前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
观察网页结构
进入起点原创风云榜:http://r.qidian.com/yuepiao?chn=-1
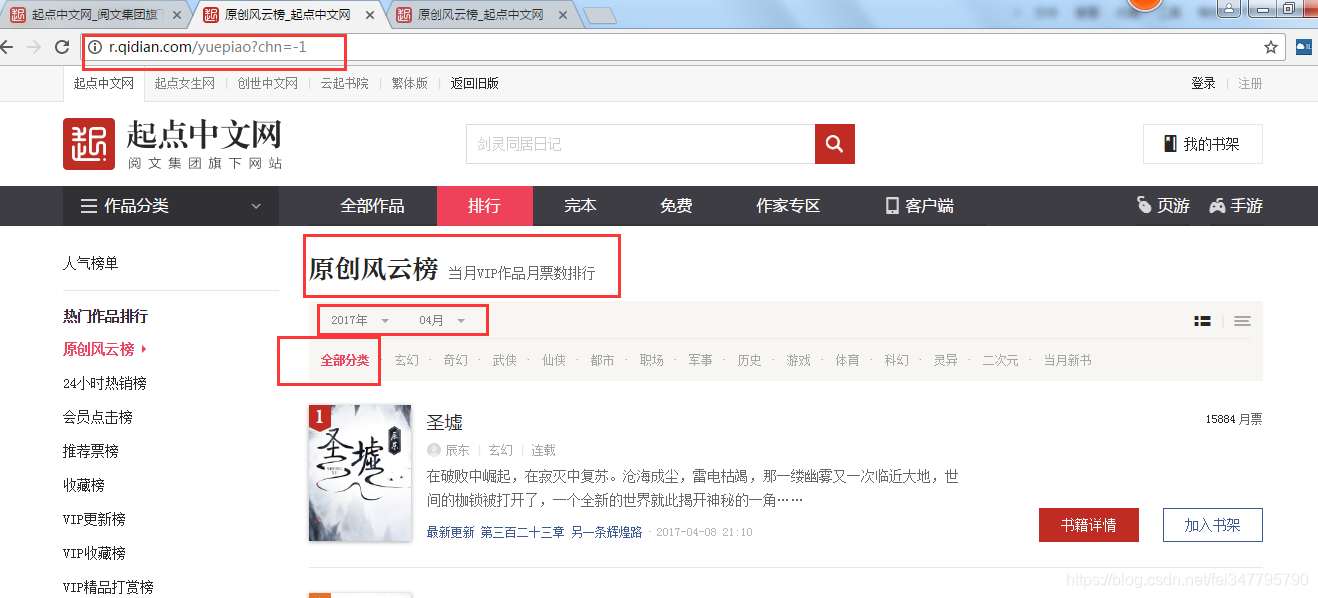
老套路,懂我的人都知道我要看看有多少内容和页数需要爬。

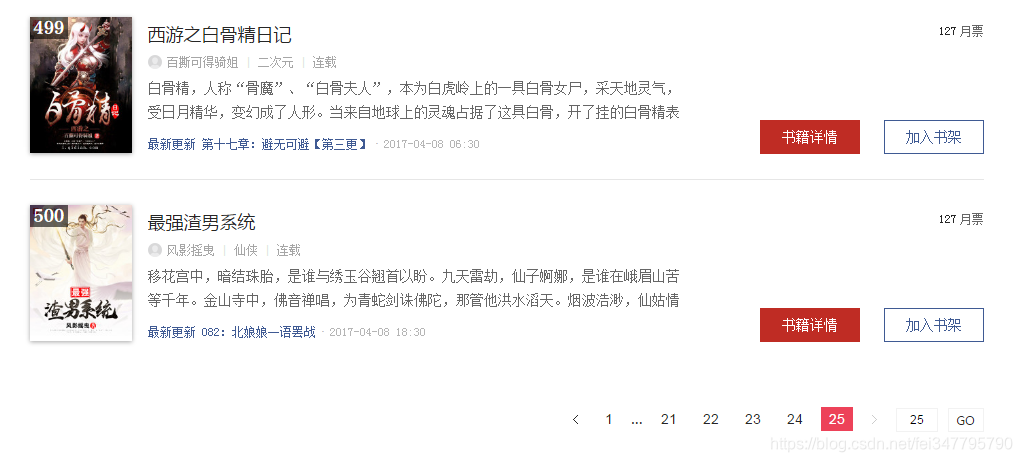
https://ask.hellobi.com/uploads/article/20170408/0b0192094e6d073f9a16bc3211e7e904.png

编写爬虫
import requests
from bs4 import BeautifulSoup
res=requests.get('http://r.qidian.com/yuepiao?chn=-1&page=1')
#print(res)#中间打印看看,好习惯
soup=BeautifulSoup(res.text,'html.parser')#
筛选器
#print(soup)
for news in soup.select('.rank-view-list li'):#定位
print(news)
结果如下:
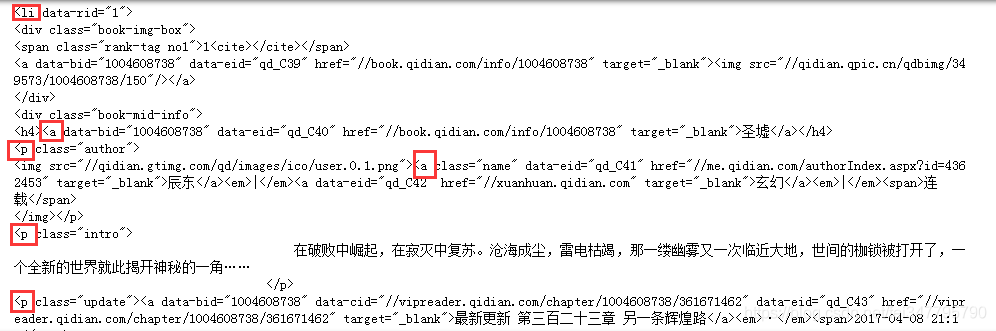
注意这些标签(因为美丽汤提取是基于标签的)
经过测试
for news in soup.select('.rank-view-list li'):#Wrap后面一定有个空格,因为网页里有
#print(news)
print(news.select('a')[1].text,news.select('a')[2].text,news.select('a')[3].text,news.select('p')[1].text,news.select('p')[2].text,news.select('a')[0]['href'])
可以设置提取内容如上面代码所示
提取结果是:

很乱,把内容存成字典格式再存放到列表中:
for news in soup.select('.rank-view-list li'):#Wrap后面一定有个空格,因为网页里有
#print(news)
#print(news.select('a')[1].text,news.select('a')[2].text,news.select('a')[3].text,news.select('p')[1].text,news.select('p')[2].text,news.select('a')[0]['href'])
newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[2].text,'url':news.select('a')[0]['href']})
使用pandas的DataFrame格式存放
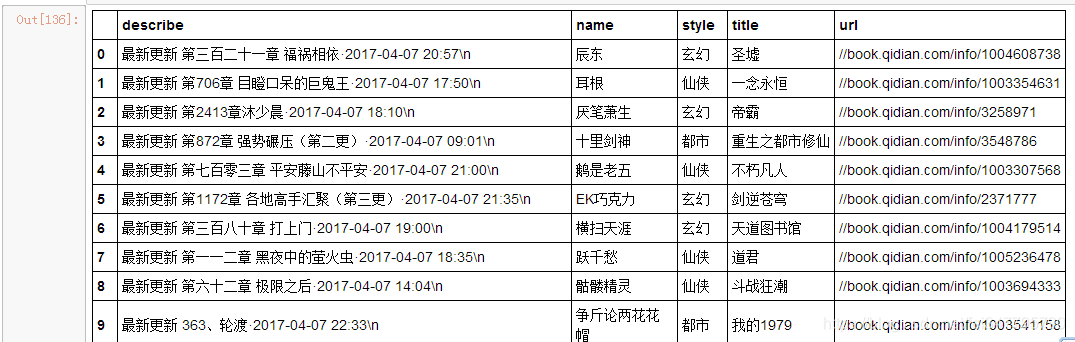
使用循环爬取25页内容
import requests
from bs4 import BeautifulSoup
newsary=[]
for i in range(25):
res=requests.get('http://r.qidian.com/yuepiao?chn=-1&page='+str(i))
#print(res)
soup=BeautifulSoup(res.text,'html.parser')
#print(soup)
#for news in soup.select('.rank-view-list h4'):#Wrap后面一定有个空格,因为网页里有
for news in soup.select('.rank-view-list li'):#Wrap后面一定有个空格,因为网页里有
#print(news)
#print(news.select('a')[1].text,news.select('a')[2].text,news.select('a')[3].text,news.select('p')[1].text,news.select('p')[2].text,news.select('a')[0]['href'])
newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[1].text,'lastest':news.select('p')[2].text,'url':news.select('a')[0]['href']})
import pandas
newsdf=pandas.DataFrame(newsary)
newsdf