0. 前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 闲庭信步
源自:https://blog.csdn.net/danspace1/article/details/80197106
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
本文从拉勾网爬取深圳市数据分析的职位信息,并以CSV格式保存至电脑,之后进行数据清洗,生成词云,进行描述统计和回归分析,最终得出结论。
1. 用到的软件包
- Python版本: Python3.6
- requests:下载网页
- math:向上取整
- time:暂停进程
- pandas:数据分析并保存为csv文件
- matplotlib:画图
- statsmodels:统计建模
- wordcloud、scipy、jieba:生成中文词云
- pylab:设置画图能显示中文
2. 解析网页
打开Chrome,在拉勾网搜索深圳市的“数据分析”职位,使用检查功能查看网页源代码,发现拉勾网有反爬虫机制,职位信息并不在源代码里,而是保存在JSON的文件里,因此我们直接下载JSON,并使用字典方法直接读取数据。

抓取网页时,需要加上头部信息,才能获取所需的数据。
def get_json(url,num):
'''''从网页获取JSON,使用POST请求,加上头部信息'''
my_headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With':'XMLHttpRequest'
}
my_data = {
'first': 'true',
'pn':num,
'kd':'数据分析'}
res = requests.post(url, headers = my_headers, data = my_data)
res.raise_for_status()
res.encoding = 'utf-8'
# 得到包含职位信息的字典
page = res.json()
return page
在搜索结果的第一页,我们可以从JSON里读取总职位数,按照每页15个职位,获得要爬取的页数。再使用循环按页爬取,将职位信息汇总,输出为CSV格式。
程序运行如图:
抓取结果如图:

3. 数据清洗
数据清洗占数据分析工作量的大头。在拉勾网搜索深圳市的“数据分析”职位,结果得到369个职位。查看职位名称时,发现有4个实习岗位。由于我们研究的是全职岗位,所以先将实习岗位剔除。由于工作经验和工资都是字符串形式的区间,我们先用正则表达式提取数值,输出列表形式。工作经验取均值,工资取区间的四分位数值,比较接近现实。
# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['工作年限'] = df['工作经验'].str.findall(pattern)
avg_work_year = []
for i in df['工作年限']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['经验'] = avg_work_year
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['工资'].str.findall(pattern)
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary
# 将清洗后的数据保存,以便检查
df.to_csv('draft.csv', index = False)
4. 词云
我们将职位福利这一列的数据汇总,生成一个字符串,按照词频生成词云实现python可视化。以下是原图和词云的对比图,可见五险一金在职位福利里出现的频率最高,平台、福利、发展空间、弹性工作次之。

5. 描述统计
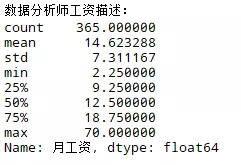
可知,数据分析师的均值在14.6K,中位数在12.5K,算是较有前途的职业。数据分析散布在各个行业,但在高级层面上涉及到数据挖掘和机器学习,在IT业有长足的发展。
我们再来看工资的分布,这对于求职来讲是重要的参考:

工资在10-15K的职位最多,在15-20K的职位其次。个人愚见,10-15K的职位以建模为主,20K以上的职位以数据挖掘、大数据架构为主。
我们再来看职位在各区的分布:

数据分析职位有62.9%在南山区,有25.8%在福田区,剩下少数分布在龙岗区、罗湖区、宝安区、龙华新区。我们以小窥大,可知南山区和福田区是深圳市科技业的中心。
6. 实证统计
我们希望获得工资与工作经验、学历的关系,由于学历分三类,需设置3个虚拟变量:大专、本科、硕士。多元回归结果如下:

在0.05的显著性水平下,F值为82.53,说明回归关系是显著的。t检验和对应的P值都小于0.05表明,工作经验和3种学历在统计上都是显著的。另外,R-squared的值为0.41,说明工作经验和学历仅仅解释了工资变异性的41%。这点不难理解,即使职位都叫数据分析师,实际的工作内容差异比较大,有的只是用Excel做基本分析,有的用Python、R做数据挖掘。另外,各个公司的规模和它愿意开出的工资也不尽相同。而工作内容的差异和公司的大方程度是很难单凭招聘网页上的宣传而获得实际数据,导致了模型的拟合优度不是很好这一现实。
由于回归模型总体是显著的,我们可以将自变量的值代入回归方程,获得各个学历的工资的期望值E。对于数据分析职位,以1年工作经验为例,大专学历的期望工资是7.8K,本科学历的期望工资是10.8K,硕士学历的期望工资是17.6K。这证实了“知识改变命运”这一说法。
7. 完整代码
由于每次运行爬虫耗时约30分钟,而运行数据分析耗时几秒钟,我们将两部分的工作单独运行,以节省数据分析的时间。
7.1 爬虫部分的代码
import requests
import math
import pandas as pd
import time
'''
python学习交流群:1136201545更多学习资料可以加群获取
'''
def get_json(url,num):
'''''从网页获取JSON,使用POST请求,加上头部信息'''
my_headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With':'XMLHttpRequest'
}
my_data = {
'first': 'true',
'pn':num,
'kd':'数据分析'}
res = requests.post(url, headers = my_headers, data = my_data)
res.raise_for_status()
res.encoding = 'utf-8'
# 得到包含职位信息的字典
page = res.json()
return page
def get_page_num(count):
'''''计算要抓取的页数'''
# 每页15个职位,向上取整
res = math.ceil(count/15)
# 拉勾网最多显示30页结果
if res > 30:
return 30
else:
return res
def get_page_info(jobs_list):
'''''对一个网页的职位信息进行解析,返回列表'''
page_info_list = []
for i in jobs_list:
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
page_info_list.append(job_info)
return page_info_list
def main():
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
# 先设定页数为1,获取总的职位数
page_1 = get_json(url,1)
total_count = page_1['content']['positionResult']['totalCount']
num = get_page_num(total_count)
total_info = []
time.sleep(20)
print('职位总数:{},页数:{}'.format(total_count,num))
for n in range(1,num+1):
# 对每个网页读取JSON, 获取每页数据
page = get_json(url,n)
jobs_list = page['content']['positionResult']['result']
page_info = get_page_info(jobs_list)
total_info += page_info
print('已经抓取第{}页, 职位总数:{}'.format(n, len(total_info)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(30)
#将总数据转化为data frame再输出
df = pd.DataFrame(data = total_info,columns = ['公司全名','公司简称','公司规模','融资阶段','区域','职位名称','工作经验','学历要求','工资','职位福利'])
df.to_csv('lagou_jobs.csv',index = False)
print('已保存为csv文件.')
if __name__== "__main__":
main()
7.2 数据分析部分的代码
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
from pylab import mpl
'''
python学习交流群:1136201545更多学习资料可以加群获取
'''
# 使matplotlib模块能显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
df = pd.read_csv('lagou_jobs.csv', encoding = 'gbk')
# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['工作年限'] = df['工作经验'].str.findall(pattern)
avg_work_year = []
for i in df['工作年限']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['经验'] = avg_work_year
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['工资'].str.findall(pattern)
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary
# 将清洗后的数据保存,以便检查
df.to_csv('draft.csv', index = False)
# 描述统计
print('数据分析师工资描述:\n{}'.format(df['月工资'].describe()))
# 绘制频率直方图并保存
plt.hist(df['月工资'],bins = 12)
plt.xlabel('工资 (千元)')
plt.ylabel('频数')
plt.title("工资直方图")
plt.savefig('histogram.jpg')
plt.show()
# 绘制饼图并保存
count = df['区域'].value_counts()
# 将龙华区和龙华新区的数据汇总
count['龙华新区'] += count['龙华区']
del count['龙华区']
plt.pie(count, labels = count.keys(),labeldistance=1.4,autopct='%2.1f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show()
# 绘制词云,将职位福利中的字符串汇总
text = ''
for line in df['职位福利']:
text += line
# 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))
color_mask = imread('cloud.jpg') #设置背景图
cloud = WordCloud(
font_path = 'yahei.ttf',
background_color = 'white',
mask = color_mask,
max_words = 1000,
max_font_size = 100
)
word_cloud = cloud.generate(cut_text)
# 保存词云图片
word_cloud.to_file('word_cloud.jpg')
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
# 实证统计,将学历不限的职位要求认定为最低学历:大专
df['学历要求'] = df['学历要求'].replace('不限','大专')
# 学历分为大专\本科\硕士,将它们设定为虚拟变量
dummy_edu = pd.get_dummies(df['学历要求'],prefix = '学历')
# 构建回归数组
df_with_dummy = pd.concat([df['月工资'],df['经验'],dummy_edu],axis = 1)
# 建立多元回归模型
y = df_with_dummy['月工资']
X = df_with_dummy[['经验','学历_大专','学历_本科','学历_硕士']]
X=sm.add_constant(X)
model = sm.OLS(y,X)
results = model.fit()
print('回归方程的参数:\n{}\n'.format(results.params))
print('回归结果:\n{}'.format(results.summary()))