断断续续的学了一下Python基础,但不常用,所以基本等于不会,于是便趁周末向各位网络大神学习一下Python爬虫来巩固一下
这里以我用的是Python2.7.5版本(好像Python3跟Python2的差别蛮大),Window7环境下PyCharm编辑器,特此说明
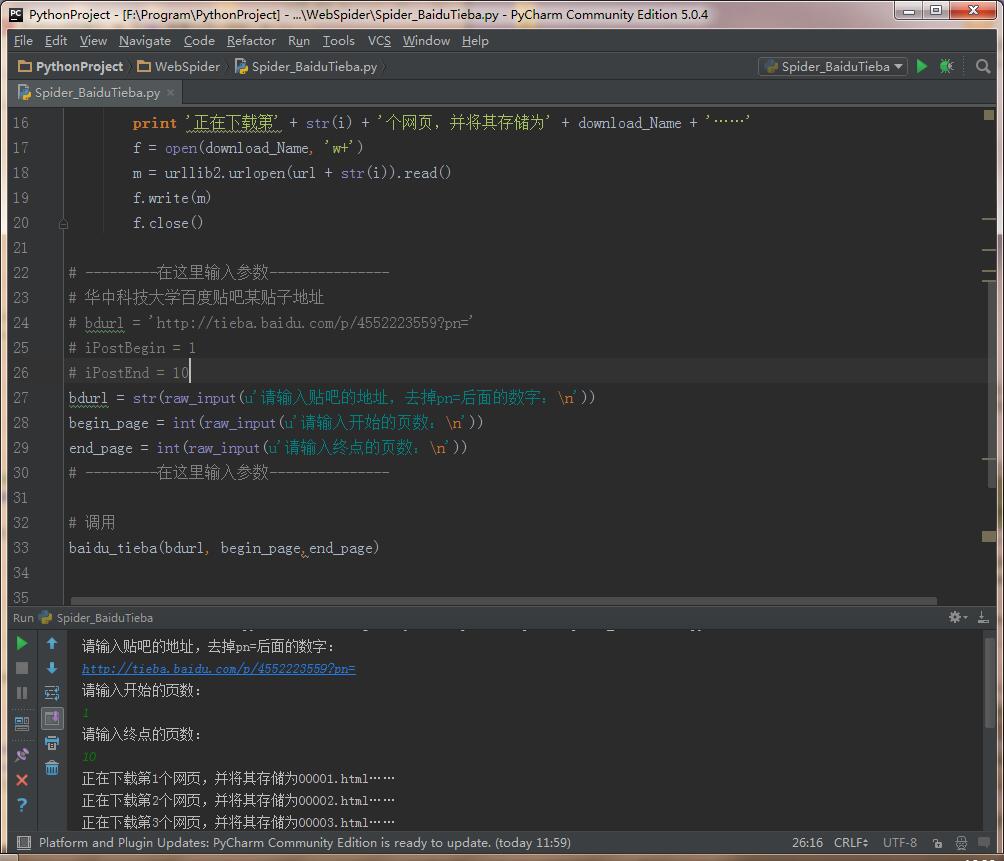
整体思路:先自定义一个爬取函数,参数列表有URL、页面起始地址和结束地址;然后分别读取每个页面,保存到本地
程序代码如下:(调用函数传入链接、所要爬取的页面起始和结束地址)
# -*- coding: utf-8 -*-
# -------------------------------
# 程序:百度贴吧爬虫
# 语言:Python 2.7
# 操作:输入带分布页的地址,去掉后面的数字,设置一下起始页数和终点页数
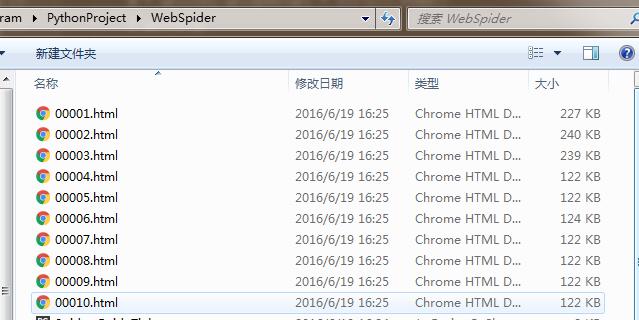
# 功能:下载对应页码内所有页面并存储为html文件
# -------------------------------
import string, urllib2
# 自定义百度贴吧爬取函数
def baidu_tieba(url, begin_page, end_page):
for i in range(begin_page, end_page+1):
download_Name = string.zfill(i, 5) + '.html' # 自动填充成六位的文件名,如string.zfill(3,5)的命名就是'00003.html'
print '正在下载第' + str(i) + '个网页,并将其存储为' + download_Name + '……'
f = open(download_Name, 'w+')
m = urllib2.urlopen(url + str(i)).read()
f.write(m)
f.close()
# ---------在这里输入参数---------------
# 华中科技大学百度贴吧某贴子地址
# bdurl = 'http://tieba.baidu.com/p/4552223559?pn='
# iPageBegin = 1
# iPageEnd = 10
bdurl = str(raw_input(u'请输入贴吧的地址,去掉pn=后面的数字:\n'))
begin_page = int(raw_input(u'请输入开始的页数:\n'))
end_page = int(raw_input(u'请输入终点的页数:\n'))
# ---------在这里输入参数---------------
# 调用上面定义的小爬虫
baidu_tieba(bdurl, begin_page,end_page)