前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
我们要爬取豆瓣电影《肖申克的救赎》(如图1所示)上面的一些信息,网站地址是:
https://movie.douban.com/subject/1292052/

代码如下:
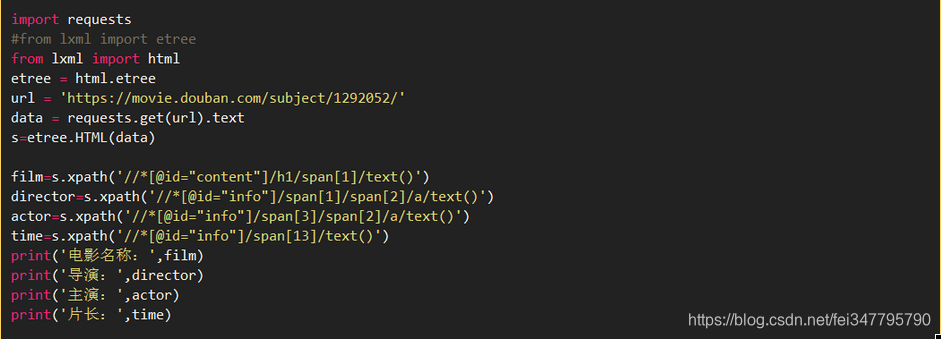
运行结果如图2所示

知识点和问题解决:
1、Xpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。***起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。
Xpath解析网页的流程:
1).首先通过Requests库获取网页数据
2).通过网页解析,得到想要的数据或者新的链接
3).网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 在是一个非常好用的网页解析工具
常见的网页解析方法比较:
正则表达式使用比较困难,学习成本较高,BeautifulSoup 性能较慢,相对于 Xpath 较难,在某些特定场景下有用。Xpath 使用简单,速度快(Xpath是lxml里面的一种),是入门最好的选择。
2、期初引入eTree的代码是
from lxml import etree
但是这样会报错的:虽然网上说的是python 3.5之后的lxml中不再有etree,但是其实这种说法是有问题的,虽然新版本无法直接from lxml import etree这样,但是它只不过是换了一个办法引出etree模块而已!
正确的引用方法是:这种方式就是新版本lxml中etree中的使用方法,不过使用过程中发现有一些方法无法直接自动匹配提示,对新手入门不是很友好而已。

3、我们在开发者模式中发现演员的Xpath是
//*[@id="info"]/span[3]/span[2]/span[1]/a
//*[@id="info"]/span[3]/span[2]/span[2]/a
//*[@id="info"]/span[3]/span[2]/span[4]/a
这样我们将他们进行集合取出的方法是:
//*[@id="info"]/span[3]/span[2]/a/text()
我们发现只有span[1]、span[2]、span[3]这部分是不同的,那我们将这部分合并或省略即可。