前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
第三方库
requests: 解析url (强大,你不得不用!)
beautifulsoup4:不会正则表达式童鞋的福音,可以容易的提取到html文件中各种标签及其属性
安装方法:
pip install requests
pip install beautifulsoup4
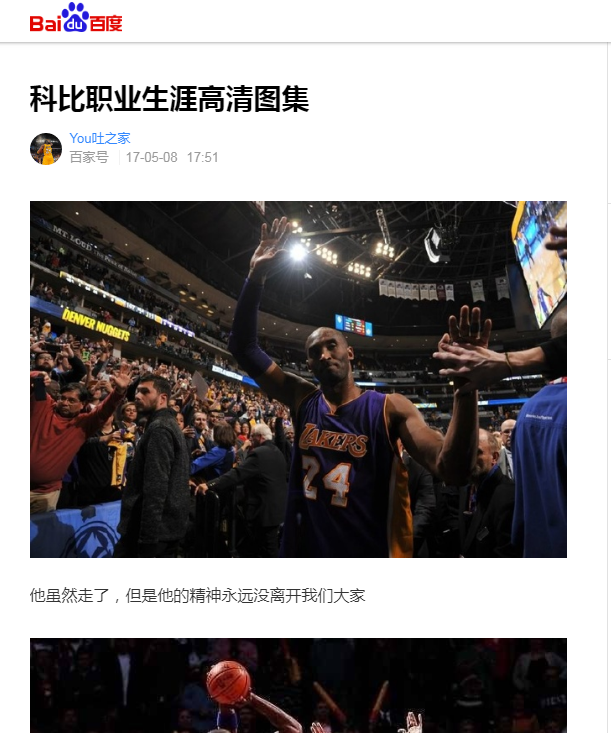
爬取目标网页:科比职业生涯高清图集 (来自百度网友分享)
https://baijiahao.baidu.com/s?id=1566820986637813&wfr=spider&for=pc
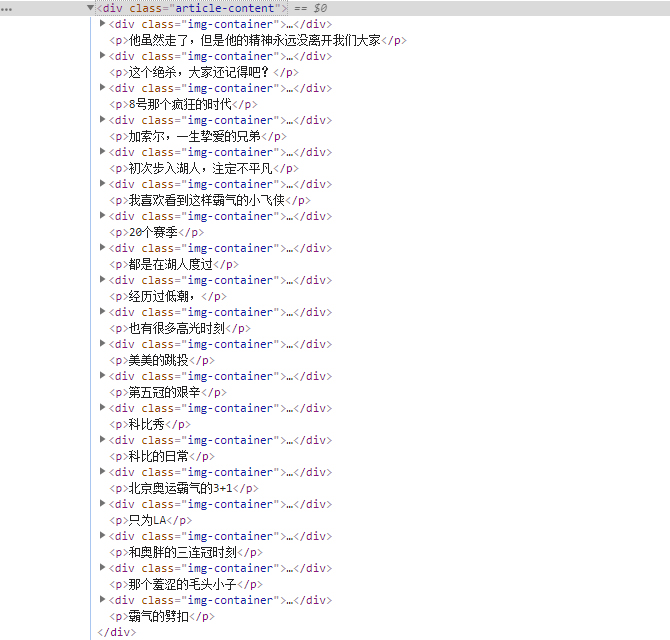
分析网页源代码:发现需要的内容都集中在class="article-content"的div标签中,而且需要的图片都集中在class="large"的img标签中
啥也不说了,直接上Python代码吧!

运行起来吧,GO!

最后再来一张霸气的!
