今天看到了一个Python库,名为markdown。瞬间就给了我一个灵感,那就是制作一个将markdown文件转换成html文件的小工具。

我的实验环境
- 操作系统: Windows 7 64位 旗舰版
- Python版本: 2.7.11
- IDE: PyCharm pro 2016.1
- 所需依赖:
- optparser
- markdown
转换核心
转换的过程很简单,只需要使用markdown库即可,具体使用方法如下:
from markdown import markdown
def parse(md_text):
return markdown(md_text)优化
为了使我们的程序更具特色,也就是类Unix命令行风格。我这里添加了optparser的支持。
核心代码如下:
# OptParser库规范性用法,以实现Unix风格的命令行处理程序
usage = \
"""
'-i', --infile . source markdown file
'-o', --outfile. target html file
'-s', --style. stylesheet for output html file,this is not for mandatory
"""
parser = optparse.OptionParser(usage)
parser.add_option('-i', '--input', dest='infile', type='string', help='input markdown source file')
parser.add_option('-o', '--output', dest='outfile', type='string', help='out put html file')
(options, args) = parser.parse_args()
infile = options.infile
outfile = options.outfile举例:
python md2html.py -i input.md -o outputfile.html
# 我们在命令行输入的参数就会转移到下面的两个变量中了
(options, args) = parser.parse_args()
infile = options.infile
outfile = options.outfile美化
为了使得我们的html更加的美观,我这里采取了BootStrap进行了美化。使用的方式是CDN的方式。这样可以使得我们的文件目录更加的清爽,而且可以给用户一个更加简便的使用体验。
使用的模板如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>BootStrap模板</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- 引入 Bootstrap -->
<link href="http://apps.bdimg.com/libs/bootstrap/3.3.0/css/bootstrap.min.css" rel="stylesheet">
<link href="http://apps.bdimg.com/libs/bootstrap/css/bootstrap.min.css" rel="stylesheet">
<script src="js/jquery-2.2.4.min.js"></script>
<script src="http://apps.bdimg.com/libs/bootstrap/js/bootstrap.min.js"></script>
</head>
<body>
</body>
<!-- jQuery (Bootstrap 的 JavaScript 插件需要引入 jQuery) -->
<script src="https://code.jquery.com/jquery.js"></script>
<!-- 包括所有已编译的插件 -->
<script src="js/bootstrap.min.js"></script>
</html>完整代码
# coding:utf-8
# __author__ = 'Mark sinoberg'
# __date__ = '2016/7/8'
# __Desc__ = 将markdown文件转换为带有样式的html文件
from markdown import markdown
import optparse
# 创建一个专门用于处理解析器的工具类
class MDParser:
# 初始化开始
def __init__(self):
print 'Ready to parser markdown source file to html file.'
# 创建一个对输入文件进行解析的方法,输出文件即为符合html语法的不完整文件
def parsre(self, infile):
infile = open(infile, 'rb')
indata = infile.read()
indata = u'%s' % indata
infile.close()
parsedata = markdown(indata)
return parsedata
# 为输出文件添加自定义标题,并且添加缺少的html头部
def appendHead(self, data, title):
head = \
"""
<html><head><meta charset='utf-8'><title>%s</title><meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="http://apps.bdimg.com/libs/bootstrap/3.3.0/css/bootstrap.min.css">
<script src="http://apps.bdimg.com/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="http://apps.bdimg.com/libs/bootstrap/3.3.0/js/bootstrap.min.js"></script></head><body><div class='container'><div class="row-fluid">
<div class="span12">
""" % title
newdata = head + data
return newdata
# 配合上面的添加头部文件,下面的这个方法适用于添加html尾部标签,使得文件符合html规范
def appendTail(self, data):
tail = \
"""
</div></div></div><script src="http://apps.bdimg.com/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="http://apps.bdimg.com/libs/bootstrap/3.2.0/js/bootstrap.min.js"></script></body></html>
"""
data += tail
return data
# 将完整的html文件输出到指定的位置
def output(self, data, outfile):
outfile = open(outfile, 'wb')
outfile.write(data)
outfile.close()
print "Translated Succeed!"
# OptParser库规范性用法,以实现Unix风格的命令行处理程序
usage = \
"""
'-i', --infile . source markdown file
'-o', --outfile. target html file
'-s', --style. stylesheet for output html file,this is not for mandatory
"""
parser = optparse.OptionParser(usage)
parser.add_option('-i', '--input', dest='infile', type='string', help='input markdown source file')
parser.add_option('-o', '--output', dest='outfile', type='string', help='out put html file')
(options, args) = parser.parse_args()
infile = options.infile
outfile = options.outfile
if __name__ == "__main__":
tool = MDParser()
title = raw_input('Please input the title you want:\n')
parsedata = tool.parsre(infile)
data = tool.appendHead(parsedata, title)
fulldata = tool.appendTail(data)
tool.output(fulldata, outfile)
结果展示
- 程序运行前
infile.md内容:
程序运行方法:
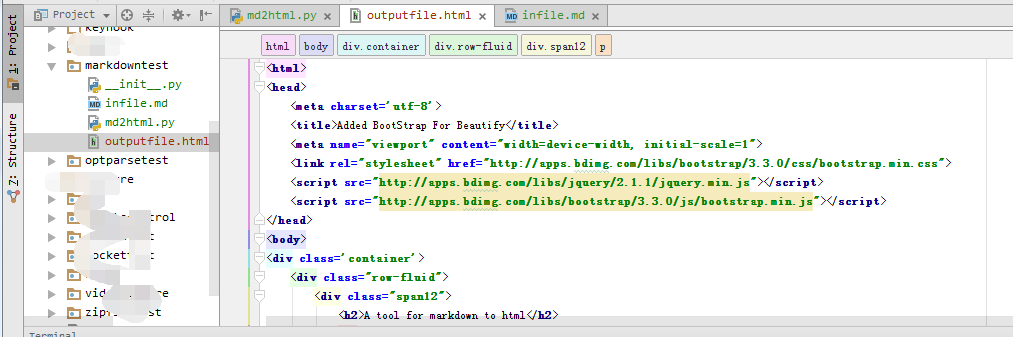
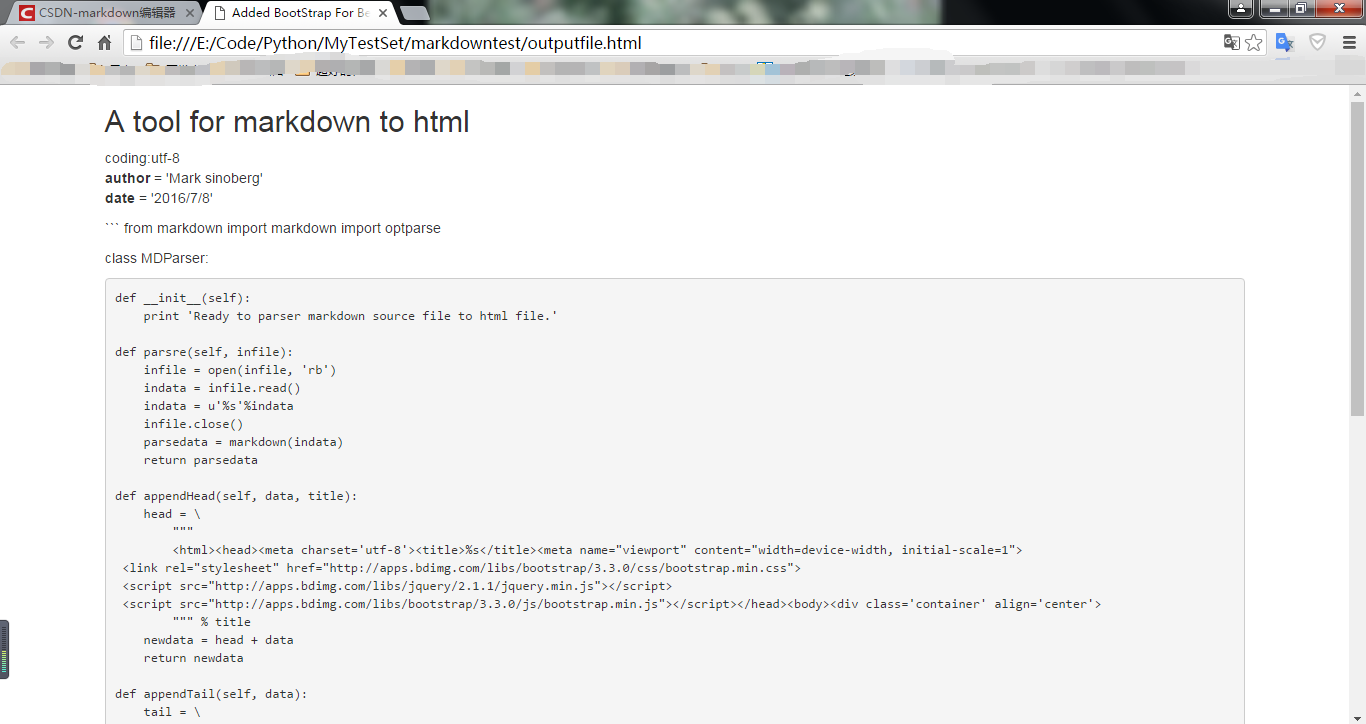
生成结果

缺点
这个工具最大的缺点就是不能将中文进行转换,原因是ascii码超出字符限制。
如果大家有更好的方法,不妨私信我! 大家一起学习!
我的DocUtil
https://github.com/guoruibiao/DocUtil。
欢迎拍砖!