商品亲和性分析
亲和性分析根据样本个体之间的关系,确定它们关系的亲疏。它主要根据两个指标统计商品之间的亲和性:
- 支持度:支持度指的是数据集中规则应验的次数。(商品交易中同时买A商品和B商品的交易数量【支持度也可以为次数/交易总量】)
- 置信度:置信度代表的是规则的准确性如何。(既买A商品又买B商品的数量除以买A商品的数量)
首先,我们使用Pandas读取数据集:
import pandas as pd
from itertools import combinations
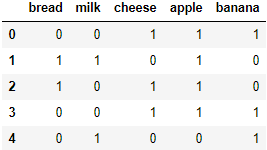
features = ["bread", "milk", "cheese", "apple", "banana"]
df = pd.read_csv("affinity_dataset.txt", sep="\s+",
header=None, names=features)
df.head()
数据集下载链接:https://pan.baidu.com/s/1rmgqvXeo8kCA-G89Cck7fw 密码:t3bu
也可以通过以下代码生成随机数据:
import numpy as np
X = np.c_[np.random.random(100) < 0.3, np.random.random(100) < 0.5,
np.random.random(100) < 0.2, np.random.random(100) < 0.25,
np.random.random(100) < 0.5]
X[X.sum(axis=1) == 0, 4] = 1
print(X[:5])
np.savetxt("affinity_dataset.txt", X, fmt="%d")
每一行代表每一条交易包含的商品,0代表没有购买,1代表购买。
下面我们首先计算出所有商品A和商品B之间的支持度(同时买A商品和B商品的交易数量):
data = []
for i, j in combinations(range(df.shape[1]), 2):
support = df.iloc[:, [i, j]].all(axis=1).sum()
data.append((i, j, support))
data.append((j, i, support))
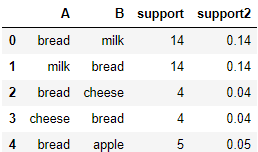
data = pd.DataFrame(data, columns=["A", "B", "support"])
data.A = pd.Categorical.from_codes(data.A, features)
data.B = pd.Categorical.from_codes(data.B, features)
data.head()

支持度也可以为次数/交易总量:
data['support2'] = data.support/df.shape[0]
data.head()
下面计算置信度(既买A商品又买B商品的数量除以买A商品的数量)。
首先我们计算出每个商品被购买的总次数:
num_occurances = df.sum()
num_occurances
bread 27
milk 46
cheese 41
apple 36
banana 59
dtype: int64
然后再来计算置信度:
data["confidence"] = data.support/num_occurances[data.A].values
data.head()
| A | B | support | support2 | confidence | |
|---|---|---|---|---|---|
| 0 | bread | milk | 14 | 0.14 | 0.518519 |
| 1 | milk | bread | 14 | 0.14 | 0.304348 |
| 2 | bread | cheese | 4 | 0.04 | 0.148148 |
| 3 | cheese | bread | 4 | 0.04 | 0.097561 |
| 4 | bread | apple | 5 | 0.05 | 0.185185 |
下面我们排序获取支持度前5的数据:
data.sort_values(["support", "confidence"], ascending=False, inplace=True)
data.head()
| A | B | support | support2 | confidence | |
|---|---|---|---|---|---|
| 16 | cheese | banana | 27 | 0.27 | 0.658537 |
| 17 | banana | cheese | 27 | 0.27 | 0.457627 |
| 15 | apple | cheese | 25 | 0.25 | 0.694444 |
| 14 | cheese | apple | 25 | 0.25 | 0.609756 |
| 18 | apple | banana | 21 | 0.21 | 0.583333 |
这就是商品的亲和性分析,对于分析商品两两之间的关系非常简单高效,但也很有局限性,例如不能挖掘出关联度很高的三个以上的商品,这时我们就可以使用相对复杂的关联规则模型来处理。
基于关联规则的Apriori算法
Agrawal等人在1993年提出关联规则的概念后,又在1994年提出了基于关联规则的 Apriori 算法,至今 Apriori 仍是关联规则挖掘的重要算法。
关联规则挖掘用于发现项与项(item 与 item)之间的关系,例如从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。
Apriori算法的三个基本指标是:
- 支持度:1个或多个商品组合出现的次数,或与总次数之间的比例。
- 置信度: 购买A商品的订单中,同时购买B商品的订单比例。
- 提升度:提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
注意:Apriori算法中支持度和置信度的概念与亲和性分析中支持度和置信度的概念含义几乎相同。
关联规则中的支持度、置信度和提升度
下面是5名客户购买的商品列表,我们以以下数据为例来说明这三个指标的具体概念:
data = [('牛奶', '面包', '尿布'),
('可乐', '面包', '尿布', '啤酒'),
('牛奶', '尿布', '啤酒', '鸡蛋'),
('面包', '牛奶', '尿布', '啤酒'),
('面包', '牛奶', '尿布', '可乐')]
将其转换为与前面商品亲和性分析时一致的数据形式:
import pandas as pd
import numpy as np
from itertools import chain,combinations
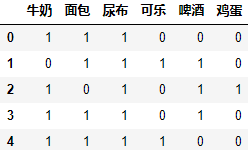
columns = pd.Index(chain(*data)).unique()
zero_matrix = np.zeros((len(data), len(columns)), dtype='int8')
for i, rows in enumerate(data):
t = columns.get_indexer(rows)
zero_matrix[i, t] = 1
df = pd.DataFrame(zero_matrix, columns=columns)
df
支持度
支持度指的是某个商品组合出现的次数,或与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
在亲和性分析中,我们只计算K=2的情况,在关联规则挖掘中,k=N的情况都需要计算。
下面我们一次性计算K=N各种情况下的支持度:
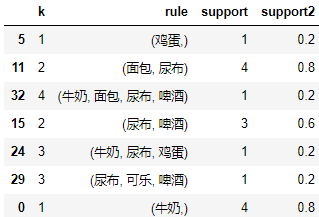
rule = []
for k in range(1, len(columns)+1):
for keys in combinations(columns, k):
value = df.loc[:, keys].all(axis=1).sum()
if value > 0:
rule.append((k, keys, value))
rule = pd.DataFrame(rule, columns=["k", "rule", "support"])
rule['support2'] = rule.support/df.shape[0]
rule.sample(7)
获取支持度查询字典,方便后面计算:
support = rule.set_index("rule").support2
置信度
置信度是个条件概念,即在 A 发生的情况下,B 发生的概率是多少。
即购买了商品A的订单中,同时购买商品B的订单比例。
置信度(A→B)=支持度(A,B)/支持度(A)
例如,置信度(牛奶→啤酒)= 支持度(牛奶,啤酒)/支持度(牛奶):
support[('牛奶', '啤酒')]/support[('牛奶',)]
0.5
置信度(啤酒→牛奶)= 支持度(牛奶,啤酒)/支持度(啤酒):
support[('牛奶', '啤酒')]/support[('啤酒',)]
0.6666666666666667
提升度
提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升的”程度。
提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)=支持度(A,B)/支持度(A)/支持度(B)
提升度 (B→A)= 置信度 (B→A)/ 支持度 (A)=支持度(A,B)/支持度(B)/支持度(A)
因此,提升度 (A→B)=提升度 (B→A)=支持度(A,B)/支持度(A)/支持度(B)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升:
- 提升度 (A→B)>1:代表有提升;
- 提升度 (A→B)=1:代表有没有提升,也没有下降;
- 提升度 (A→B)<1:代表有下降。
例如,提升度(牛奶→啤酒)=提升度(啤酒→牛奶)=支持度(牛奶,啤酒) / 支持度(牛奶)/ 支持度(啤酒):
support[('牛奶', '啤酒')]/support[('牛奶',)]/support[('啤酒',)]
0.8333333333333334
提升度(可乐→尿布)=支持度(可乐,尿布)/支持度(可乐)/支持度(尿布):
support[('尿布', '可乐')]/support[('可乐',)]/support[('尿布',)]
1.0
Apriori 算法的简介与工具使用
项集叫做itemset,它可以是单个的商品,也可以是商品的组合。
频繁项集是支持度大于等于最小支持度 (Min Support) 阈值的项集,非频繁项集就是支持度小于最小支持度阈值的项集。
Apriori 算法就是查找频繁项集 (frequent itemset) 的过程。
Apriori 算法的递归流程:
- K=1,计算 K 项集的支持度;
- 筛选掉小于最小支持度的项集;
- 如果项集为空,则对应 K-1 项集的结果为最终结果。
如果项集不为空,K=K+1,回到第一步重复执行。
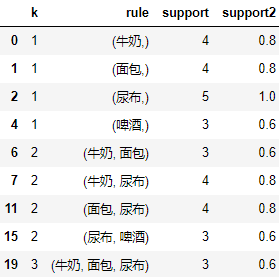
假设指定最小支持度是 50%,最终得到的全部频繁项集为:
itemset = rule.query("support2>=0.5")
itemset
efficient-apriori工具包可以很方便的使用Apriori 算法,使用如下命令安装:
pip install efficient-apriori
下面使用efficient-apriori计算最小支持度是50%的频繁集项:
from efficient_apriori.itemsets import itemsets_from_transactions
itemsets, num_trans = itemsets_from_transactions(data, min_support=0.5)
print("总条数:",num_trans)
itemsets
总条数: 5
{1: {('牛奶',): 4, ('面包',): 4, ('尿布',): 5, ('啤酒',): 3},
2: {('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3, ('啤酒', '尿布'): 3},
3: {('尿布', '牛奶', '面包'): 3}}
下面根据频繁集项和最低置信度要求生成频繁规则:
from efficient_apriori.rules import generate_rules_apriori
rules = list(generate_rules_apriori(
itemsets, min_confidence=0.5, num_transactions=num_trans))
rules
[{牛奶} -> {尿布},
{尿布} -> {牛奶},
{面包} -> {尿布},
{尿布} -> {面包},
{面包} -> {牛奶},
{牛奶} -> {面包},
{尿布} -> {啤酒},
{啤酒} -> {尿布},
{牛奶, 面包} -> {尿布},
{尿布, 面包} -> {牛奶},
{尿布, 牛奶} -> {面包},
{面包} -> {尿布, 牛奶},
{牛奶} -> {尿布, 面包},
{尿布} -> {牛奶, 面包}]
当然也可以一次性将频繁项集和频繁规则都计算出来:
from efficient_apriori import apriori
itemsets, rules = apriori(data, min_support=0.5, min_confidence=0.5)
print(itemsets)
print("-----")
print(rules)
{1: {('牛奶',): 4, ('面包',): 4, ('尿布',): 5, ('啤酒',): 3}, 2: {('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3, ('啤酒', '尿布'): 3}, 3: {('尿布', '牛奶', '面包'): 3}}
-----
[{牛奶} -> {尿布}, {尿布} -> {牛奶}, {面包} -> {尿布}, {尿布} -> {面包}, {面包} -> {牛奶}, {牛奶} -> {面包}, {尿布} -> {啤酒}, {啤酒} -> {尿布}, {牛奶, 面包} -> {尿布}, {尿布, 面包} -> {牛奶}, {尿布, 牛奶} -> {面包}, {面包} -> {尿布, 牛奶}, {牛奶} -> {尿布, 面包}, {尿布} -> {牛奶, 面包}]
不过efficient_apriori包对数据形式有特殊要求,假如我们需要将文章开头商品亲和性分析所用到的数据集进行关联规则挖掘,需要对数据进行一定的转化:
features = ["bread", "milk", "cheese", "apple", "banana"]
df = pd.read_csv("affinity_dataset.txt", sep="\s+",
header=None, names=features)
df.head()
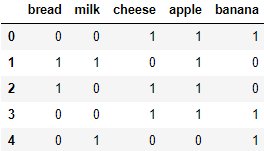
mask = df.columns
data = [tuple(mask[rows == 1]) for rows in df.values]
data[:5]
[('cheese', 'apple', 'banana'),
('bread', 'milk', 'apple'),
('bread', 'cheese', 'apple'),
('cheese', 'apple', 'banana'),
('milk', 'banana')]
然后就可以通过efficient-apriori包计算频繁项集和频繁规则:
itemsets, rules = apriori(data, min_support=0.2, min_confidence=0.1)
print(itemsets)
print("-----")
print(rules)
{1: {('banana',): 59, ('apple',): 36, ('cheese',): 41, ('milk',): 46, ('bread',): 27}, 2: {('apple', 'banana'): 21, ('apple', 'cheese'): 25, ('banana', 'cheese'): 27}}
-----
[{banana} -> {apple}, {apple} -> {banana}, {cheese} -> {apple}, {apple} -> {cheese}, {cheese} -> {banana}, {banana} -> {cheese}]
FP-Growth算法
简介与工具包使用
FP-Growth算法是基于Apriori改进的关联挖掘的算法,Apriori 在计算的过程有哪些缺点呢?
- 采用排列组合的方式,可能产生大量的候选集。
- 每次计算每个项集的支持度都需要重新扫描数据集。
FP-Growth算法的特点是:
- 创建了一棵 FP 树来存储频繁项集,在创建前对不满足最小支持度的项进行删除。
- 整个生成过程只遍历数据集 2 次。
当然 Apriori 的改进算法除了 FP-Growth 算法以外,还有 CBA 算法、GSP 算法,本文只介绍FP-Growth算法。
FP-Growth算法的原理较为复杂,下面我们先直接使用现有的包pyfpgrowth,直接使用FP-GROWTH算法进行关联规则挖掘。
安装:pip install pyfpgrowth
pyfpgrowth计算最小支持度是20%的频繁集项(pyfpgrowth的支持度用的是数量):
import pyfpgrowth as fp
patterns = fp.find_frequent_patterns(data, int(0.2*df.shape[0]))
patterns
{('bread',): 27,
('apple', 'banana'): 21,
('apple', 'cheese'): 25,
('cheese',): 41,
('banana', 'cheese'): 27,
('milk',): 46,
('banana',): 59}
pyfpgrowth计算最小支持度是10%的频繁规则:
fp.generate_association_rules(patterns, 0.1)
{('banana',): (('cheese',), 0.4576271186440678),
('cheese',): (('banana',), 0.6585365853658537)}
再计算另一个基础示例:
data = [('牛奶', '面包', '尿布'),
('可乐', '面包', '尿布', '啤酒'),
('牛奶', '尿布', '啤酒', '鸡蛋'),
('面包', '牛奶', '尿布', '啤酒'),
('面包', '牛奶', '尿布', '可乐')]
patterns = fp.find_frequent_patterns(data, int(0.5*len(data)))
patterns
{('可乐',): 2,
('可乐', '面包'): 2,
('可乐', '尿布'): 2,
('可乐', '尿布', '面包'): 2,
('啤酒', '面包'): 2,
('啤酒', '尿布', '面包'): 2,
('啤酒', '牛奶'): 2,
('啤酒', '尿布', '牛奶'): 2,
('啤酒', '尿布'): 3,
('牛奶',): 4,
('尿布', '牛奶'): 4,
('牛奶', '面包'): 2,
('尿布', '牛奶', '面包'): 2,
('面包',): 4,
('尿布', '面包'): 4,
('尿布',): 5}
fp.generate_association_rules(patterns, 0.5)
{('可乐',): (('尿布', '面包'), 1.0),
('面包',): (('尿布',), 1.0),
('可乐', '尿布'): (('面包',), 1.0),
('可乐', '面包'): (('尿布',), 1.0),
('尿布', '面包'): (('牛奶',), 0.5),
('啤酒', '尿布'): (('牛奶',), 0.6666666666666666),
('啤酒', '面包'): (('尿布',), 1.0),
('牛奶',): (('尿布', '面包'), 0.5),
('啤酒', '牛奶'): (('尿布',), 1.0),
('尿布', '牛奶'): (('面包',), 0.5),
('尿布',): (('面包',), 0.8),
('牛奶', '面包'): (('尿布',), 1.0)}
FP-Growth算法的原理
整体过程如下:
- 创建项头表,对于满足最小支持度的单个项(K=1项集)按照支持度从高到低进行排序,同时删除不满足最小支持度的项。
- 构造 FP 树,根节点记为NULL节点,再次扫描数据集,对于每一条数据,按照支持度从高到低的顺序进行创建节点(项头表中的排序结果),并更新节点计数和项头表的链表。
- 通过 FP 树挖掘频繁项集,具体的操作运用“条件模式基”
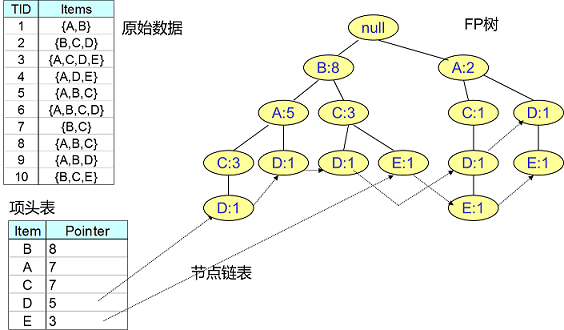
FP Tree数据结构
FP-Growth 算法涉及的数据结构包括三部分:
-
项头表:
里面记录了所有的1项频繁集出现的次数,按照次数降序排列。比如上图中B在所有10组数据中出现了8次,因此排在第一位。
-
FP Tree:
它将原始数据集映射到了内存中的一颗FP树
-
节点链表:
所有项头表里的1项频繁集都是一个节点链表的头,它依次指向FP树中该1项频繁集出现的位置。这样做主要是方便项头表和FP Tree之间的联系查找和更新。
项头表的建立
假设有10条数据,设置支持度为20%,第一次扫描数据并对1项集计数,发现F,O,I,L,J,P,M, N都只出现一次,支持度低于20%的阈值,直接删除。剩下的A,C,E,G,B,D,F按照支持度的大小降序排列,组成了项头表。
接着第二次扫描数据,对于每条数据剔除非频繁1项集,并按照支持度降序排列。比如数据项ABCEFO,里面O是非频繁1项集,因此被剔除,只剩下了ABCEF。按照支持度的顺序排序,它变成了ACEBF。
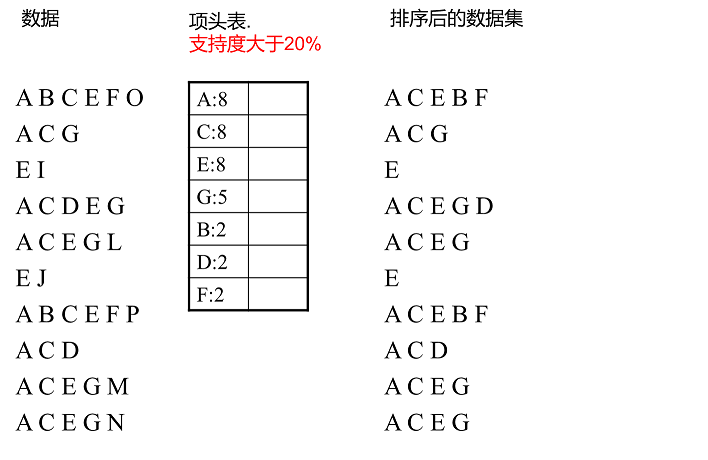
整体步骤:第一次扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。第二次扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
FP Tree的建立
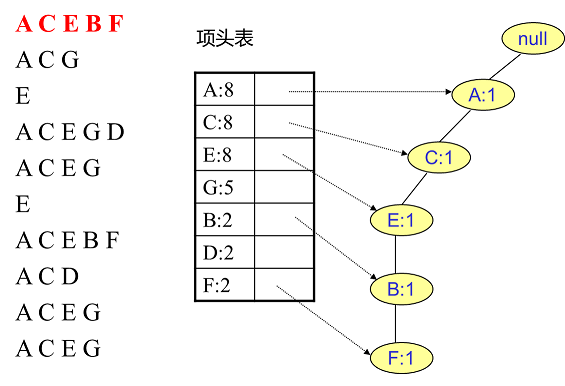
首先将FP树的根节点设置为null,然后读入第一条数据ACEBF作为一条独立的路径插入到FP树中,所有节点计数为1, 项头表通过节点链表链接上对应的新增节点:
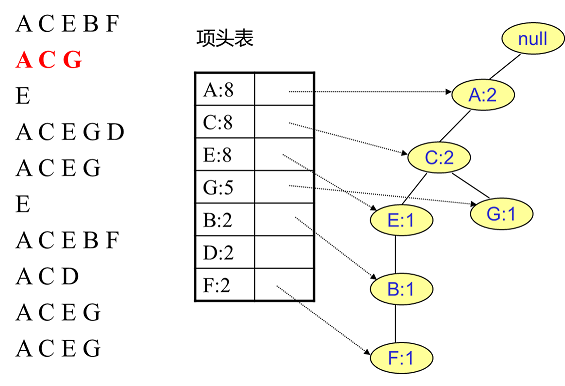
接着插入数据ACG,由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。对应的G节点的节点链表也要更新:
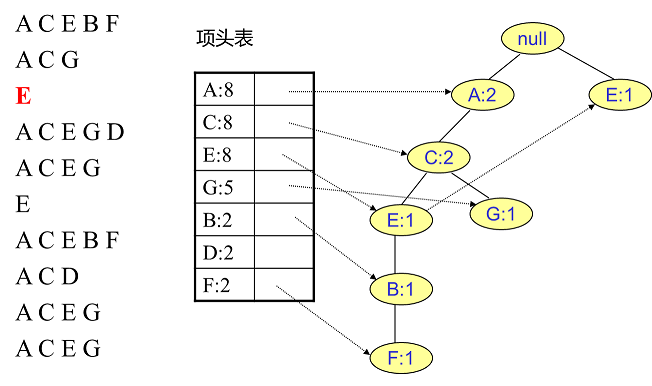
用同样的办法更新后面8条数据:
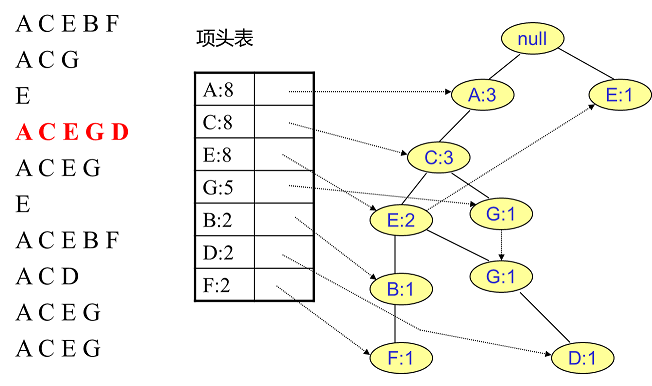
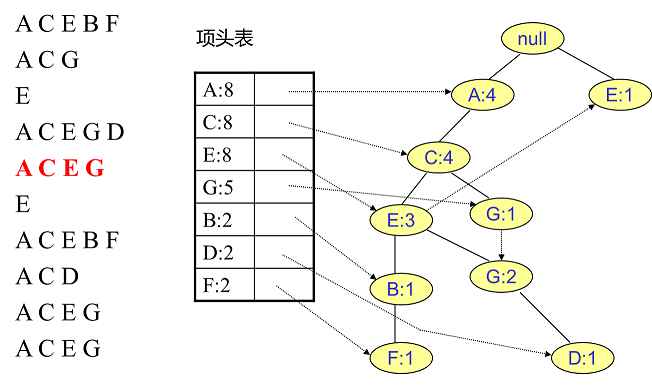
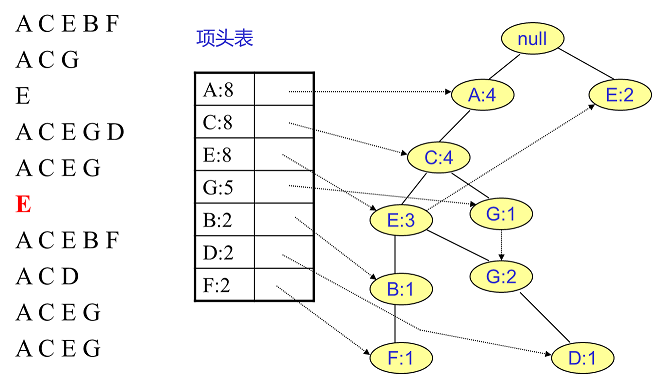
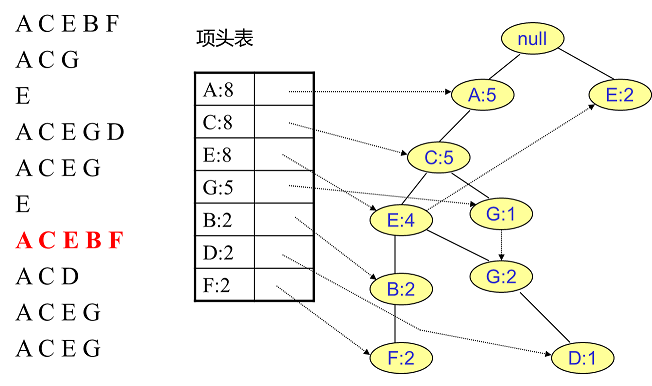
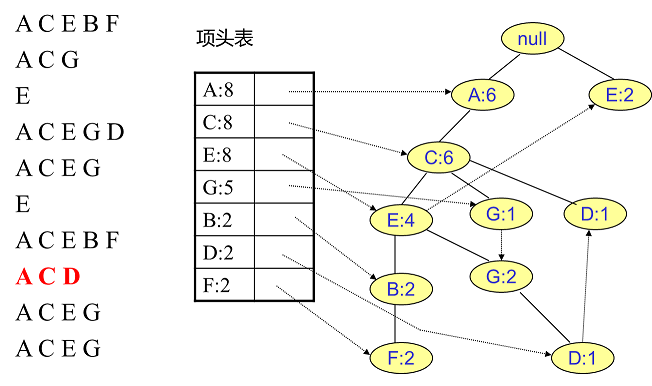
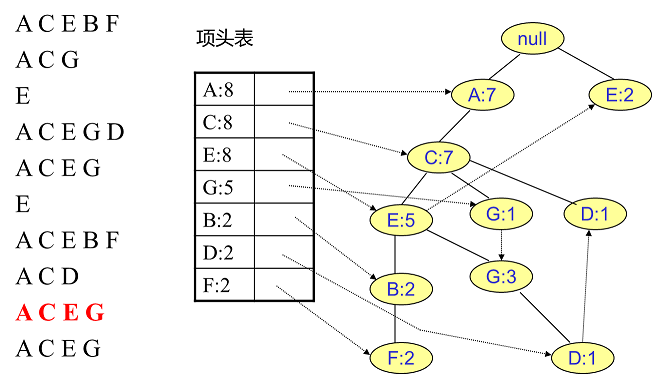
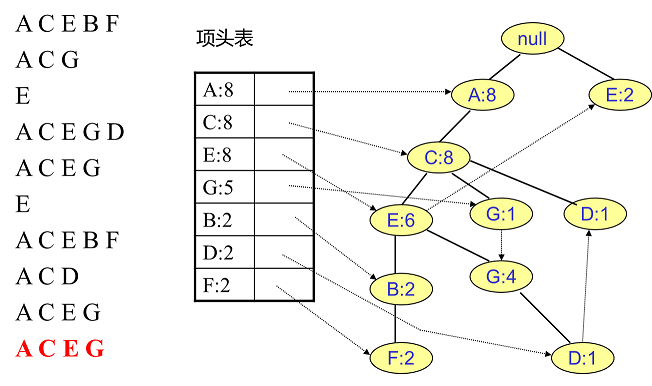
至此,FP树的建立完成。
整体步骤:逐条读入排序后的数据集,按照排序后的顺序插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
FP Tree的挖掘
整体步骤:得到了FP树和项头表以及节点链表,首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,要找到它的条件模式基。所谓条件模式基是以要挖掘的节点作为叶子节点所对应的FP子树。得到这个FP子树,将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。通过条件模式基就可以递归挖掘得到频繁项集。
先从最底下的F节点开始,寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2, F:2}。接着将所有的祖先节点计数设置为叶子节点的计数,即FP子树变成{A:2,C:2,E:2,B:2, F:2}。一般条件模式基可以不写叶子节点,因此最终的F的条件模式基如下图右所示:
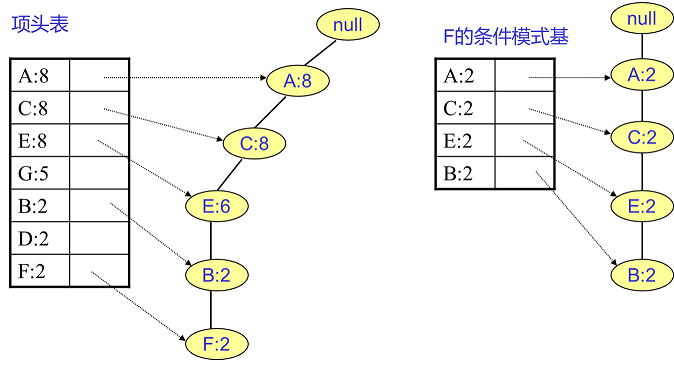
通过这个条件模式基很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},…还有一些频繁三项集。最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}
D节点有两个叶子节点比F节点复杂一些。首先得到的FP子树如下图左,接着将所有的祖先节点计数设置为叶子节点的计数,即变成{A:2, C:2,E:1 G:1,D:1, D:1},此时E节点和G节点由于在条件模式基里面的支持度低于阈值被删除掉,最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}。通过它,可得到F的频繁2项集为{A:2,D:2}, {C:2,D:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,D:2}。D对应的最大的频繁项集为频繁3项集。
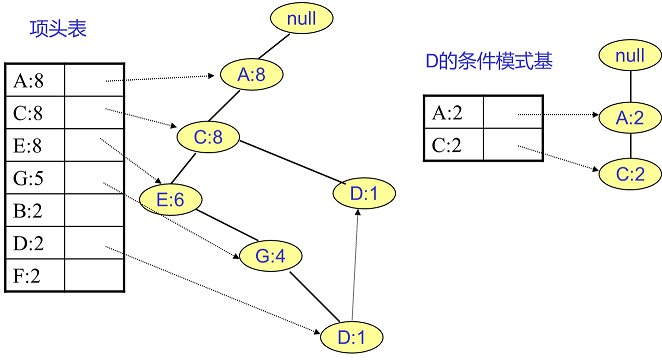
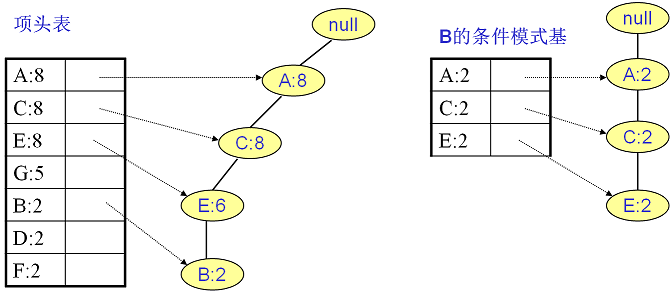
同样的方法可以得到B的条件模式基如下图右边,递归挖掘到B的最大频繁项集为频繁4项集{A:2, C:2, E:2,B:2}:
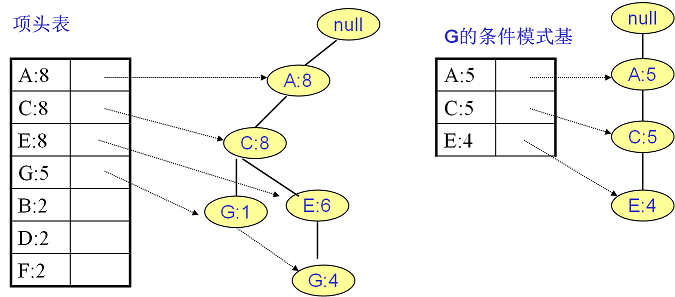
G的条件模式基如下图右边,递归挖掘到G的最大频繁项集为频繁4项集{A:5, C:5, E:4,G:4}:
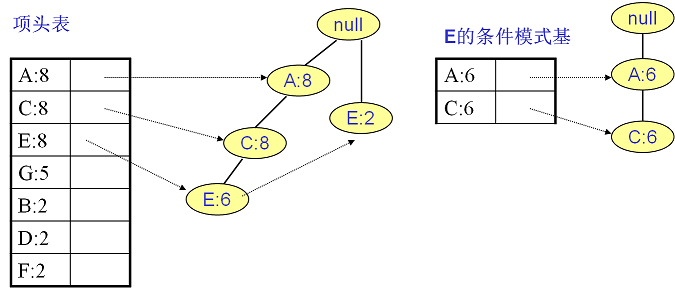
E的条件模式基如下图右边,递归挖掘到E的最大频繁项集为频繁3项集{A:6, C:6, E:6}。
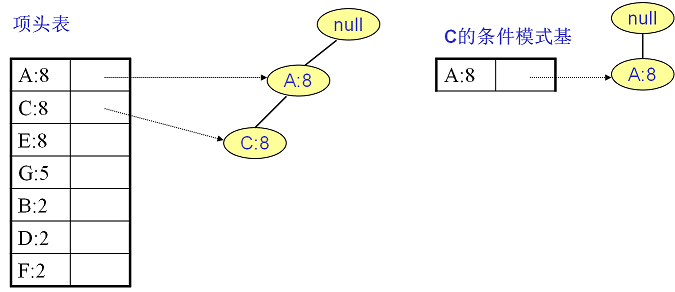
C的条件模式基如下图右边,递归挖掘到C的最大频繁项集为频繁2项集{A:8, C:8}。
A的条件模式基为空,因此不用去挖掘。
至此得到了所有的频繁项集,从上面的分析可以看到,最大的频繁项集为5项集。包括{A:2, C:2, E:2,B:2,F:2}。
案例:挖掘导演是如何选择演员的
接下来我们打算通过关联规则挖掘,分析导演选择演员的规律。
下面以张黎导演为例,首先在豆瓣爬取所需的数据:
豆瓣爬虫
打开https://search.douban.com/movie/subject_search?search_text=%E5%BC%A0%E9%BB%8E&cat=1002 ,爬取张黎导演的演员信息。
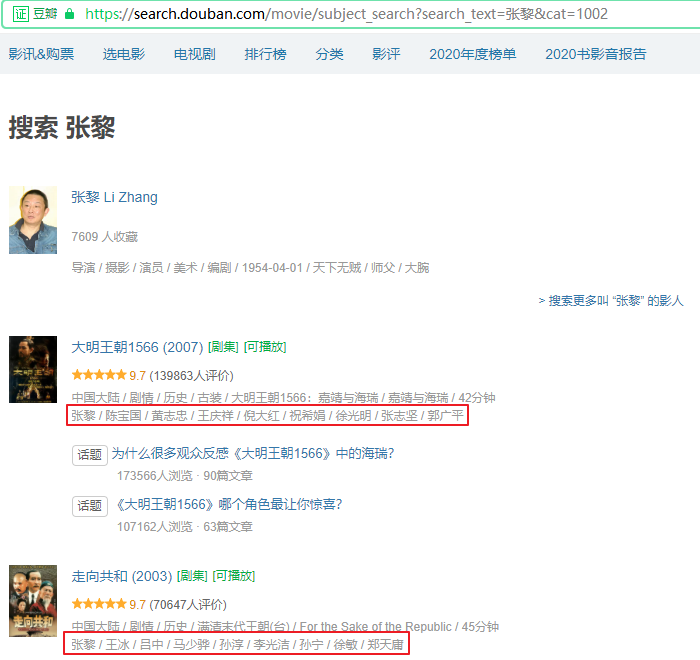
每条数据的最后一行是电影的演出人员的信息,第一个人员是导演,其余为演员姓名。姓名之间用“/”分割。显然不是演出人员的信息不是以张黎开头的,都不是张黎导演的电影,应该直接跳过。
由于 https://search.douban.com/movie/subject_search
页面使用了动态加载的方式,常规的Js分析很难一口气找到规律,这里直接用 selenium,比较方便。
selenium需要pip安装,我当前电脑未安装谷歌游览器,所以使用了PhantomJS。
Selenium和相应驱动的安装方法详见:https://blog.csdn.net/as604049322/article/details/114157526
from selenium import webdriver
from urllib.parse import quote
import time
from lxml import etree
import pandas as pd
from efficient_apriori import apriori
director = '张黎'
start = 0
url_template = 'https://search.douban.com/movie/subject_search?search_text={}&cat=1002&start={}'
driver = webdriver.PhantomJS()
result = []
while start < 1000:
url = url_template.format(quote(director), start)
print(url)
start += 15
driver.get(url)
time.sleep(1)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
html = etree.HTML(html)
movie_list = html.xpath("//div[@class='item-root']//div[@class='detail']")
for movie in movie_list:
name = movie.xpath(".//a[@class='title-text']/text()")
actors = movie.xpath("./div[@class='meta abstract_2']/text()")
# 不是目标导演导演的电影则跳过
if len(actors) == 0 or not actors[0].startswith(director):
continue
result.append((name[0].replace("\u200e ", ""),
actors[0].replace(" ", "")[len(director)+1:]))
if len(movie_list) < 14:
break
df = pd.DataFrame(result, columns=["name", "actors"])
# 清空演员为空的
df = df.query("actors!=''")
df
https://search.douban.com/movie/subject_search?search_text=%E5%BC%A0%E9%BB%8E&cat=1002&start=0
https://search.douban.com/movie/subject_search?search_text=%E5%BC%A0%E9%BB%8E&cat=1002&start=15
https://search.douban.com/movie/subject_search?search_text=%E5%BC%A0%E9%BB%8E&cat=1002&start=30
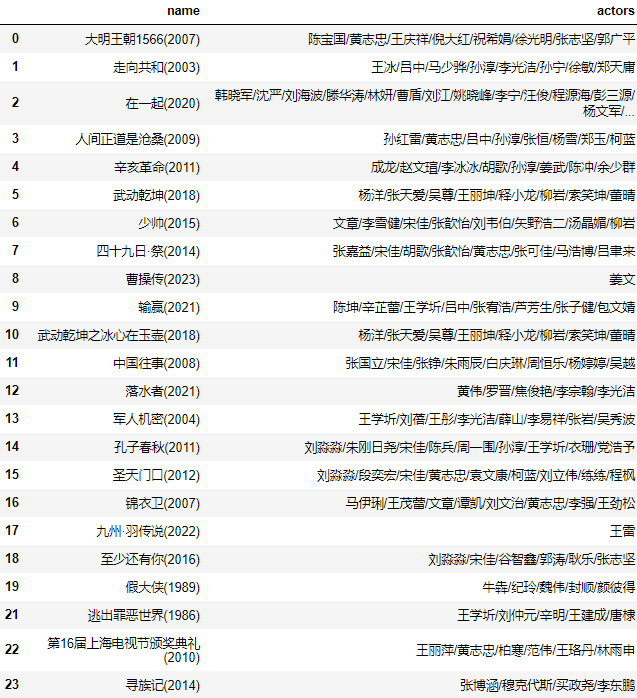
这样就爬到了张黎导演的电影,所选的演员有哪些,豆瓣的数据或许不全,但基本是够用了。
data = df.actors.str.split("/").to_list()
print(data)
[['陈宝国', '黄志忠', '王庆祥', '倪大红', '祝希娟', '徐光明', '张志坚', '郭广平'], ['王冰', '吕中', '马少骅', '孙淳', '李光洁', '孙宁', '徐敏', '郑天庸'], ['韩晓军', '沈严', '刘海波', '滕华涛', '林妍', '曹盾', '刘江', '姚晓峰', '李宁', '汪俊', '程源海', '彭三源', '杨文军', '杨阳', '张嘉益', '周一围', '谭卓', '张天爱', '何蓝逗', '梅婷', '雷佳音', '倪妮'], ['孙红雷', '黄志忠', '吕中', '孙淳', '张恒', '杨雪', '郑玉', '柯蓝'], ['成龙', '赵文瑄', '李冰冰', '胡歌', '孙淳', '姜武', '陈冲', '余少群'], ['杨洋', '张天爱', '吴尊', '王丽坤', '释小龙', '柳岩', '索笑坤', '董晴'], ['文章', '李雪健', '宋佳', '张歆怡', '刘韦伯', '矢野浩二', '汤晶媚', '柳岩'], ['张嘉益', '宋佳', '胡歌', '张歆怡', '黄志忠', '张可佳', '马浩博', '吕聿来'], ['姜文'], ['陈坤', '辛芷蕾', '王学圻', '吕中', '张宥浩', '芦芳生', '张子健', '包文婧'], ['杨洋', '张天爱', '吴尊', '王丽坤', '释小龙', '柳岩', '索笑坤', '董晴'], ['张国立', '宋佳', '张铮', '朱雨辰', '白庆琳', '周恒乐', '杨婷婷', '吴越'], ['黄伟', '罗晋', '焦俊艳', '李宗翰', '李光洁'], ['王学圻', '刘蓓', '王彤', '李光洁', '薛山', '李易祥', '张岩', '吴秀波'], ['刘淼淼', '朱刚日尧', '宋佳', '陈兵', '周一围', '孙淳', '王学圻', '衣珊', '党浩予'], ['刘淼淼', '段奕宏', '宋佳', '黄志忠', '袁文康', '柯蓝', '刘立伟', '练练', '程枫'], ['马伊琍', '王茂蕾', '文章', '谭凯', '刘文治', '黄志忠', '李强', '王劲松'], ['王雷'], ['刘淼淼', '宋佳', '谷智鑫', '郭涛', '耿乐', '张志坚'], ['牛犇', '纪玲', '魏伟', '封顺', '颜彼得'], ['王学圻', '刘仲元', '辛明', '王建成', '唐棣'], ['王丽萍', '黄志忠', '柏寒', '范伟', '王珞丹', '林雨申'], ['张博涵', '穆克代斯', '买政尧', '李东鹏']]
关联规则挖掘
爬到了演员列表信息后,我就可以通过FP-Growth算法挖掘张黎导演选择演员的规律。
# 挖掘频繁项集和关联规则
itemsets = fp.find_frequent_patterns(data, 3)
rules = fp.generate_association_rules(itemsets, 1)
print(itemsets)
print("--------")
print(rules)
{('吕中',): 3, ('李光洁',): 3, ('张天爱',): 3, ('柳岩',): 3, ('刘淼淼',): 3, ('刘淼淼', '宋佳'): 3, ('孙淳',): 4, ('王学圻',): 4, ('黄志忠',): 6, ('宋佳',): 6}
--------
{('刘淼淼',): (('宋佳',), 1.0)}
说明张黎导演在使用刘淼淼时,一般都会用宋佳。