目标
爬取线报网站,并把内容保存到items.json里
页面分析
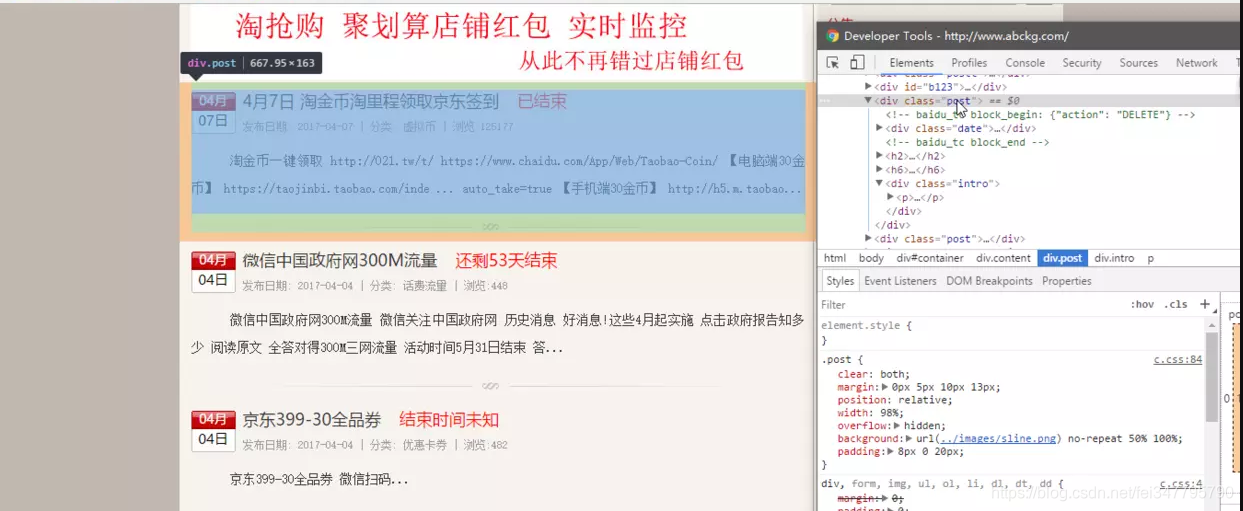
根据上图我们可以发现内容都在类为post这个div里
下面放出post的代码
<div class="post">
<!-- baidu_tc block_begin: {"action": "DELETE"} -->
<div class="date"><span>04月</span><span class="f">07日</span></div><!-- baidu_tc block_end -->
<h2><a href="http://www.abckg.com/193.html" title="4月7日 淘金币淘里程领取京东签到" rel="bookmark" target="_blank">4月7日 淘金币淘里程领取京东签到</a><span>已结束</span></h2>
<h6>发布日期: 2017-04-07 | 分类: <a href="http://www.abckg.com/xunibi">虚拟币</a> | 浏览:125177
</h6><div class="intro"><p>淘金币一键领取 http://021.tw/t/ https://www.chaidu.com/App/Web/Taobao-Coin/ 【电脑端30金币】 https://taojinbi.taobao.com/inde ... auto_take=true 【手机端30金币】 http://h5.m.taobao...</p></div></div>实现方法
1.定义items
class DemoItem(scrapy.Item):
id = scrapy.Field()
title = scrapy.Field()
href = scrapy.Field()
content = scrapy.Field()
2.新建一个爬虫名为test
# -*- coding: utf-8 -*-
import scrapy
from demo.items import DemoItem
from scrapy.http import Request
'''
遇到不懂的问题?Python学习交流群:1004391443满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class TestSpider(scrapy.Spider):
#定义爬虫的名字和需要爬取的网址
name = "test"
allowed_domains = ["www.abckg.com"]
start_urls = ['http://www.abckg.com/']
def parse(self, response):
for resp in response.css('.post'):
#实例化item
item = DemoItem()
#把获取到的内容保存到item内
item['href'] = resp.css('h2 a::attr(href)').extract()
item['title'] = resp.css('h2 a::text').extract()
item['content'] = resp.css('.intro p::text').extract()
yield item
#下面是多页面的爬取方法
urls = response.css('.pageinfo a::attr(href)').extract()
for url in urls:
yield Request(url, callback=self.parse)
categorys = response.css('.menu li a::attr(href)').extract()
for ct in categorys:
yield Request(ct, callback=self.parse)3.修改settings.py,添加以下代码
FEED_EXPORT_ENCODING = 'utf-8'运行
打开cmd输入
scrapy crawl test -o items.json