AQI分析与预测
AQI全称是Air Quality Index,指空气质量指数,用来衡量空气清洁或者污染的程度,值越小,表示空气质量越好。
本文的分析目标是:
一、描述性统计
- 那些城市的空气质量较好/较差?
- 空气质量在地理位置分布上,是否具有一定的规律?
二、推断统计
- 临海城市的空气质量是否优于内陆城市?
三、相关系数分析
- 空气质量主要受哪些因素的影响?
四、区间估计
- 全国城市空气质量普遍处于哪种水平?
五、统计建模
- 怎样预测一个城市的空气质量?
导包并读取数据:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
plt.rcParams["font.family"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
data = pd.read_csv("data/data.csv")
print(data.shape)
data.head()
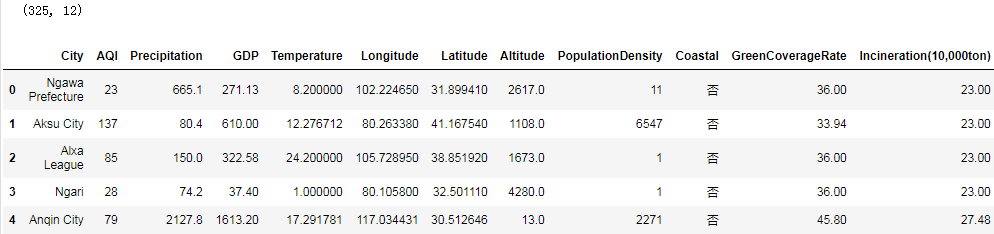
数据集描述:
-
City:城市名
-
AQI:空气质量指数
-
Precipitation:降雨量
-
GDP:人均生产总值
-
Tempearture:温度
-
Longitude/Latitude:经/纬度
-
Altitude:海拔高度
-
PopulationDensity:人口密度
-
Coastal:是否沿海
-
GreenCoverageRate:绿化覆盖率
-
Incineration(10,000ton):焚烧量(w吨)
数据清洗
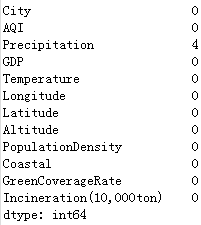
检查缺失值:
data.isnull().sum(axis=0)
查看含缺失值列数据的分布:
#print(data["Precipitation"].skew())#偏度
sns.distplot(data["Precipitation"].dropna())#要删除NA值才能做分布密度图
plt.title("分布密度图")
0.27360760671177387

数值型变量,数据呈现右偏分布,所以使用中位数填充。
对缺失值进行中位数填充
data.fillna({"Precipitation":data["Precipitation"].median()},inplace=True)
检查异常值的三种方法
- data.describe() 查看数据的描述:分位数、均值与标准差
- 基于正太分布 ±三个标准差涵盖99.7%的数据
- 箱线图(四分位距IQR=Q3-Q1,上下边界:Q3/Q1 ±1.5IQR)
查看数据集的偏度:
data.skew()
AQI 1.198754
Precipitation 0.273608
GDP 3.761428
Temperature -0.597343
Longitude -1.407505
Latitude 0.253563
Altitude 3.067242
PopulationDensity 3.125853
GreenCoverageRate -0.381786
Incineration(10,000ton) 4.342614
dtype: float64
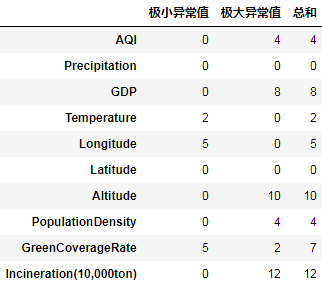
可以看到GDP和人口密度等都出现了严重的右偏分布,意味着存在很多极大的异常值。
下面我们查看以下GDP的异常值:
mean, std = data.GDP.mean(), data.GDP.std()
lower, upper = mean - 3 * std, mean + 3 * std
print("均值:", mean)
print("标准差:", std)
print("下限:", lower)
print("上限:", upper)
data.loc[(data.GDP < lower) | (data.GDP > upper), "GDP"]
均值: 2390.901815384616
标准差: 3254.876921271434
下限: -7373.728948429687
上限: 12155.532579198918
16 22968.60
63 18100.41
202 24964.99
207 17502.99
215 14504.07
230 16538.19
256 17900.00
314 15719.72
Name: GDP, dtype: float64
可以通过以下代码查看每个数值列异常值的个数:
def func(s):
mean, std = s.mean(), s.std()
lower, upper = mean - 3 * std, mean + 3 * std
a, b = (s < lower).sum(), (s > upper).sum()
return pd.Series((a, b, a+b), index=("极小异常值", "极大异常值", "总和"))
data.select_dtypes(include='number').agg(func).T
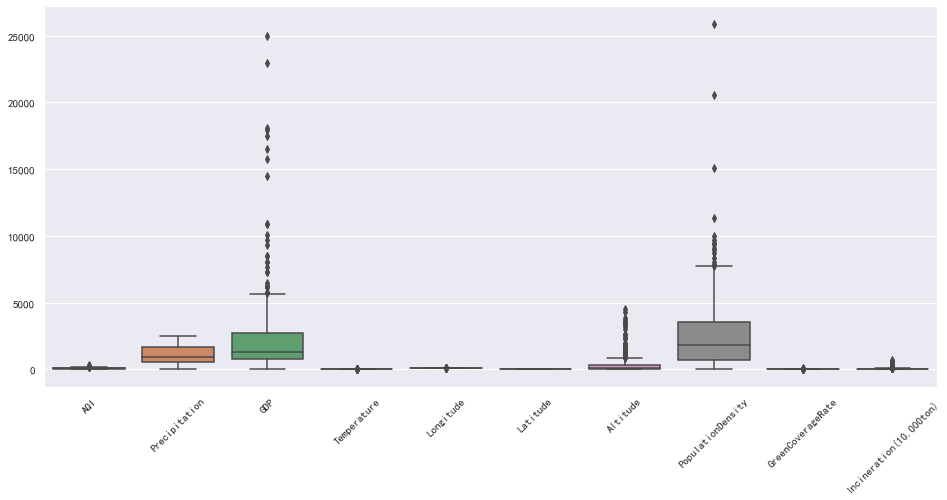
箱线图
我们可以直接通过箱线图来查看数据集整体的异常情况:
plt.figure(figsize=(16, 7))
plt.xticks(rotation=45)
sns.boxplot(data=data)
也可以单独查看某个列的异常情况:
sns.boxplot(data=data["GDP"])
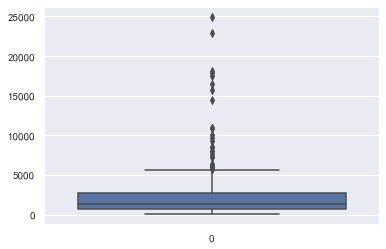
异常值处理
处理方式有:
- 删除异常数据
- 视为缺失值处理
- 对数转换
- 使用边界值替换
- 分箱离散化
对数转换
由于右偏分布在取对数后,往往呈现正态分布,所以我们可以对右偏分布进行取对数转换。
例如,GDP变量呈现严重的右偏分布,我们可以进行取对数转换:
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(15, 5)
sns.distplot(data["GDP"], ax=ax[0])
sns.distplot(np.log(data["GDP"]), ax=ax[1])
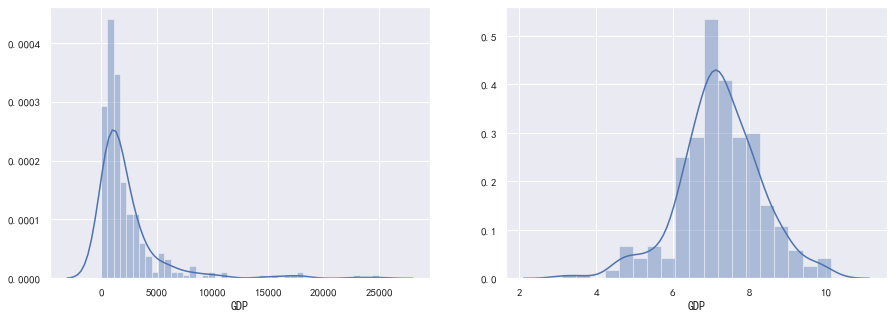
用边界值替换
查看处理前的数据:
data.select_dtypes("number").agg(["max", "min"])

用边界值替换处理:
data_c = data.copy()
for column in data.columns:
s = data_c[column]
if pd.api.types.is_numeric_dtype(s):
quantile = np.quantile(s, [0.25, 0.75])
IQR = quantile[1]-quantile[0]
lower = quantile[0] - 1.5 * IQR
upper = quantile[1] + 1.5 * IQR
s.clip(lower, upper, inplace=True)
data_c.describe()
再查看:
data_c.describe()
结果:
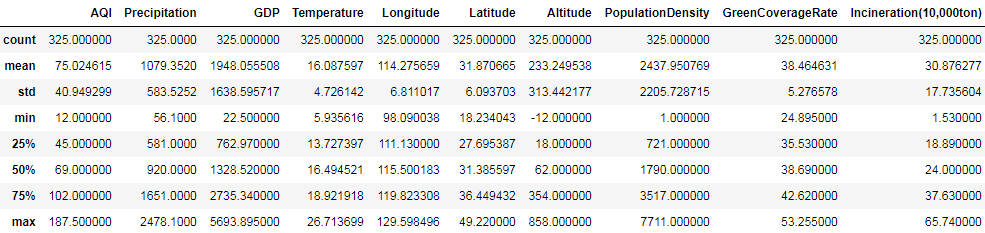
再次查看箱线图:
plt.figure(figsize=(16, 7))
plt.xticks(rotation=45)
sns.boxplot(data=data_c)
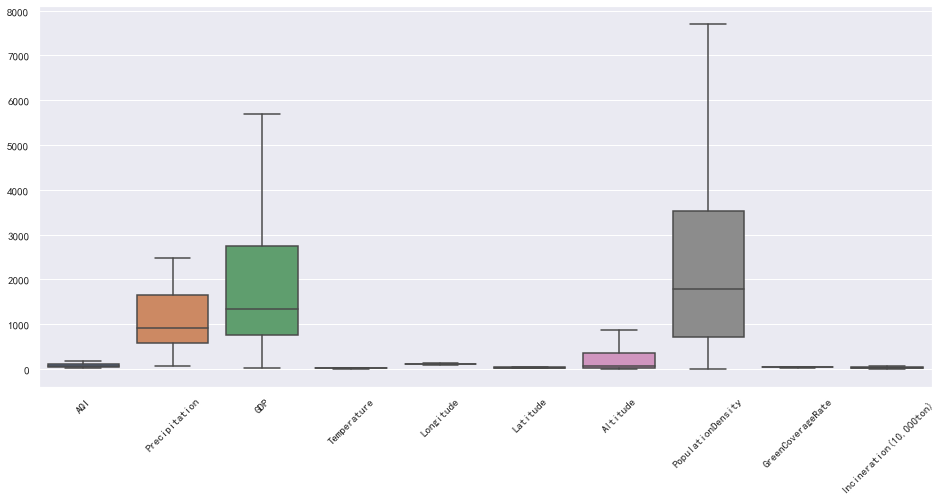
重复值处理
# 发现重复值。
print(data.duplicated().sum())
# 查看哪些记录出现了重复值。
data[data.duplicated(keep=False)]
结果:
2

重复值对数据分析通常没有什么用,直接删除即可:
data.drop_duplicates(inplace=True)
print(data.duplicated().sum())#去重后检查
结果:
0
分析
空气质量最好/差的5个城市
最好的5个城市
t = data[["City", "AQI"]]
t.nsmallest(5, "AQI")
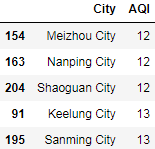
可以发现:空气质量最好的5个城市为 韶关、南平、梅州、基隆、三明
最差的8个城市
t.nlargest(5, "AQI")
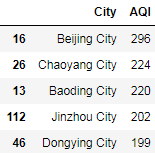
可以发现:空气质量最差的5个城市为 北京、朝阳、保定、锦州、东营
空气质量等级分布
对于AQI,可以对空气质量进行等级划分,划分标准为:
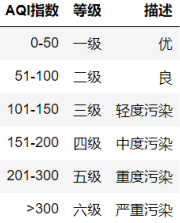
分级如函数:
import math
levels = ["一级", "二级", "三级", "四级", "五级", "六级"]
def value_to_level(AQI):
i = math.ceil(AQI/50)-1
if i == 5:
i = 4
elif i > 5:
i = 5
return levels[i]
level = data["AQI"].apply(value_to_level)
display(level.value_counts())
sns.countplot(x=level, order=levels)
结果:
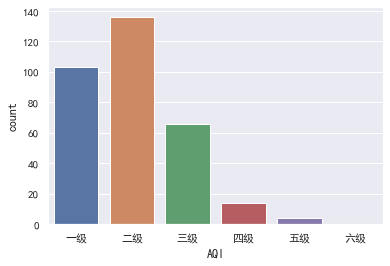
空气质量指数分布
sns.scatterplot(x="Longitude", y="Latitude", hue="AQI", palette=plt.cm.RdYlGn_r, data=data)
plt.title("空气质量指数分布图", size=16)
plt.show()
结果:
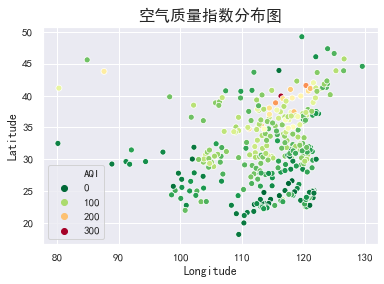
从上图大致的地理位置来看,西部城市普遍好于东部城市,南部城市普遍好于北部城市。
临海与内陆城市空气质量分布
首先看下临海城市与内陆城市的数量:
data["Coastal"].value_counts()
否 243
是 80
Name: Coastal, dtype: int64
分类散点图:
sns.stripplot(x="Coastal", y="AQI", data=data)
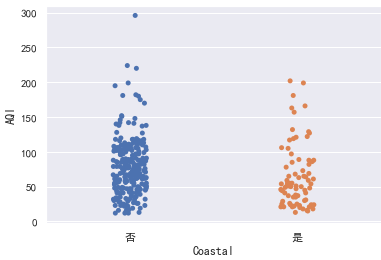
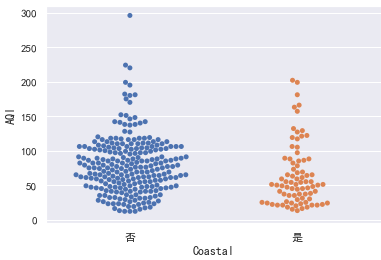
分簇散点图:
sns.swarmplot(x="Coastal", y="AQI", data=data)
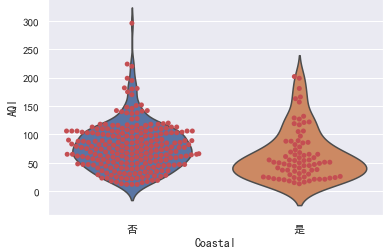
小提琴图:
sns.violinplot(x="Coastal", y="AQI", data=data)

更直观的是将分簇散点图和小提琴图叠加起来看:
sns.violinplot(x="Coastal", y="AQI", data=data, inner=None)
sns.swarmplot(x="Coastal", y="AQI", color="r", data=data)
均值
display(data.groupby("Coastal")["AQI"].mean())
sns.barplot(x="Coastal", y="AQI", data=data)#只能看均值数据
结果:
Coastal
否 79.045267
是 64.062500
Name: AQI, dtype: float64
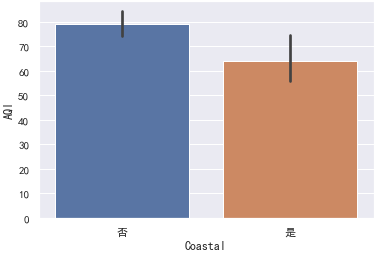
注:柱形图上方的竖线表示置信区间。
还可以查看箱线图:
sns.boxplot(x="Coastal", y="AQI", data=data)
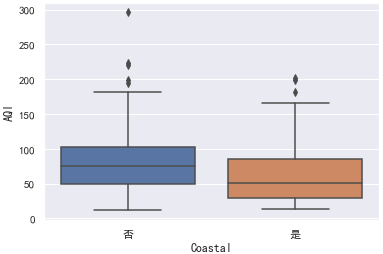
而小提琴图除了展示箱线图的信息外,还能呈现分布的密度。
就样本数据的分布图而言,我们可以看到沿海城市的AQI分布普遍低于内陆城市。但我们仅仅只有样本数据,对于总体的支持力度还需假设检验。
假设检验: 检验内陆AQI和沿海城市AQI的均值是否相等(两样本t检验)
from scipy import stats
coastal = data.loc[data["Coastal"] == "是", "AQI"]
inland = data.loc[data["Coastal"] == "否", "AQI"]
首先进行方差齐性检验(检验两样本的方差是否一致):
stats.levene(coastal, inland)
结果:
LeveneResult(statistic=0.08825036641952543, pvalue=0.7666054880248168)
方差齐性检验,原假设H0为方差相等(齐性),显然p-value超过显著性水平,说明两样本的方差是相等的。
下面进行两样本t检验:
#equal_var=True表示两样本方差一致
r = stats.ttest_ind(coastal, inland, equal_var=True)
r
结果:
Ttest_indResult(statistic=-2.7303827520948905, pvalue=0.006675422541012958)
P值小于显著性水平,所以拒绝原假设,接受备择假设,即内陆AQI和沿海城市AQI的均值不相等。
由于统计量由左样本减右样本得到,统计量小于0说明,临海的均值小于内陆。
下面我们假设临海空气质量的均值小于内陆空气质量的均值,则这是一个右边假设检验,可以通过以下方法得到P值:
p = stats.t.sf(r.statistic, df=len(coastal)+len(inland)-2)
p
结果:
0.9966622887294936
说明我们有99.7%的信心认为临海的空气质量整体好于内陆空气质量(均值小于内陆)。
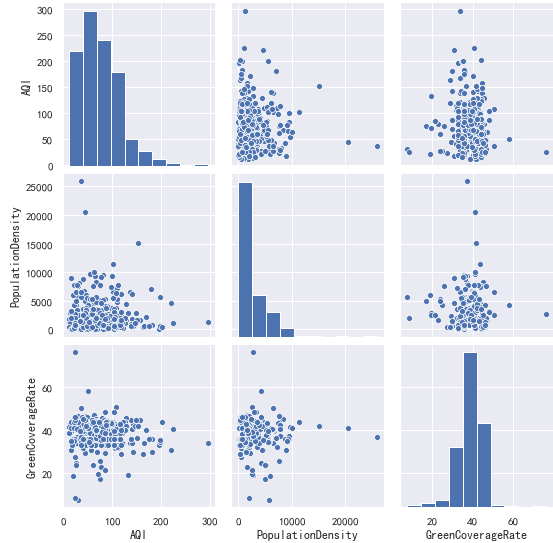
空气质量主要受那些因素影响呢?
一般我们会有如下疑问:
- 人口密度大,是否会对空气质量造成负面影响
- 绿化率高,是否能提高空气质量
首先查看散点图矩阵:
sns.pairplot(data[["AQI","PopulationDensity","GreenCoverageRate"]])
#参数 kind="reg"给散点图绘制一条回归线
# sns.pairplot(data[["AQI", "PopulationDensity", "GreenCoverageRate"]], kind="reg")
相关系数:
变量X与变量Y的协方差为:
Cov
(
X
,
Y
)
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
n
−
1
\large{\operatorname{Cov}(X, Y)=\frac{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{n-1}}
Cov(X,Y)=n−1∑i=1n(xi−xˉ)(yi−yˉ)
相关系数的定义:
r
(
X
,
Y
)
=
Cov
(
X
,
Y
)
σ
X
σ
Y
\large{r(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sigma_{X} \sigma_{Y}}}
r(X,Y)=σXσYCov(X,Y)
= ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 \large{=\frac{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sqrt{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2} \sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2}}}} =∑i=1n(xi−xˉ)2∑i=1n(yi−yˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
相关系数的绝对值的取值范围是[0,1],可以根据相关系数衡量两个变量的相关性,正数代表正相关,负数代码负相关。绝对值的大小体现相关的程度:
0.8-1:极强相关
0.6-0.8:强相关
0.4-0.6:中等程度相关
0.2-0.4:弱相关
0-0.2:极弱相关或无相关
x = data["AQI"]
y = data["Precipitation"]
# 计算AQI与Precipitation的协方差。
a = (x - x.mean()) * (y - y.mean())
cov = np.sum(a) / (len(a) - 1)
print("协方差:", cov)
# 计算AQI与Precipitation的相关系数。
corr = cov / np.sqrt(x.var() * y.var())
print("相关系数:", corr)
结果:
协方差: -10098.209013903044
相关系数: -0.40184407003013883
其实可以直接使用内置方法计算:
print("协方差:", x.cov(y))
print("相关系数:", x.corr(y))
结果:
协方差: -10098.209013903042
相关系数: -0.4018440700301393
调用DataFrame中的方法计算相关系数:
data.corr()

使用热力图呈现相关性数值更佳:
plt.figure(figsize=(15, 10))
ax = sns.heatmap(data.corr(), cmap=plt.cm.RdYlGn, annot=True, fmt=".2f")
结果:
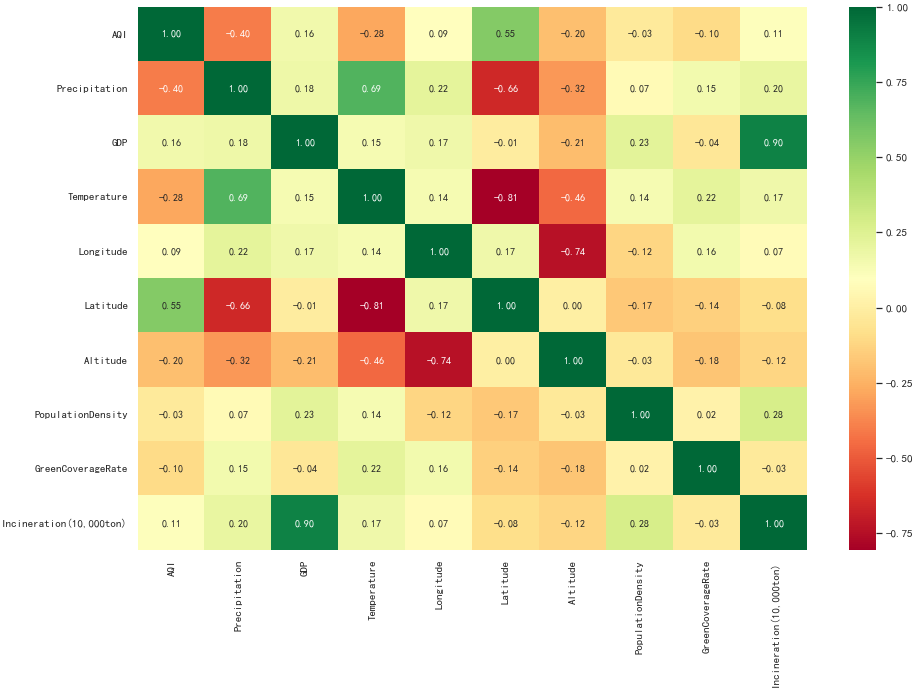
从上述相关性矩阵我们可以看到,AQI与人口密度绿化面积几乎不相关。
AQI与纬度(0.55)和降雨量(-0.4)的相关性最高。说明:
- 纬度越低,AQI越低,空气质量越好。
- 降雨量越多,AQI越低,空气质量越好。
空气质量验证
传言说,全国所有城市的空气质量指数均值为71左右,这个消息可靠吗?
下面作为原假设全部城市的AQI均值为71,并进行假设检验:
print("样本均值 :", data["AQI"].mean())
print(stats.ttest_1samp(data["AQI"], 71))
结果:
样本均值 : 75.3343653250774
Ttest_1sampResult(statistic=1.8117630617496872, pvalue=0.07095431526986647)
可以看到,P值大于显著性水平0.05,故我们没有充足的证据拒绝原假设,于是接受原假设全部城市的AQI均值为71。
下面计算一下置信区间:
stats.t.interval(0.95, df=len(data) - 1, loc=data.AQI.mean(), scale=stats.sem(data.AQI))
结果: (70.6277615675309, 80.0409690826239)
因此,我们可以认为全国所有城市的平均空气质量,95%的可能在(70.63, 80.04)范围内。
建模预测
问题:已知某市的降雨量、温度、经纬度等指标,如何预测其空气质量?
为了进行模型计算,我们首先需要将一些文本型变量转换为离散数值变量。
data["Coastal"] = data["Coastal"].map({"是": 1, "否": 0})
data["Coastal"].value_counts()
0 243
1 80
Name: Coastal, dtype: int64
注意:只有两个类别时,转换为任意两个数值都可以。如果存在三个以上的分类,可以使用独热编码对变量进行转换。
基础模型:
#线性回归模型
from sklearn.linear_model import LinearRegression
#数据集的处理。训练集和测试集
from sklearn.model_selection import train_test_split
#构建X、y变量
X = data.drop(["City","AQI"],axis=1)#删除多余变量 ,Y变量不能在此
y = data["AQI"]
#对数据进行分割 训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#实例化模型
lr = LinearRegression()
#拟合模型
lr.fit(X_train,y_train)
#R方值 模型评价
print(lr.score(X_train,y_train))
print(lr.score(X_test,y_test))
结果:
0.4538897765064037
0.4040770562383651
绘制预测结果图
y_hat = lr.predict(X_test)
plt.figure(figsize=(15, 5))
plt.plot(y_test.values, "-r", label="真实值", marker="o")
plt.plot(y_hat, "-g", label="预测值", marker="D")
plt.legend(loc="upper left")
plt.title("线性回归预测结果", fontsize=20)
plt.show()
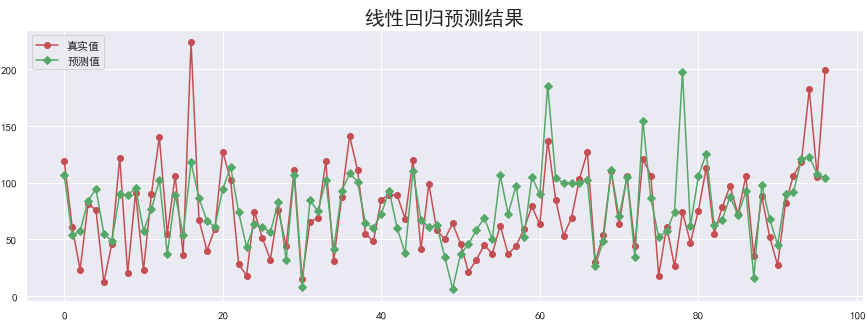
下面我们将尝试优化模型提高模型效果。
模型优化
首先我们使用临界值替换异常值:
for column in X.columns.drop("Coastal"):
s = X_train[column]
if pd.api.types.is_numeric_dtype(s):
quantile = np.quantile(s, [0.25, 0.75])
IQR = quantile[1]-quantile[0]
lower = quantile[0] - 1.5 * IQR
upper = quantile[1] + 1.5 * IQR
s.clip(lower, upper, inplace=True)
X_test[column].clip(lower, upper, inplace=True)
再次查看模型效果:
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
结果:
0.4631142291492417
0.44614202658395546
可以看到模型相对之前有一定的提高。
下面使用RFE(Recursive feature elimination 递归特征消除) 方法实现特征选择,因为删除一些不重要的特征,反而有助于模型效果的提高。
from sklearn.feature_selection import RFECV
# estimator: 要操作的模型。
# step: 每次删除的变量数。
# cv: 使用的交叉验证折数。
# n_jobs: 并发的数量。
# scoring: 评估的方式。
rfecv = RFECV(estimator=lr, step=1, cv=5, n_jobs=-1, scoring="r2")
rfecv.fit(X_train, y_train)
print("剩余的特征数量:", rfecv.n_features_)
# 返回经过特征选择后,使用缩减特征训练后的模型。
print(rfecv.estimator_)
# 返回每个特征的等级,数值越小,特征越重要。
print(rfecv.ranking_)
print("被选择的特征布尔数组:", rfecv.support_)
print("交叉验证的评分:", rfecv.grid_scores_)
结果:
9
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
[1 1 1 1 1 1 2 1 1 1]
[ True True True True True True False True True True]
[-0.06091362 0.1397744 0.19933237 0.16183209 0.18281661 0.20636585
0.29772708 0.307344 0.30877162 0.30022701]
绘图表示,在特征选择的过程中,使用交叉验证获取R平方的值
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, marker="o")
plt.xlabel("特征数量")
plt.ylabel("交叉验证$R^2$值")

看看进行特征选择后的效果:
print("剔除的变量:", X_train.columns[~rfecv.support_])
# X_train_eli = rfecv.transform(X_train)
# X_test_eli = rfecv.transform(X_test)
X_train_eli = X_train[X_train.columns[rfecv.support_]]
X_test_eli = X_test[X_test.columns[rfecv.support_]]
print(rfecv.estimator_.score(X_train_eli, y_train))
print(rfecv.estimator_.score(X_test_eli, y_test))
结果:
剔除的变量: Index(['PopulationDensity'], dtype='object')
0.46306656191488593
0.44502255894081927
下面我们对部分数据使用分箱操作,并进行one_Hot编码:
from sklearn.preprocessing import KBinsDiscretizer
# KBinsDiscretizer K个分箱的离散器。用于将数值(通常是连续变量)变量进行区间离散化操作。
# n_bins:分箱(区间)的个数。
# encode:离散化编码方式。分为:onehot,onehot-dense与ordinal。
# onehot:使用独热编码,返回稀疏矩阵。
# onehot-dense:使用独热编码,返回稠密矩阵。
# ordinal:使用序数编码(0,1,2……)。
# strategy:分箱的方式。分为:uniform,quantile,kmeans。
# uniform:每个区间的长度范围大致相同。
# quantile:每个区间包含的元素个数大致相同。
# kmeans:使用一维kmeans方式进行分箱。
k = KBinsDiscretizer(n_bins=[4, 5, 14, 6],
encode="onehot-dense", strategy="uniform")
# 定义离散化的特征。
discretize = ["Longitude", "Temperature", "Precipitation", "Latitude"]
r = k.fit_transform(X_train_eli[discretize])
r = pd.DataFrame(r, index=X_train_eli.index)
# 获取除离散化特征之外的其他特征。
X_train_dis = X_train_eli.drop(discretize, axis=1)
# 将离散化后的特征与其他特征进行重新组合。
X_train_dis = pd.concat([X_train_dis, r], axis=1)
# 对测试集进行同样的离散化操作。
r = pd.DataFrame(k.transform(X_test_eli[discretize]), index=X_test_eli.index)
X_test_dis = X_test_eli.drop(discretize, axis=1)
X_test_dis = pd.concat([X_test_dis, r], axis=1)
# 查看转换之后的格式。
display(X_train_dis.head())

再重新查看模型效果:
lr.fit(X_train_dis, y_train)
print(lr.score(X_train_dis, y_train))
print(lr.score(X_test_dis, y_test))
结果:
0.6892388692774563
0.6546062348355671
可以看到模型在经过分箱离散化操作后,预测效果大幅度提高。
残差图分析
残差就是模型的预测值与真实值之间的差异,可以绘制残差图对模型进行评估,横坐标为预测值,纵坐标为真实值
对于一个模型,误差应该的随机性的,而不是有规律的。残差也随机分布于中心线附近,如果残差图中残差是有规律的,则说明模型遗漏了某些能够影响残差的解释信息。
异方差性,是指残差具有明显的方差不一致性。
绘制残差图:
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(15, 5)
data = [X_train, X_train_dis]
title = ["原始数据", "处理后数据"]
for d, a, t in zip(data, ax, title):
model = LinearRegression()
model.fit(d, y_train)
y_hat_train = model.predict(d)
residual = y_hat_train - y_train.values
a.set_xlabel("预测值")
a.set_ylabel(" 残差")
a.axhline(y=0, color="red")
a.set_title(t)
sns.scatterplot(x=y_hat_train, y=residual, ax=a)
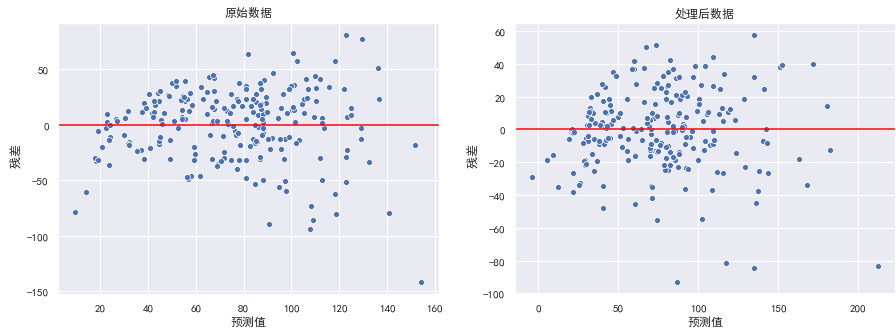
在左图中,可以看出随着预测值的增大,残差也有增大的趋势。此时我们可以使用对y值取对数的方式处理。
model = LinearRegression()
y_train_log = np.log(y_train)
y_test_log = np.log(y_test)
model.fit(X_train, y_train_log)
y_hat_train = model.predict(X_train)
residual = y_hat_train - y_train_log.values
plt.xlabel("预测值")
plt.ylabel(" 残差")
plt.axhline(y=0, color="red")
sns.scatterplot(x=y_hat_train, y=residual)
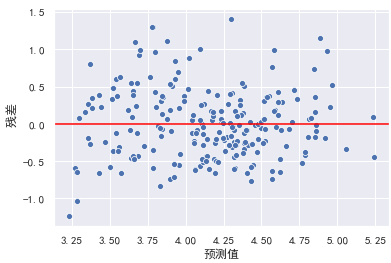
此时异方差性得到解决。模型效果也可能会得到进一步提升。
检查离群点:对于多元线性回归,其回归线已经成为超平面,无法通过可视化来观测。但我们可以通过残差图,通过预测值与实际值之间的关系,来检测离群点。我们认为偏离2倍标准差的点为离群点:
y_hat_train = lr.predict(X_train_dis)
residual = y_hat_train - y_train.values
r = (residual - residual.mean()) / residual.std()
plt.xlabel("预测值")
plt.ylabel(" 残差")
plt.axhline(y=0, color="red")
sns.scatterplot(x=y_hat_train[np.abs(r) <= 2],
y=residual[np.abs(r) <= 2], color="b", label="正常值")
sns.scatterplot(x=y_hat_train[np.abs(r) > 2], y=residual[np.abs(r) > 2], color="orange", label="异常值")
结果:
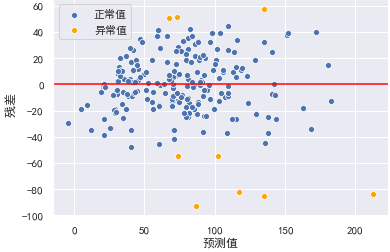
剔除异常值后,训练模型并查看效果:
X_train_dis_filter = X_train_dis[np.abs(r) <= 2]
y_train_filter = y_train[np.abs(r) <= 2]
lr.fit(X_train_dis_filter, y_train_filter)
print(lr.score(X_train_dis_filter, y_train_filter))
print(lr.score(X_test_dis, y_test))
结果:
0.7354141753913532
0.6302724058812207
可以看到模型效果得到了进一步的提升。
结论
- 从空气质量总体分布上来说,南方城市优于北方城市,西部城市优于东部城市。
- 临海城市空气质量整体好于内陆城市
- 城市是否临海,降雨量,以及维度对空气质量指数影响最大
- 有95%的把握可以说城市平均空气质量指数在区间(70.63, 80.04)之间
- 通过历史数据,我们可以对空气质量指数进行预测