前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能。
三种爬虫方式的对比
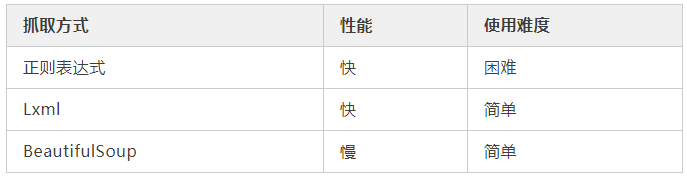
今天咱们主要是讲的xpath爬取数据
xpath简单用法
from lxml import etree
s=etree.HTML(源码) #将源码转化为能被XPath匹配的格式
s.xpath(xpath表达式) #返回为一列表,
基础语法:
// 双斜杠 定位根节点,会对全文进行扫描,在文档中选取所有符合条件的内容,以列表的形式返回。
/ 单斜杠 寻找当前标签路径的下一层路径标签或者对当前路标签内容进行操作
/text() 获取当前路径下的文本内容
/@xxxx 提取当前路径下标签的属性值
| 可选符 使用|可选取若干个路径 如//p | //div 即在当前路径下选取所有符合条件的p标签和div标签。
. 点 用来选取当前节点
… 双点 选取当前节点的父节点
学以致用,方能让我们能快速掌握xpath语法功能。
我们这次需要爬取豆瓣音乐前250条
打开豆瓣音乐:https://music.douban.com/top250
获取单条数据
1.获取音乐标题
打开网址,按下F12,然后查找标题,右键弹出菜单栏 Copy==> Copy Xpath

这里我们想获取音乐标题,音乐标题的xpath是:xpath://[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div/a
# coding:utf-8
from lxml import etree
import requests
url = 'https://music.douban.com/top250'
html = requests.get(url).text #这里一般先打印一下html内容,看看是否有内容再继续。
s = etree.HTML(html)
title = s.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div/a')
print (title)
运行代码:
居然是空的。!!!
这里需要注意一下,浏览器复制的xpath只能作参考,因为浏览器经常会在自己里面增加多余的tbody标签,我们需要手动把这个标签删除
删除中间的/tbody后,是这样的,
title = s.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div/a')
然后我们再运行代码。
<Element a at 0x53d26c8>
说明标题被获取到了。
获取标题文本
#xpath表达式要追加/text()
title = s.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div/a/text()')
#因为要获取标题,所以我需要这个当前路径下的文本,所以使用/text()
又因为这个s.xpath返回的是一个集合,且集合中只有一个元素所以我再追加一个[0]
新的表达式:
title = s.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div/a/text()')[0]
#因为要获取标题,所以我需要这个当前路径下的文本,所以使用/text(),再追加[0]
重新运行得到结果:
We Sing. We Dance. We Steal Things.
正是我们想要的标题。
完整代码
# coding:utf-8
from lxml import etree
import requests
#获取页面地址
def getUrl():
for i in range(10):
url = 'https://music.douban.com/top250?start={}'.format(i*25)
scrapyPage(url)
#爬取每页数据
def scrapyPage(url):
html = requests.get(url).text
s = etree.HTML(html)
trs = s.xpath('//*[@id="content"]/div/div[1]/div/table/tr')
for tr in trs:
href = tr.xpath('./td[2]/div/a/@href')[0]
title = tr.xpath('./td[2]/div/a/text()')[0]
score = tr.xpath('./td[2]/div/div/span[2]/text()')[0]
number = tr.xpath('./td[2]/div/div/span[3]/text()')[0]
img = tr.xpath('./td[1]/a/img/@src')[0]
print href, title, score, number, img
if '__main__':
getUrl()