作者简介:小小明,Pandas数据处理专家,致力于帮助无数数据从业者解决数据处理难题。
之前黄同学给我扔了一个问题:
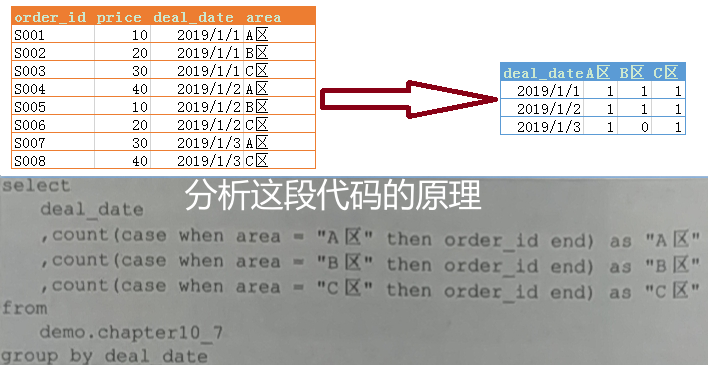
其实MySQL分组统计的实现原理,与Pandas几乎是一致的,只要我们理解了Pandas分组统计的实现原理,就能理解MySQL分组统计的原理。大体过程就是:
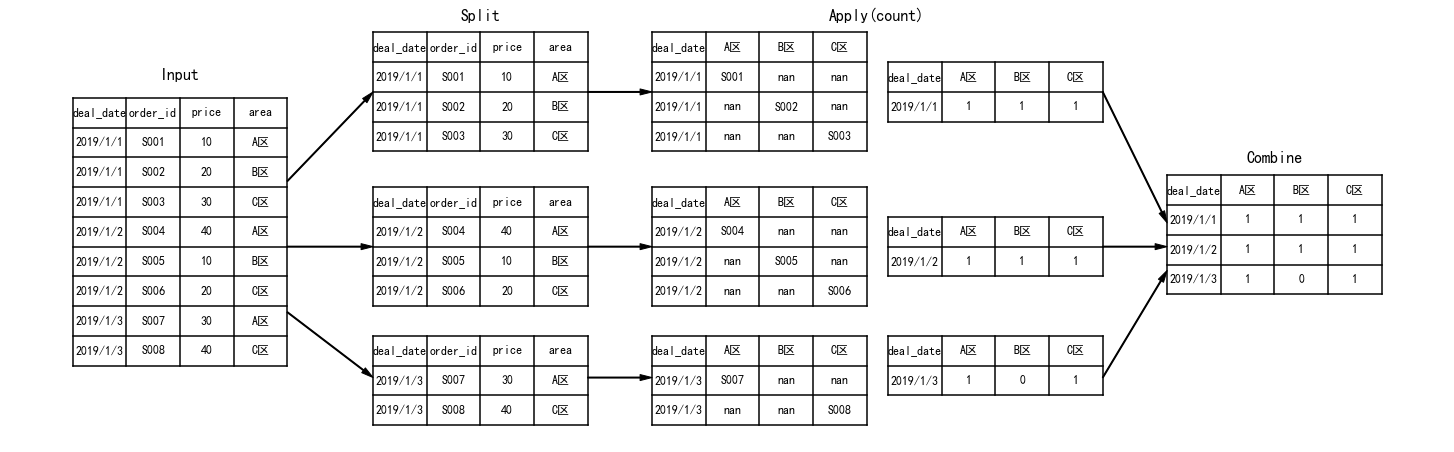
今天我将带大家从mysql的执行顺序(FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT)上,一步步通过Pandas向大家展示具体的执行过程,并借助Python基础编码,详解更细节的过程。
文章目录
MySQL实现分组统计的原理
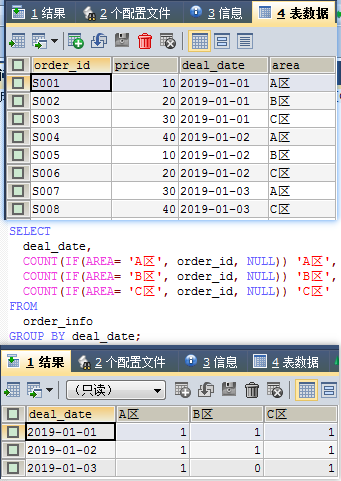
其实上面给的示例代码等价于:
SELECT
deal_date,
COUNT(IF(area= 'A区', order_id, NULL)) 'A区',
COUNT(IF(area= 'B区', order_id, NULL)) 'B区',
COUNT(IF(area= 'C区', order_id, NULL)) 'C区'
FROM
order_info
GROUP BY deal_date;
结果:
对于mysql标准的执行顺序是:
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
上面这个sql只涉及到FROM → GROUP BY → SELECT ,可以调整一下sql的阅读顺序:
FROM order_info
GROUP BY deal_date
SELECT
deal_date,
COUNT(IF(area= 'A区', order_id, NULL)) 'A区',
COUNT(IF(area= 'B区', order_id, NULL)) 'B区',
COUNT(IF(area= 'C区', order_id, NULL)) 'C区';
- FROM
首先FROM order_info表示读取order_info表的数据
- GROUP BY
GROUP BY deal_date表示按照deal_date分组
- SELECT
对每个分组选取指定的字段,并根据聚合函数对每个分组结果进行集合
其实MySQL的整个计算过程与Pandas相似,大体上都是下面的步骤:
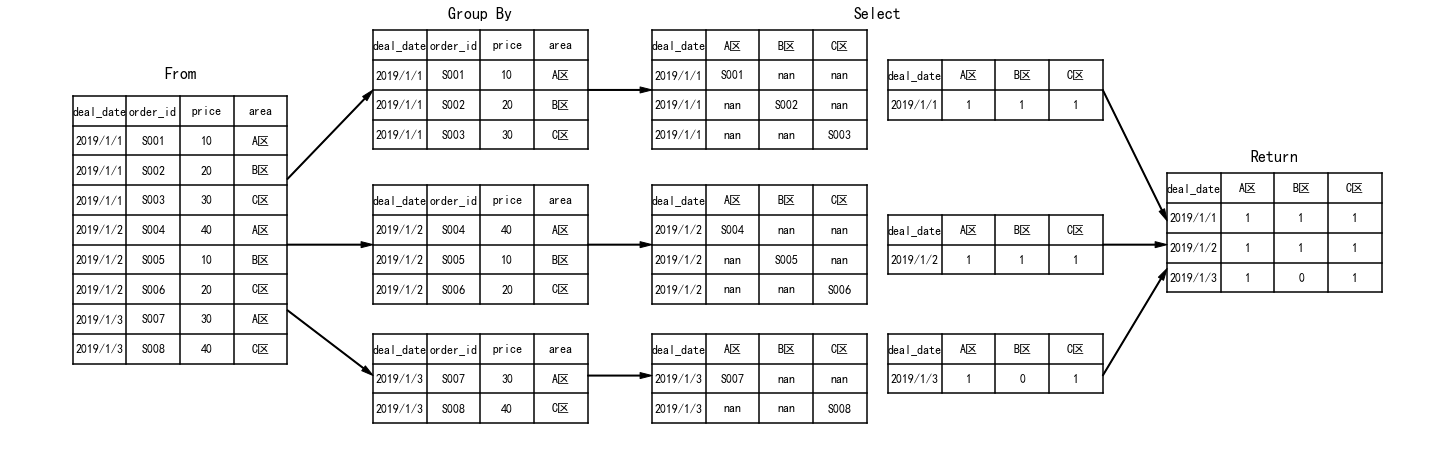
使用Pandas演示MySQL实现分组统计的过程
下面我使用Pandas来演示上面的执行过程。
From
FROM order_info本质就是读取数据:
import pandas as pd
data = pd.read_csv("data.csv", encoding="gb18030")
data
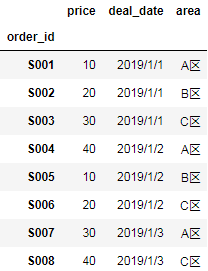
结果:
| order_id | price | deal_date | area | |
|---|---|---|---|---|
| 0 | S001 | 10 | 2019/1/1 | A区 |
| 1 | S002 | 20 | 2019/1/1 | B区 |
| 2 | S003 | 30 | 2019/1/1 | C区 |
| 3 | S004 | 40 | 2019/1/2 | A区 |
| 4 | S005 | 10 | 2019/1/2 | B区 |
| 5 | S006 | 20 | 2019/1/2 | C区 |
| 6 | S007 | 30 | 2019/1/3 | A区 |
| 7 | S008 | 40 | 2019/1/3 | C区 |
对于Mysql的任何InnoDB引擎表来说都存在一个主键索引,在没有指定任何字段作为主键时,InnoDB表会生成一个6字节空间的自增主键row_id作为主键。上面的Pandas表的Index(data.index)就相当于mysql表的自增主键row_id。
当然这张MySQL表指定order_id为主键时:
ALTER TABLE order_info ADD PRIMARY KEY (order_id);
就相当于:
data.set_index("order_id")
结果:
GROUP BY
GROUP BY deal_date表示按照deal_date分组,即:
df_group = data.groupby("deal_date")
df_group
结果:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000000016CE8278>
其实这步的本质是获取每个分组对应的主键id列表,可以通过DataFrameGroupBy对象的groups方法查看:
df_group.groups
结果:
{'2019/1/1': [0, 1, 2], '2019/1/2': [3, 4, 5], '2019/1/3': [6, 7]}
Pandas返回的是每个分组对应的索引列表,它等价于MySQL的主键id列表。
SELECT
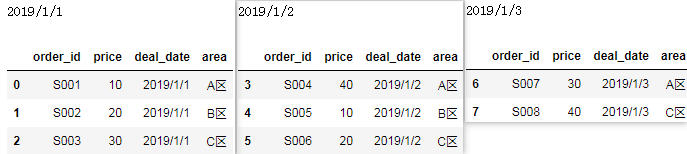
我们拿到每个分组对应的索引列表后,就可以拿到每个分组对应的全部数据:
for deal_date, ids in df_group.groups.items():
print(deal_date)
display(data.loc[ids])
结果:
当然,由于Pandas本身有现成的API,我们实际并不会这样遍历每个分区,而是:
for deal_date, split in df_group:
print(deal_date)
display(split)
这段Pandas遍历每个分区的本质就是上面的代码,返回结果也与上面完全相同。
对于MySQL的select这步:
SELECT
deal_date,
COUNT(IF(AREA= 'A区', 1, NULL)) 'A区',
COUNT(IF(AREA= 'B区', 1, NULL)) 'B区',
COUNT(IF(AREA= 'C区', 1, NULL)) 'C区'
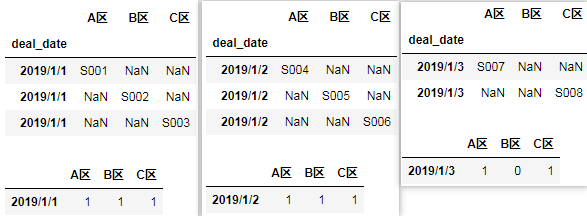
由于前面分组的存在,count()聚合函数将作用于每一个分组,用Pandas表达就是:
for deal_date, split in df_group:
split.loc[split.area == 'A区', 'A区'] = split.order_id
split.loc[split.area == 'B区', 'B区'] = split.order_id
split.loc[split.area == 'C区', 'C区'] = split.order_id
split = split.set_index('deal_date')
split = split[['A区', 'B区', 'C区']]
display(split)
display(split.count().to_frame(deal_date).T)
结果:
Return
最后MySQL计算完成后,就会合并每个分组的结果集,用Pandas表达就是:
result = []
for deal_date, split in df_group:
split.loc[split.area == 'A区', 'A区'] = split.order_id
split.loc[split.area == 'B区', 'B区'] = split.order_id
split.loc[split.area == 'C区', 'C区'] = split.order_id
split = split.set_index('deal_date')
split = split[['A区', 'B区', 'C区']]
result.append(split.count().to_frame(deal_date).T)
result = pd.concat(result)
result
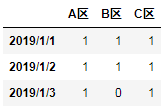
结果:
| A区 | B区 | C区 | |
|---|---|---|---|
| 2019/1/1 | 1 | 1 | 1 |
| 2019/1/2 | 1 | 1 | 1 |
| 2019/1/3 | 1 | 0 | 1 |
Pandas的分组聚合的执行过程
对于上面完整MySQL语句,整体执行流程等价于Pandas的:
def group_func(split):
split.loc[split.area == 'A区', 'A区'] = split.order_id
split.loc[split.area == 'B区', 'B区'] = split.order_id
split.loc[split.area == 'C区', 'C区'] = split.order_id
split = split[['A区', 'B区', 'C区']]
return split.count()
data.groupby('deal_date', as_index=False).apply(group_func)
结果与上面一致,整体流程是:
Python演示MySQL和Pandas实现分组的具体原理
上面的演示中:
data.groupby("deal_date").groups
结果:
{'2019/1/1': [0, 1, 2], '2019/1/2': [3, 4, 5], '2019/1/3': [6, 7]}
可以看到Pandas和MySQL分组这步其实都是计算出了每个分组对应的主键id(索引id)。但它们具体又是怎么实现的呢?
这时候,我用纯python来给大家演示一下。
不管是MySQL还是Pandas,都带有主键索引,只不过Pandas的索引不会因为重复而报错,而MySQL的索引是肯定唯一的,会覆盖前面索引相同的数据。
虽然MySQL将带有索引的数据存储到了磁盘上面,但为了方便,我只在内存上演示索引构建的过程。另外MySQL主键索引的数据结构一般是B+树,这里我用hash表(字典)来简单演示。
首先,读取数据并构建索引:
import csv
data = {}
columns = None
with open("data.csv", encoding="gb18030") as f:
f_csv = csv.reader(f)
columns = next(f_csv)
columns = dict(zip(columns, range(len(columns))))
for i, row in enumerate(f_csv):
data[i] = row
print(columns)
display(data)
结果:
{'order_id': 0, 'price': 1, 'deal_date': 2, 'area': 3}
{0: ['S001', '10', '2019/1/1', 'A区'],
1: ['S002', '20', '2019/1/1', 'B区'],
2: ['S003', '30', '2019/1/1', 'C区'],
3: ['S004', '40', '2019/1/2', 'A区'],
4: ['S005', '10', '2019/1/2', 'B区'],
5: ['S006', '20', '2019/1/2', 'C区'],
6: ['S007', '30', '2019/1/3', 'A区'],
7: ['S008', '40', '2019/1/3', 'C区']}
这样我们就读取数据并构建了主键索引,以及表的列名元信息。
下面我们开始实现分组:
# 获取分组数据所在的列
group_num = columns['deal_date']
id_groups = {}
for index, row in data.items():
group_key = row[group_num]
ids = id_groups.setdefault(group_key, [])
ids.append(index)
id_groups
结果:
{'2019/1/1': [0, 1, 2], '2019/1/2': [3, 4, 5], '2019/1/3': [6, 7]}
最后完成聚合计算:
result = {}
for deal_date, ids in id_groups.items():
areas = result.setdefault(deal_date, [0, 0, 0])
for index in ids:
area = data[index][columns['area']]
if area == 'A区':
areas[0] += 1
elif area == 'B区':
areas[1] += 1
elif area == 'C区':
areas[2] += 1
result
结果:
{'2019/1/1': [1, 1, 1], '2019/1/2': [1, 1, 1], '2019/1/3': [1, 0, 1]}
借助Pandas展示一下最终结果:
pd.DataFrame.from_dict(result, 'index', columns=["A区", "B区", "C区"])
结果:
总结
今天我通过Pandas和Python向你详细演示了MySQL分组聚合的整体执行流程,相信你已经对分组聚合有了更深层次的理解。
如果你觉得本文对你有所启发,希望得到你的点赞关注和评论。
作者博客地址:https://blog.csdn.net/as604049322
