Entries | ||
|---|---|---|
| hash0 | key0 | value0 |
| hash1 | key1 | value1 |
| hash2 | key2 | value2 |
| … |
在这个新结构下,对于上面的那个字典,存储形式会变成下面这个样子:
indices = [None, 1, None, None, 0, None, 2]
entries = [
[1231236123, 'name', 'xiaohua'],
[-230273521, 'date', '1999-01-01'],
[9371539127, 'gender', 'male']
]
可以很清晰地看到,空间利用率得到很大的提高。
而对于集合,哈希表仅存储了单一的元素存储结构:
| Entries | |||||||
|---|---|---|---|---|---|---|---|
| None | data | None | None | data | None | data | … |
例如,对于集合:
{'name', 'date', 'gender'}
存储形式类似于:
entries = [None, 'date', None, None, 'name', None, 'gender']
从上面的存储形式可以看出,字典可以通过顺序遍历entries保存原有的插入顺序,而集合则是无序的。
字典和集合高效的原因是利用了数组按照下标随机访问的时候时间复杂度是 O(1) 的特性。
字典和集合的操作原理
插入操作
每次向字典或集合插入一个元素时,Python 会首先计算键的哈希值(hash(key)),再和 mask = PyDicMinSize - 1 做与操作,计算这个元素应该插入哈希表的位置 index = hash(key) & mask。如果哈希表中此位置是空的,那么这个元素就会被插入其中。
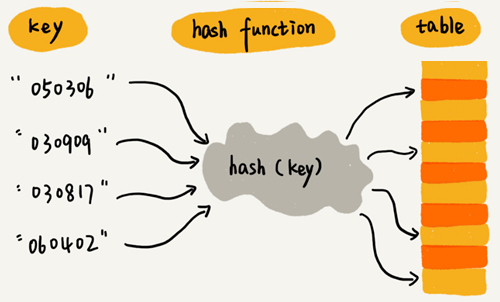
而如果此位置已被占用,Python 便会比较两个元素的哈希值和键是否相等。
- 若两者都相等,则表明这个元素已经存在,如果值不同,则更新值。
- 若两者中有一个不相等,这种情况我们通常称为哈希冲突(hash collision),意思是两个元素的键不相等,但是哈希值相等。常用的哈希冲突解决方法有开放寻址法(open addressing)和链表法(chaining)两类,新版本的python采用的应该是开放寻址法。
而开放寻址法中探测新的位置的方法又分为线性探测(Linear Probing)、二次探测(Quadratic probing)和双重散列(Double hashing),关于Python内部的具体的实现方法还需看源码才能知道。有兴趣研究的读者可以研究一下,源码地址是:
https://github.com/python/cpython/blob/949fe976d5c62ae63ed505ecf729f815d0baccfc/Include/dictobject.h
https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Objects/dictobject.c
下面简单说说线性探测的实现,下图黄色的色块表示空闲位置,橙色的色块表示已经存储了数据:
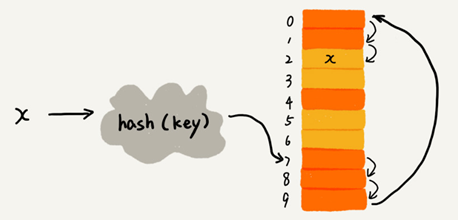
上图中哈希表的大小为 10,在元素 x 插入哈希表之前,已经 6 个元素插入到哈希表中。x 经过 Hash 算法计算出插入位置为下标 7 ,但是这个位置已经有数据了,所以就产生了冲突。于是就顺序地往后一个一个找,遍历到尾部都没有找到空闲的位置,再从表头开始找,直到找到空闲位置 2,于是将其插入到这个位置。
查找操作
和前面的插入操作类似,Python 会根据哈希值,找到其应该处于的位置;然后,比较哈希表这个位置中元素的哈希值和键,与需要查找的元素是否相等。如果相等,则直接返回;如果不等,则继续查找,直到找到空位或者抛出异常为止。
删除操作
对于删除操作,Python 会暂时对这个位置的元素,赋于一个特殊的值,等到重新调整哈希表的大小时,再将其删除。
不难理解,哈希冲突的发生,往往会降低字典和集合操作的速度。因此,为了保证其高效性,字典和集合内的哈希表,通常会保证其至少留有 1/3 的剩余空间。随着元素的不停插入,当剩余空间小于 1/3 时,Python 会重新获取更大的内存空间,扩充哈希表。不过,这种情况下,表内所有的元素位置都会被重新排放。
虽然哈希冲突和哈希表大小的调整,都会导致速度减缓,但是这种情况发生的次数极少。所以,平均情况下,这仍能保证插入、查找和删除的时间复杂度为 O(1)。
总结
这期我简单讲解了集合和字典的基本操作方法,并对它们的内部存储结构进行了基本的剖析。
希望作为读者的你,看完后能学有所获,也欢迎你在下方评论区留言或评论分享你的学习心得或是学习笔记。
我是分享知识的小小明,咱们下次再见!