前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:刘早起
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入

那么今天我们用python看看这些评论里留下了哪些感人的故事
数据抓取
首先,我们用电脑打开网易云音乐这条视频的链接。找到最新评论,目标就是把这些评论全部取出来。接着发现每点击“下一页”,网站的url并没有任何变化,说明整个评论区的内容都是通过Ajax异步请求技术得到的。关于这个概念大家可以百度,简单来说就是能够实现在后台与服务器交换数据,在不重新加载页面的情况下更新网页。打开浏览器F12,进入开发者工具,选择Network,我们选择XHR(XmlHttpRequest)就可以选出Ajax的请求包:
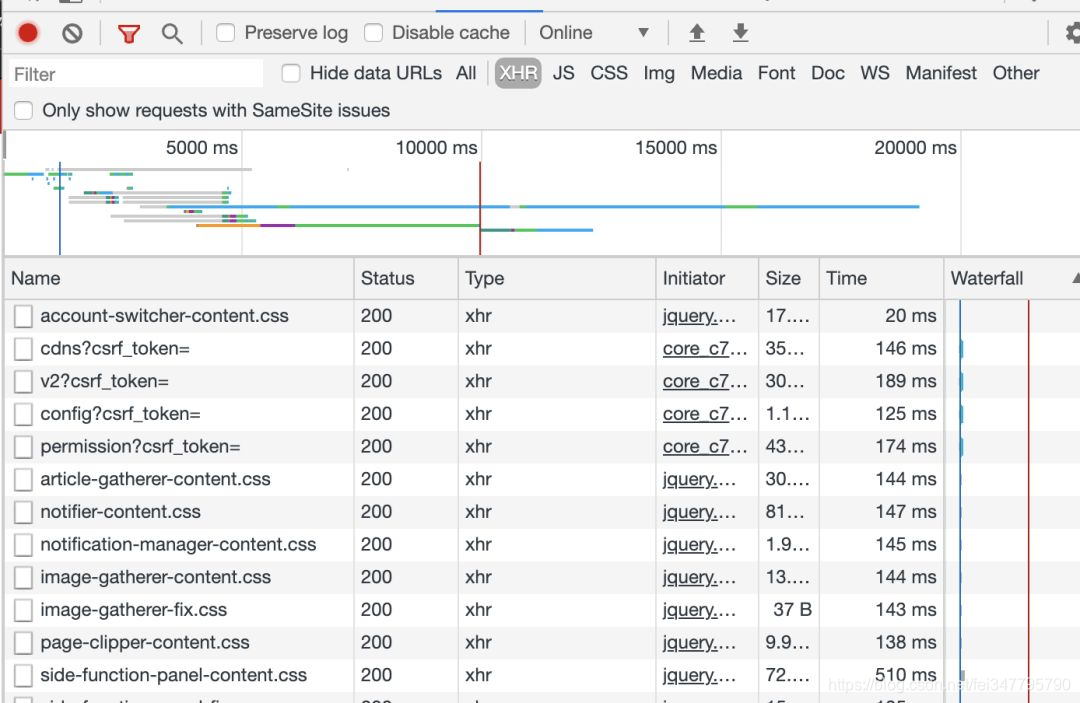
然后再一个个点进去查看response,就能找到包含评论的数据包⬇️
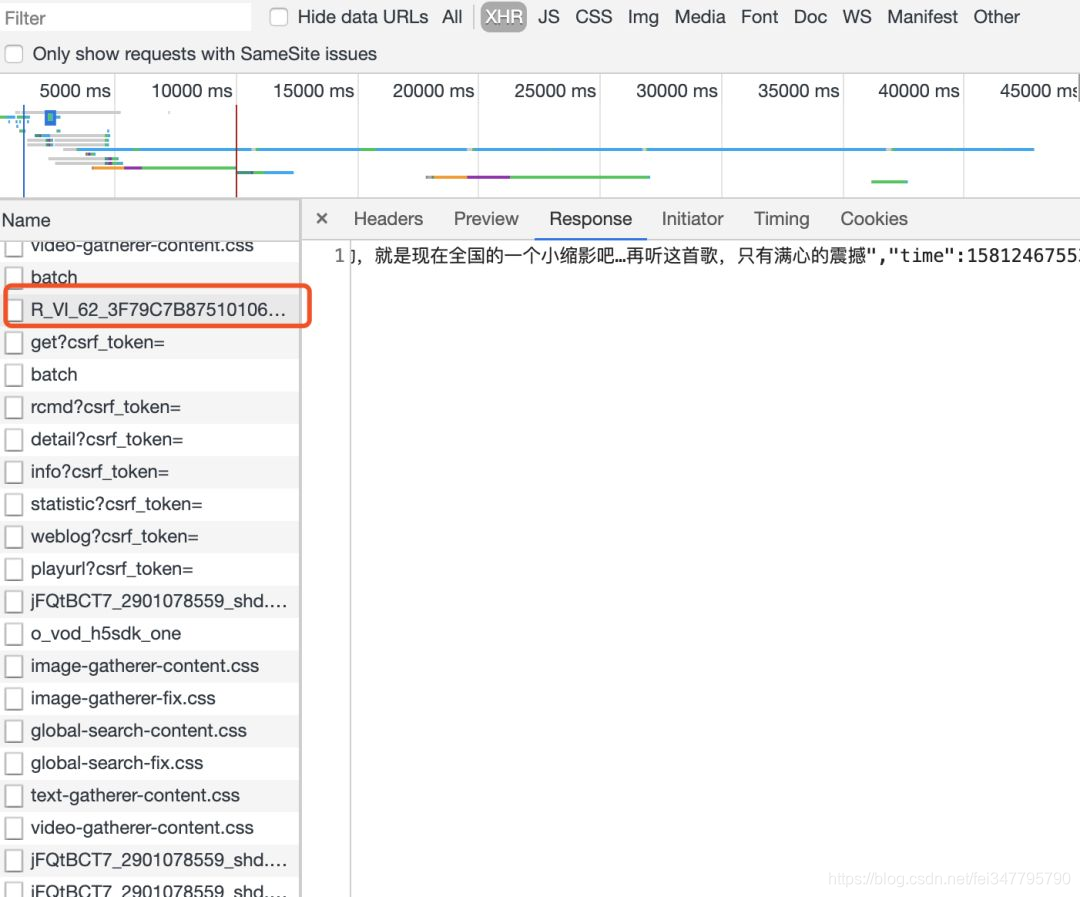
点进去就能看到header信息
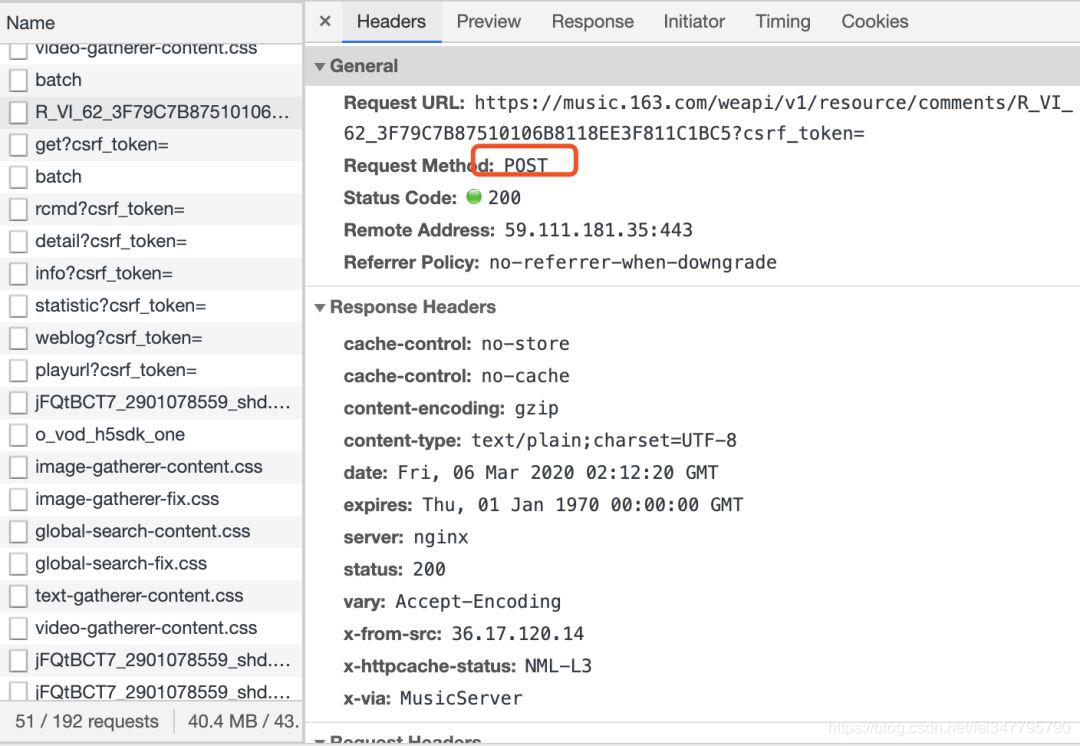
可以发现是一个post请求并且接收两个参数params以及encSecKey
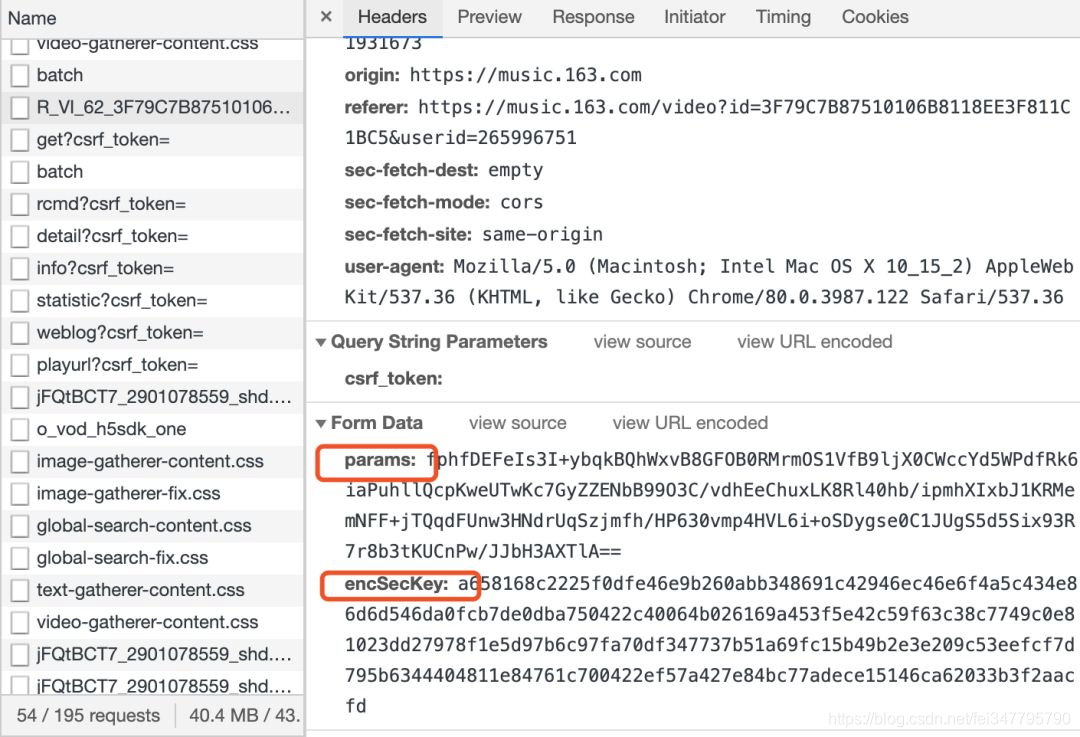
我们先来试试看
import requests
import json
url = 'https://music.163.com/weapi/v1/resource/comments/R_VI_62_3F79C7B87510106B8118EE3F811C1BC5?csrf_token='
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'Referer':'https://music.163.com/video?id=3F79C7B87510106B8118EE3F811C1BC5&userid=265996751',
'Origin':'http://music.163.com',
'Host':'music.163.com'
}
user_data = {
'params': 'fphfDEFeIs3I+ybqkBQhWxvB8GFOB0RMrmOS1VfB9ljX0CWccYd5WPdfRk6iaPuhllQcpKweUTwKc7GyZZENbB99O3C/vdhEeChuxLK8Rl40hb/ipmhXIxbJ1KRMemNFF+jTQqdFUnw3HNdrUqSzjmfh/HP630vmp4HVL6i+oSDygse0C1JUgS5d5Six93R7r8b3tKUCnPw/JJbH3AXTlA==',
'encSecKey': 'a658168c2225f0dfe46e9b260abb348691c42946ec46e6f4a5c434e86d6d546da0fcb7de0dba750422c40064b026169a453f5e42c59f63c38c7749c0e81023dd27978f1e5d97b6c97fa70df347737b51a69fc15b49b2e3e209c53eefcf7d795b6344404811e84761c700422ef57a427e84bc77adece15146ca62033b3f2aacfd'
}
response = requests.post(url,headers=headers,data=user_data)
可以发现能够取到这一页的评论信息
但是这只能拿到当前这一页的评论。那么怎样获取全部的评论信息呢,之前我们说过,点击下一页的时候只刷新评论,而不会重新加载页面。通过测试我们发现点击下一页时候只有 params和encSecKey会改变,那么接下来的问题就是就是搞明白这两个参数是怎样变化的。还好已经有知乎大神[1]给出了加密过程的解析与还原代码,所以我们直接拿过来用就可以。整个过程比较复杂,每个参数经过两次加密涉及到四个不同参数。由于篇幅原因完整的代码可以在早起python公众号内回复音乐获取。那么最后是将所有评论全部爬取下来。

数据分析
先来看下热评都在说什么

- 那有什么白衣天使,只不过是一群孩子穿上白衣服,学着前辈的样子治病救人罢了!
- 听到那句“妈妈在打怪兽呢”眼泪就掉下来了
- 武汉只是暂时被病毒藏起来!武汉加油
再来看下出现最多的词汇

毫无疑问是加油、武汉加油、中国加油出现的次数最多。最后制作词云图看下
from wordcloud import WordCloud
import matplotlib.pyplot as plt #绘制图像的模块
import jieba #jieba分词
path_txt='music.txt'
f = open(path_txt,'r',encoding='UTF-8').read()
# 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
cut_text = " ".join(jieba.cut(f))
wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="msyh.ttc",
#设置了背景,宽高
background_color="black",width=2000,height=880).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
最终生成的词云图⬇️可以看到:武汉加油!中国加油!
