前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
Python爬虫可以说是好玩又好用了。现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中。需求有了,剩下的就是实现了。
在开始之前,保证已经安装好了MySQL并需要启动本地MySQL数据库服务。提到安装MySQL数据库,前两天在一台电脑上安装MySQL5.7时,死活装不上,总是提示缺少Visual Studio 2013 Redistributable,但是很疑惑,明明已经安装了呀,原来问题出在版本上,更换一个版本后就可以了。小问题大苦恼,不知道有没有人像我一样悲催。
言归正传,启动本地数据库服务:
用管理员身份打开“命令提示符(管理员)”,然后输入“net start mysql57”(我把数据库服务名定义为mysql57了,安装MySQL时可以修改)就可以开启服务了。注意使用管理员身份打开小黑框,如果不是管理员身份,我这里会提示没有权限,大家可以试试。
启动服务之后,我们可以选择打开“MySQL 5.7 Command Line Client”小黑框,需要先输入你的数据库的密码,安装的时候定义过,在这里可以进行数据库操作。
下面开始上正餐。
一、Python爬虫抓取网页数据并保存到本地数据文件中
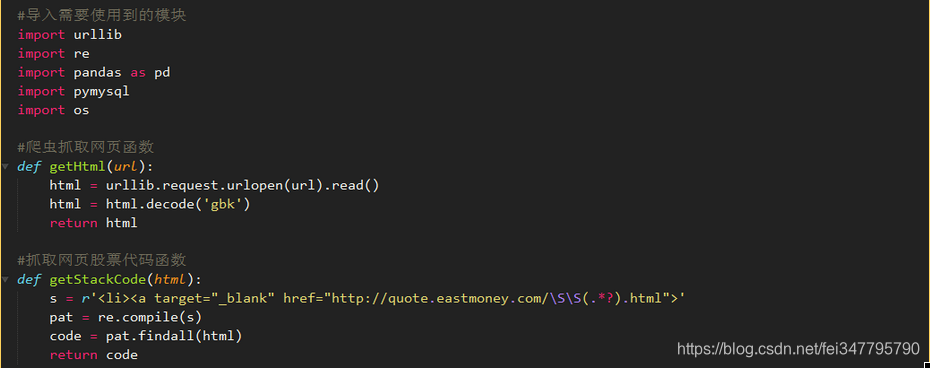
首先导入需要的数据模块,定义函数:
真正干活的代码块:
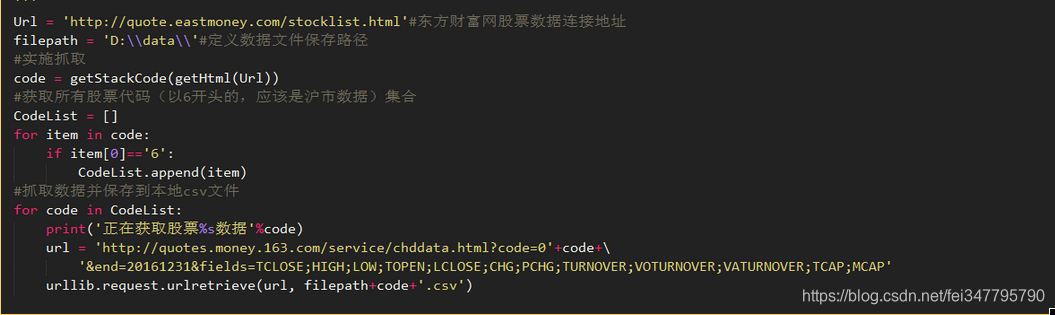
以上代码实现了爬虫网页抓取股票数据,并保存到本地文件中。关于爬虫的东西,有很多资料可以参考,大都是一个套路,不再多说。同时,本文实现过程中也参考了很多的网页资源,在此对所有原创者表示感谢!
先看下抓取的结果。CodeList是抓取到的所有股票代码的集合,我们看到它共包含1416条元素,即1416支股票数据。因为股票太多,所以抓取的是以6开头的,貌似是沪市股票数据(原谅我不懂金融)。
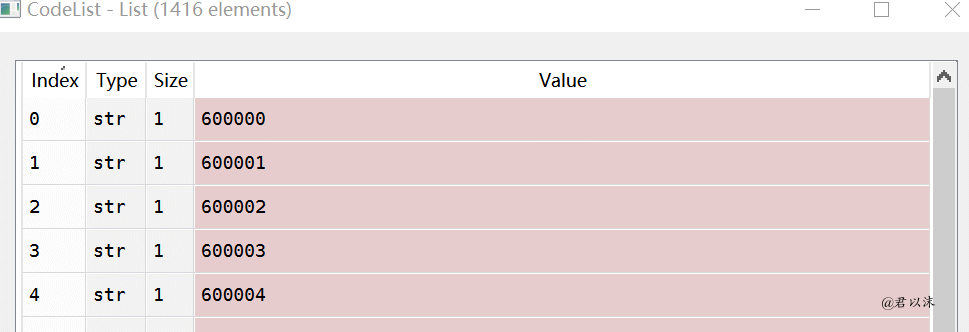
抓取到的股票数据会分别存储到csv文件中,一只股票数据一个文件。理论上会有1416个csv文件,和股票代码数一致。但原谅我的渣网速,下载一个都费劲,也是呵呵了。

打开一个本地数据文件看一下抓取的数据长什么样子:
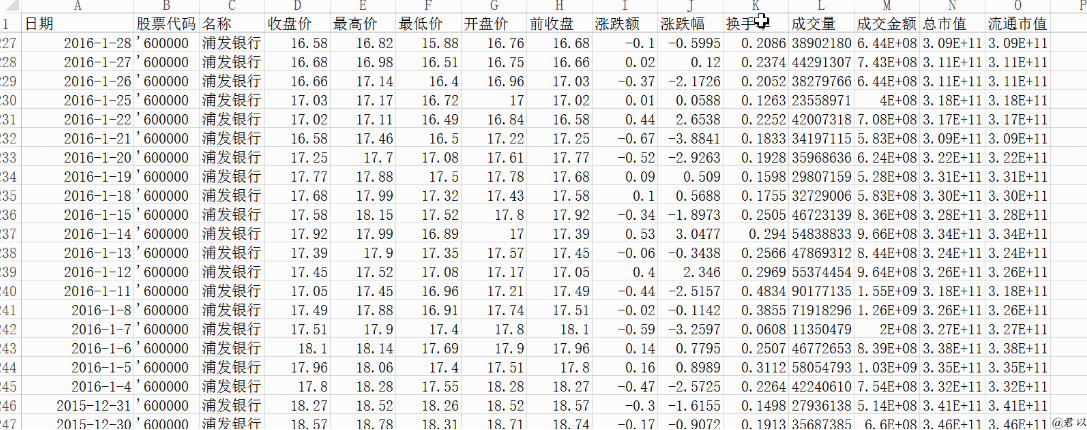
其实和人工手动下载也没什么区别了,硬要说区别,那就是解放了劳动力,提高了生产力(怎么听起来像政治?)。
二、将数据存储到MySQL数据库
首先建立本地数据库连接:

其中,数据库名称(name)和密码(password)是安装MySQL时设置的。
创建数据库,专门用来存储本次股票数据:

在首次运行的时候一般都会正常创建数据库,但如果再次运行,因数据库已经存在,那么跳过创建,继续往下执行。创建好数据库后,选择使用刚刚创建的数据库,在该数据库中存储数据表。
下面看具体的存储代码:
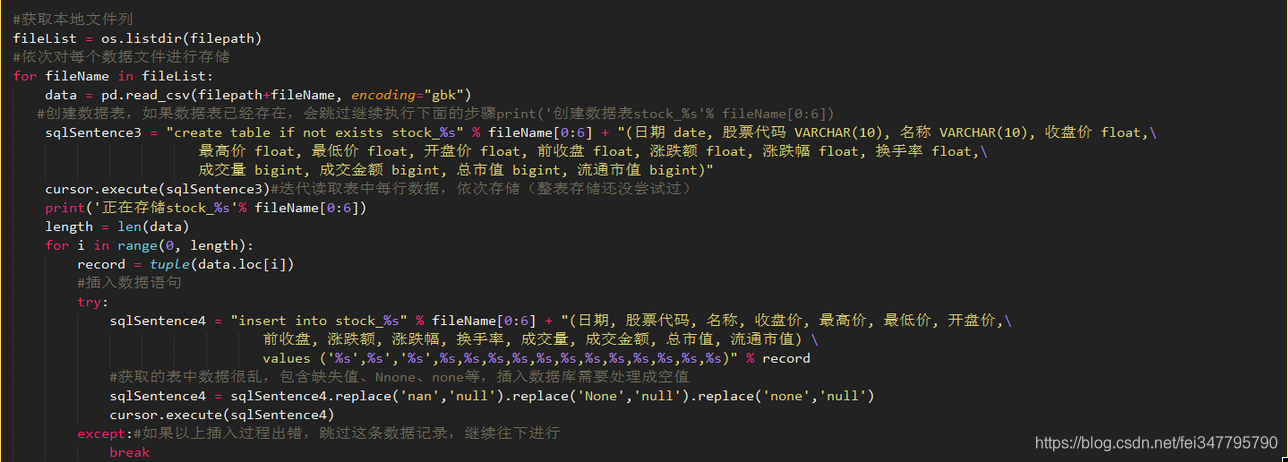
代码并不复杂,只要注意其中几个点就好了。
1.逻辑层次:
包含两层循环,外层循环是对股票代码的循环,内层循环是对当前股票的每一条记录的循环。说白了就是按照股票一支一支的存储,对于每一支股票,按照它每日的记录一条一条的存储。是不是很简单很暴力?是的!完全没有考虑更加优化的方式。
2.读取本地数据文件的编码方式:
使用'gbk'编码,默认应该是'utf8',但好像不支持中文。
3.创建数据表:
同样的,如果数据表已经存在(判断是否存在if not exists),则跳过创建,继续执行下面的步骤(会继续存储)。有个问题是,有可能数据重复存储,可以选择跳过存储或者只存储最新数据。我在这里没有考虑太多额外的处理。其次,指定字段格式,后边几个字段成交量、成交金额、总市值、流通市值,因为数据较大,选择使用bigint类型。
4.没有指定数据表的主键:
最初是打算使用日期作为主键的,后来发现获取到的数据中竟然包含重复日期的数据,这就打破了主键的唯一性,会出bug的,然后我也没有多去思考数据文件的内容,也不会进一步使用这些个数据,也就图省事直接不设置主键了。
5.构造sql语句sqlSentence4:
该过程实现中,直接把股票数据记录tuple了,然后使用字符串格式化(%操作符)。造成的精度问题没有多考虑,不知道会不会产生什么样的影响。%s有的上边带着' ',是为了在sql语句中表示字符串。其中有一个%s',只有右边有单引号,匹配的是股票代码,只有一边单引号,这是因为从数据文件中读取到的字符串已经包含了左边的单引号,左边不需要再添加了。这是数据文件格式的问题,为了表示文本形式预先使用了单引号。
6.异常值处理:
文本文件中,包含有空值、None、none等不标准化数据,这里全部替换为null了,即数据库的空值。
完成MySQL数据库数据存储后,需要关闭数据库连接:
#关闭游标,提交,关闭数据库连接cursor.close()
db.commit()
db.close()
不关闭数据库连接,就无法在MySQL端进行数据库的查询等操作,相当于数据库被占用。
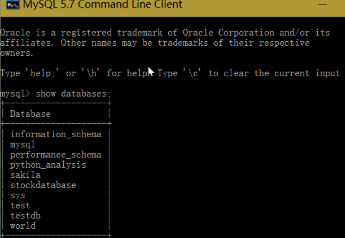
三、MySQL数据库查询
以上逐条打印,会凌乱到死的。也可以在MySQL端查看,先选中数据库:use stockDatabase;,然后查询:select * from stock_600000;,结果大概就是下面这个样子了:

四、完整代码
实际上,整个事情完成了两个相对独立的过程:
1.爬虫获取网页股票数据并保存到本地文件;
2.将本地文件数据储存到MySQL数据库。
并没有直接的考虑把从网页上抓取到的数据实时(或者通过一个临时文件)扔进数据库,跳过本地数据文件这个过程。这里只是尝试着去实现了一下这件事情,代码没有做任何的优化考虑。本身不实际去使用,只是乐趣而已,差不多先这样。哈哈~~