本文就利用网站提供的数据,使用Neo4j(NOSQL图形数据库)进行实战一波。
获取分析
人物及人物关联信息从网站上获取,具体接口如下:
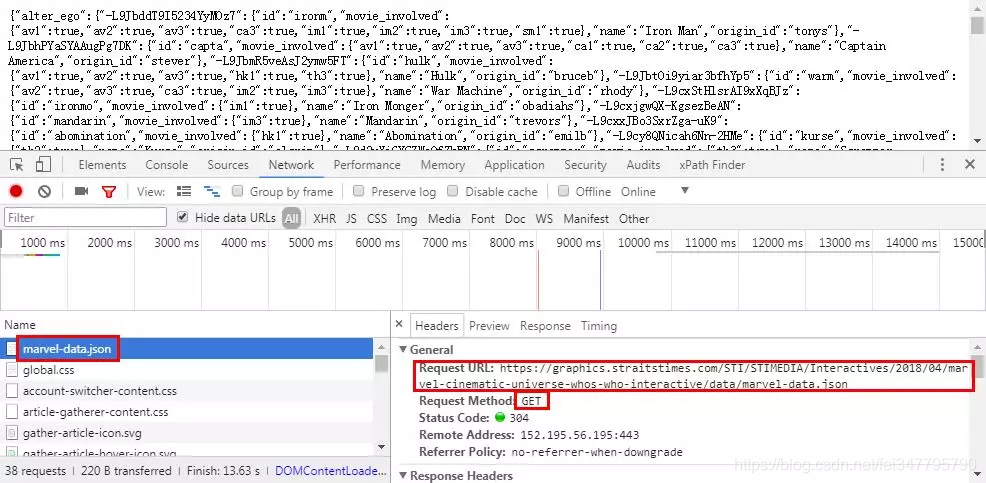
数据为JSON格式,分别在「characters」和「relationship」中。
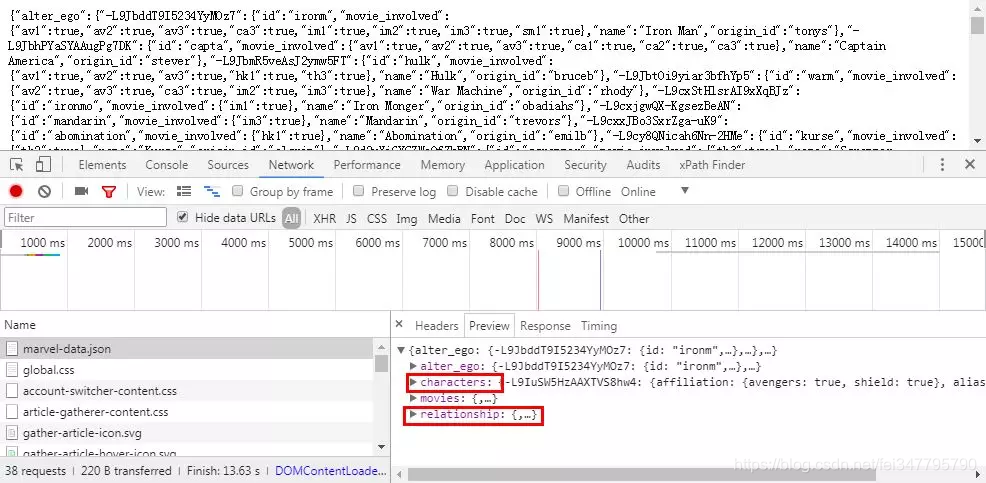
这里的信息是分别指托尼·斯达克,关系「0」为朋友,斯蒂文·罗杰斯。
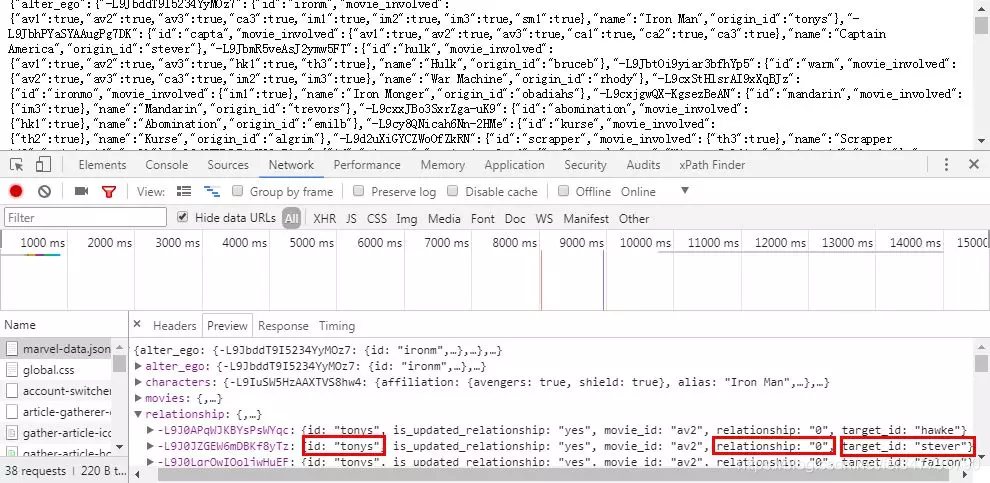
数据获取
具体代码如下:
import json
import requests
'''
python学习交流群:1136201545更多学习资料可以加群获取
'''
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
url = 'https://graphics.straitstimes.com/STI/STIMEDIA/Interactives/2018/04/marvel-cinematic-universe-whos-who-interactive/data/marvel-data.json'
response = requests.get(url=url, headers=headers)
result = json.loads(response.text)
num = 0
names = []
item = {0: 'friend', 1: 'enemy', 2: 'creation', 3: 'family', 4: 'work', 5: 'love'}
for i in result['relationship']:
subject = result['relationship'][i]['id']
object = result['relationship'][i]['target_id']
if subject not in names:
names.append(subject)
if object not in names:
names.append(object)
relation = int(result['relationship'][i]['relationship'])
with open('relation_message.csv', 'a+') as f:
f.write(subject + ',' + object + ',' + item[relation] + '\n')
for j in names:
num += 1
with open('names_message.csv', 'a+') as f:
f.write(j + ',' + str(num) + '\n')
for k in result['characters']:
id = result['characters'][k]['id']
name = result['characters'][k]['name']
status = result['characters'][k]['status']
species = result['characters'][k]['species']
with open('message.csv', 'a+') as f:
f.write(id + ',' + name + ',' + status + ',' + species + '\n')
最后成功获取数据。
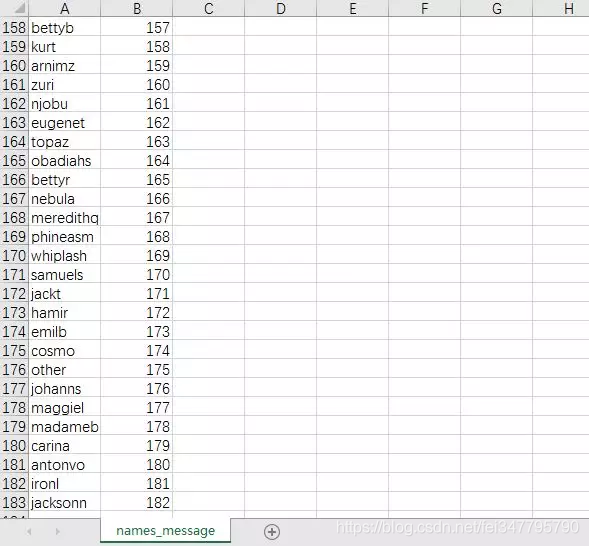
人物名为简称,共计182个人物。
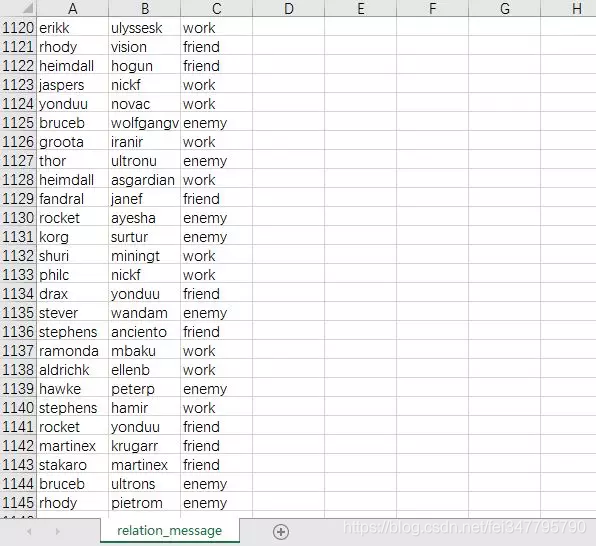
1144条人物关系数据,4大类型,下面是182个人物的一些详情信息:
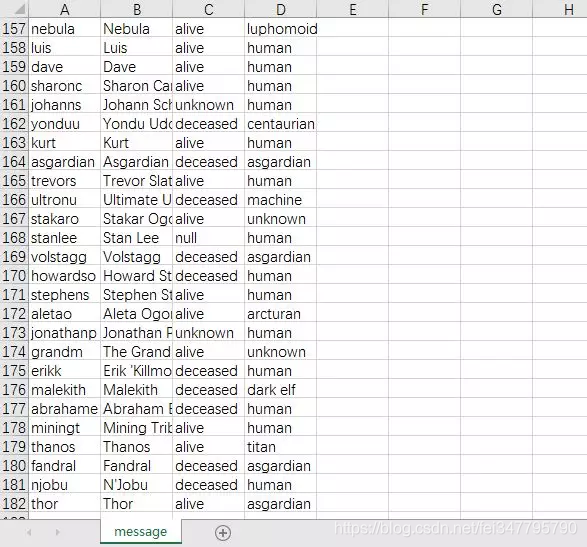
包含了人物的名字及简称,存活状态,人物属性。
数据可视化
下面通过Neo4j对人物关系进行可视化,Neo4j的安装这里就不细说了,大家可以自行百度。
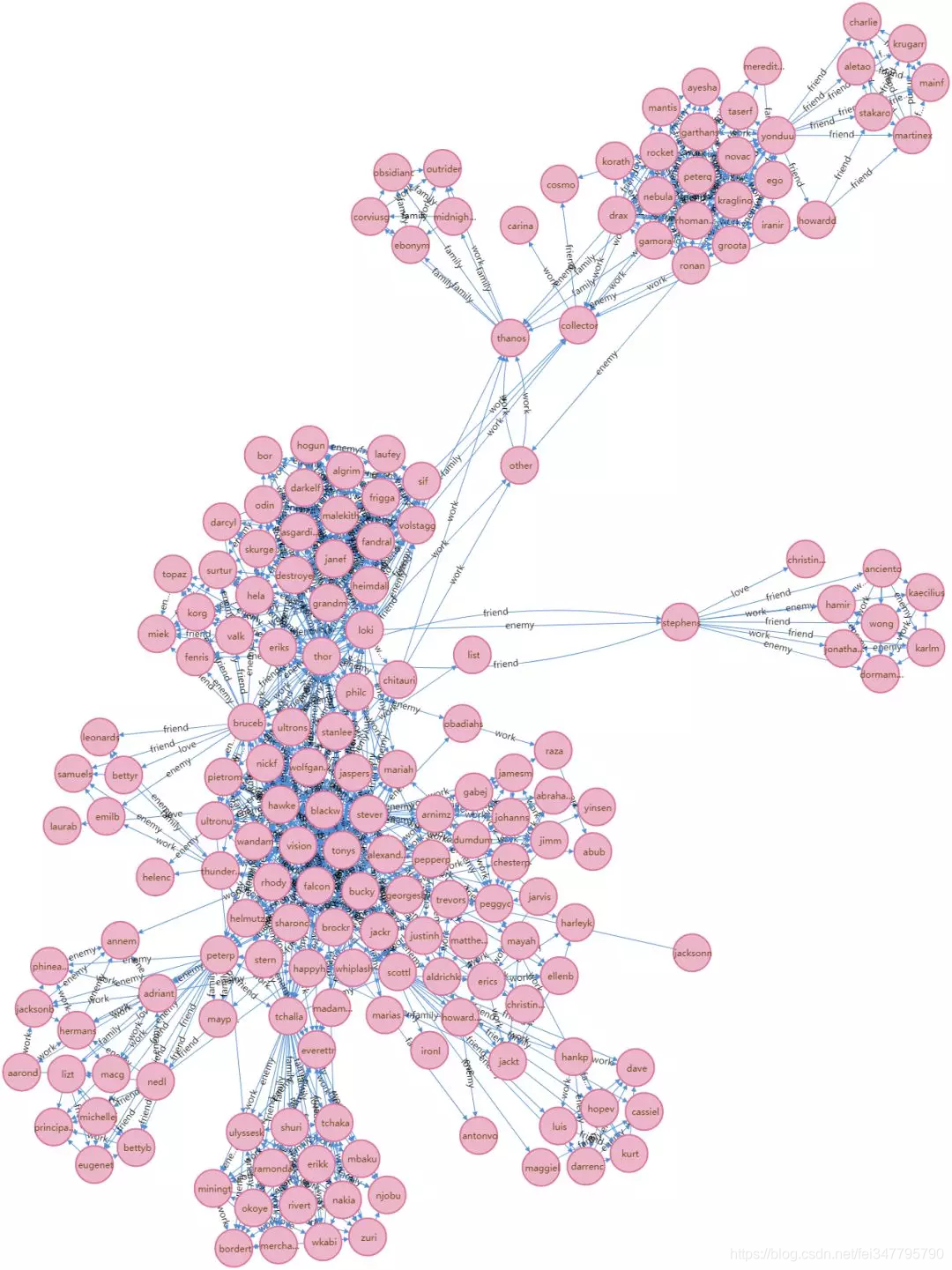
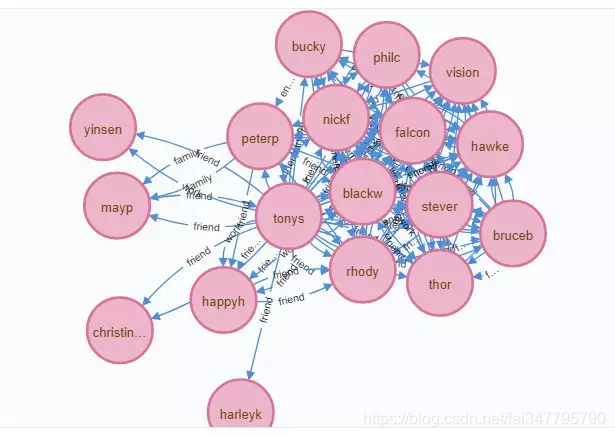
其中「thor」为「雷神」,「stever」为「美队」,「blackw」为「黑寡妇」,「vision」为「幻视」,「peterp」为「蜘蛛侠」,「bruceb」为「绿巨人」。