观察网站结构
以本人所在的城市上海为例,走在上海的大街小巷,你会看到很多做房产中介的,最常见的就是链家了~
我们进一下链家的上海二手房页面:http://sh.lianjia.com/ershoufang/?utm_source=360&utm_medium=cpp&utm_term=链家二手房交易&utm_content=链家二手房&utm_campaign=品牌词
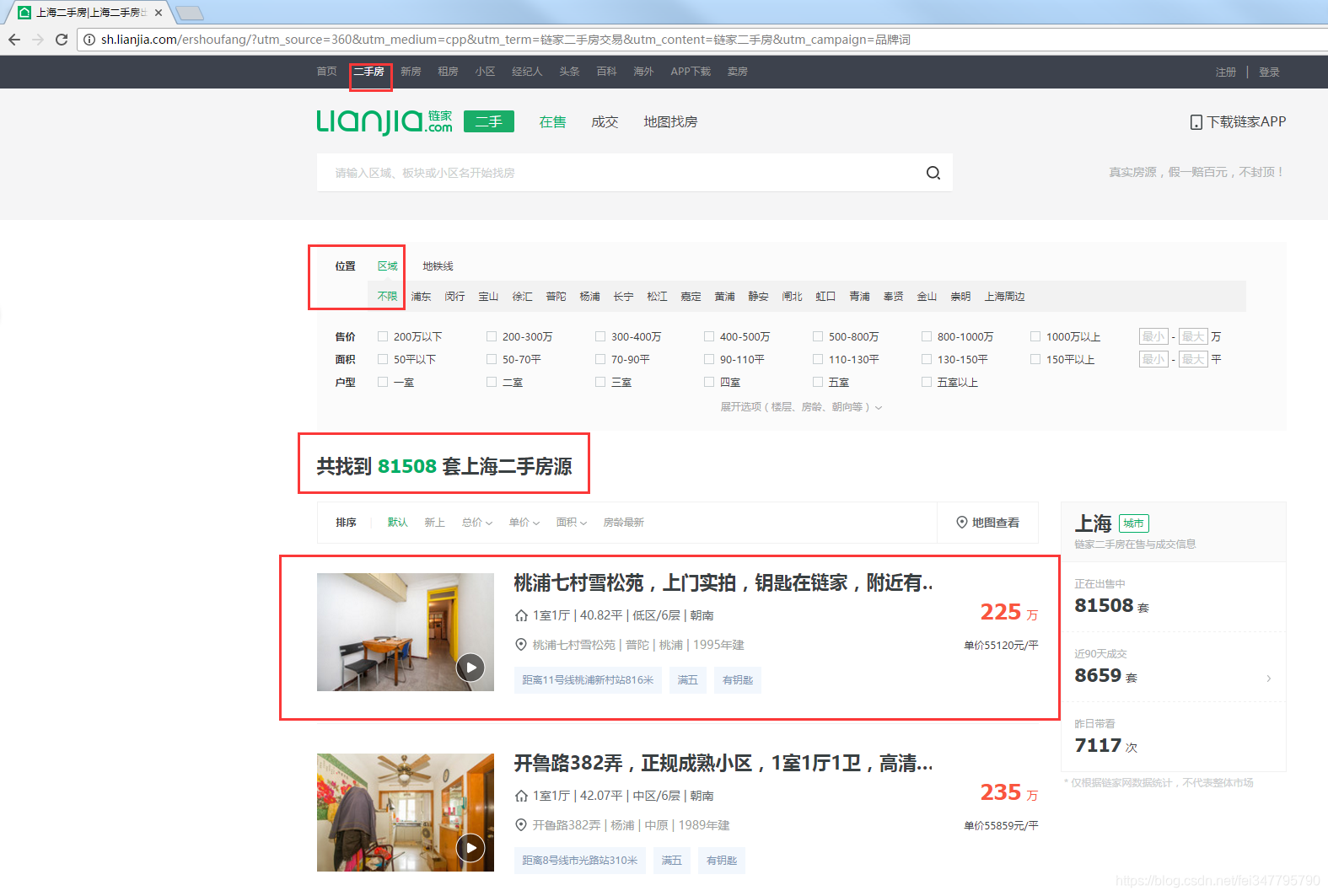
寻找需要爬取信息
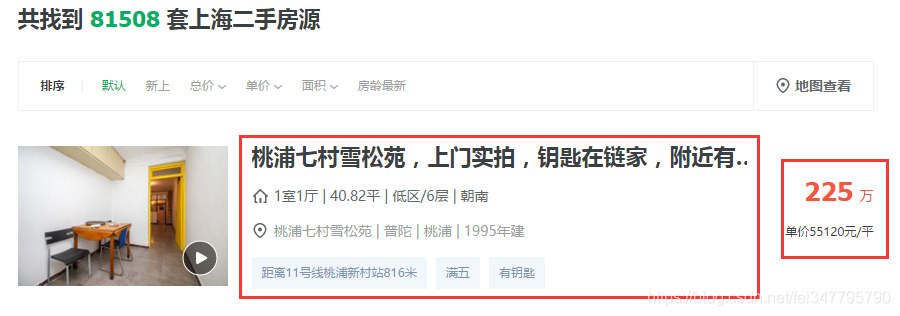
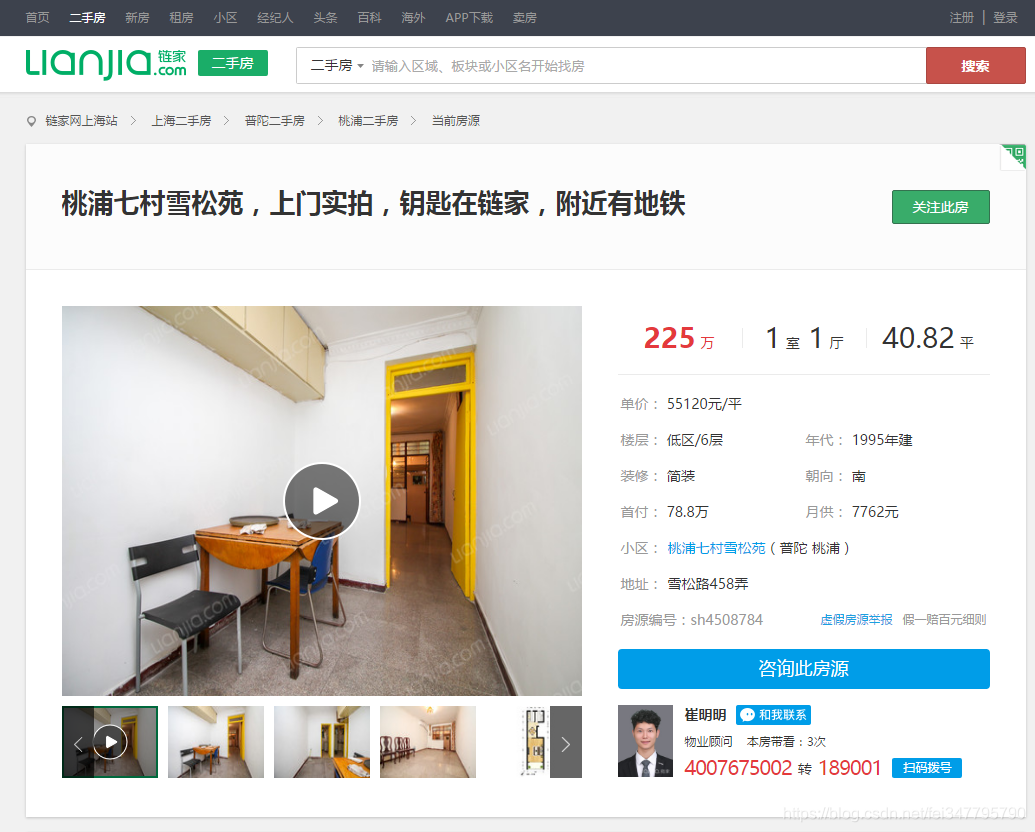
感觉这些红色框的我都想要,但是感觉还是不够全面,我们点击进去看看详细信息。
撰写爬虫
#主要程序
import requests
import re
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
'''
遇到不懂的问题?Python学习交流群:1136201545满足你的需求,资料都已经上传群文件,可以自行下载!
'''
ua=UserAgent()#使用随机header,模拟人类
headers1={'User-Agent': 'ua.random'}#使用随机header,模拟人类
houseary=[]#建立空列表放房屋信息
domain='http://sh.lianjia.com'#为了之后拼接子域名爬取详细信息
for i in range(1,400):#爬取399页,想爬多少页直接修改替换掉400,不要超过总页数就好
res=requests.get('http://sh.lianjia.com/ershoufang/d'+str(i),headers=headers1)#爬取拼接域名
soup = BeautifulSoup(res.text,'html.parser')#使用html筛选器
#print(soup)
for j in range(0,29):#网站每页呈现30条数据,循环爬取
url1=soup.select('.prop-title a')[j]['href']#选中class=prop-title下的a标签里的第j个元素的href子域名内容
url=domain+url1#构造子域名
houseary.append(gethousedetail1(url,soup,j))#传入自编函数需要的参数
def gethousedetail1(url,soup,j):#定义函数,目标获得子域名里的房屋详细信息
info={}#构造字典,作为之后的返回内容
s=soup.select('.info-col a')[1+3*j]#通过传入的j获取所在区的内容
pat='<a.*?>(.*?)</a>'#构造提取正则
info['所在区']=''.join(list(re.compile(pat).findall(str(s))))#使用join将提取的列表转为字符串
s1=soup.select('.info-col a')[0+3*j]#[0].text.strip()
pat1='<span.*?>(.*?)</span>'
info['具体地点']=''.join(list(re.compile(pat1).findall(str(s1))))
s2=soup.select('.info-col a')[2+3*j]#[0].text.strip()
pat2='<a.*?>(.*?)</a>'
info['位置']=''.join(list(re.compile(pat2).findall(str(s2))))
q=requests.get(url)#使用子域名
soup=BeautifulSoup(q.text,'html.parser')#提取子域名内容,即页面详细信息
for dd in soup.select('.content li'):#提取class=content标签下的li标签房屋信息
a=dd.get_text(strip=True)#推荐的去空格方法,比strip()好用
if ':' in a:#要有冒号的,用中文的冒号,因为网页中是中文
key,value=a.split(':')#根据冒号切分出键和值
info[key]=value
info['总价']=soup.select('.bold')[0].text.strip()#提取总价信息
return info#传回这一个页面的详细信息
写了详细注释,相信萌萌的你可以看懂~
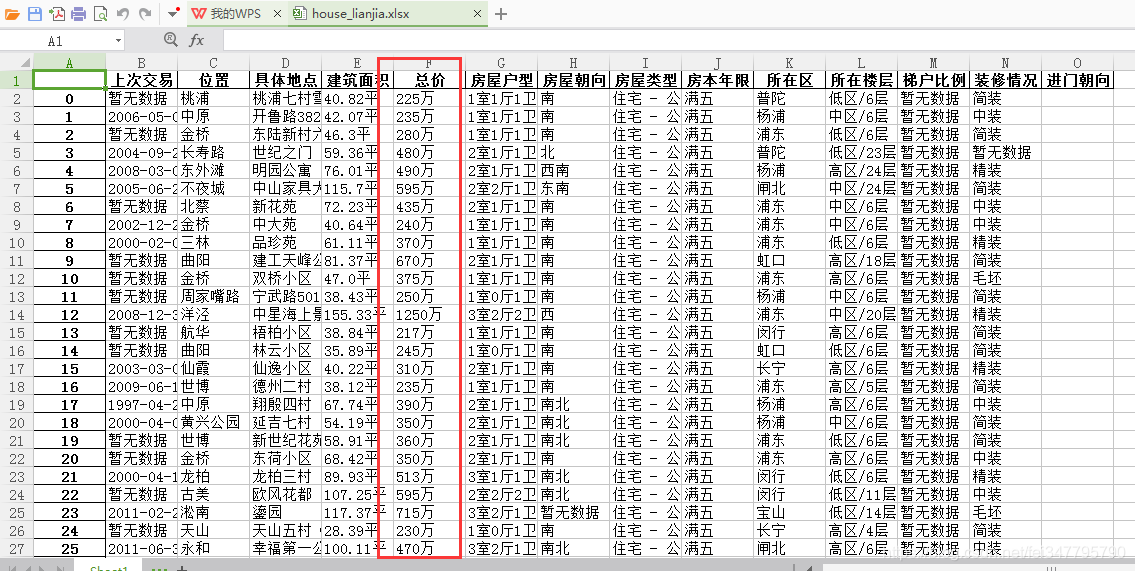
我们来看一下爬的结果:
houseary#看一下列表信息
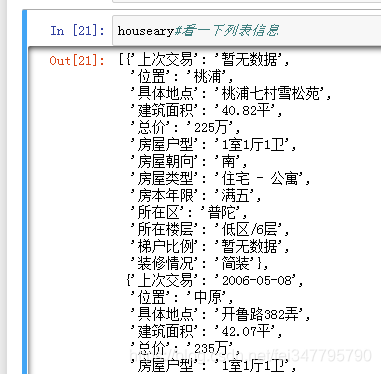
就是将每次爬取的信息做成dict依次添加在list中
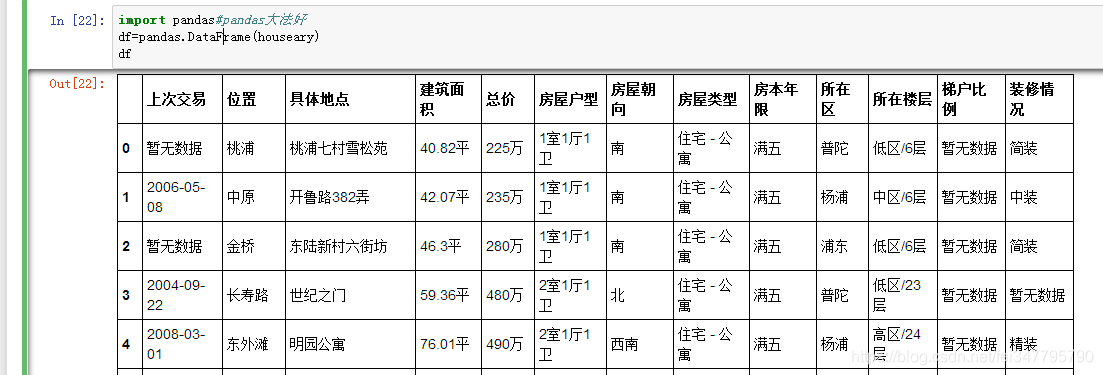
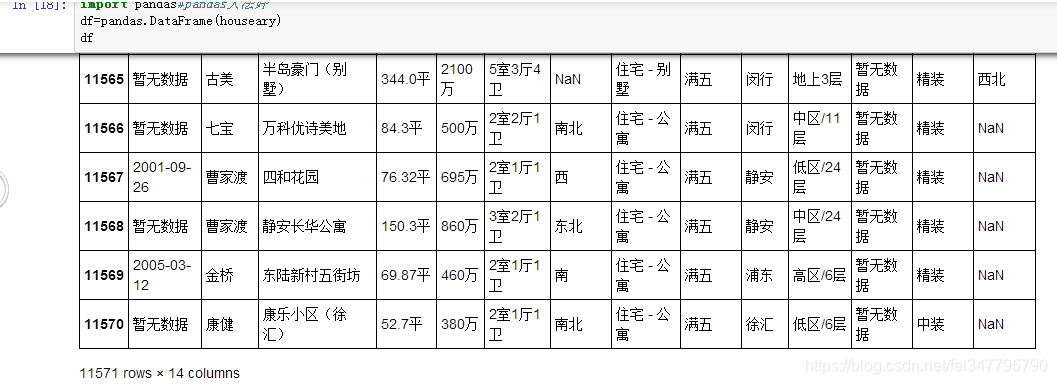
接下来使用pandas神器~
最后存到本地excel文件中