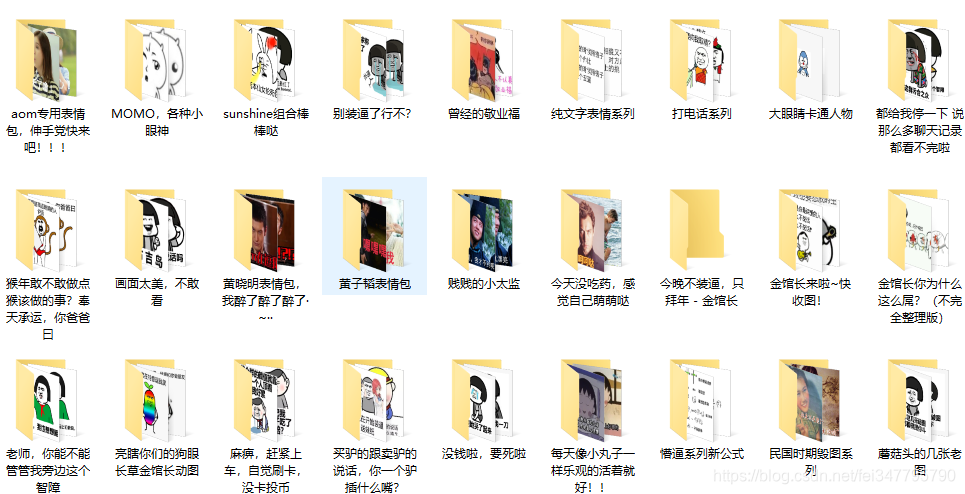
斗图啦表情包多线程爬取-撸代码
首先快速的导入我们需要的模块,和其他文章不同,我把相同的表情都放在了同一个文件夹下面,所以需要导入os模块
import asyncio
import aiohttp
from lxml import etree
import os
编写主要的入口方法
if __name__ == '__main__':
url_format = "http://www.doutula.com/article/list/?page={}"
urls = [url_format.format(index) for index in range(1,586)]
loop = asyncio.get_event_loop()
tasks = [x_get_face(url) for url in urls]
results = loop.run_until_complete(asyncio.wait(tasks))
我们是为了学习,不是为了攻击别人服务器,所以限制一下并发数量
sema = asyncio.Semaphore(3)
async def x_get_face(url):
with(await sema):
await get_face(url)
最后,一顿操作猛如虎,把所有的代码补全,就搞定了,这部分没有什么特别新鲜的地方,找图片链接,然后下载。
'''
遇到不懂的问题?Python学习交流群:1136201545满足你的需求,资料都已经上传群文件,可以自行下载!
'''
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
async def get_face(url):
print("正在操作{}".format(url))
async with aiohttp.ClientSession() as s:
async with s.get(url,headers=headers,timeout=5) as res:
if res.status==200:
html = await res.text()
html_format = etree.HTML(html)
hrefs = html_format.xpath("//a[@class='list-group-item random_list']")
for link in hrefs:
url = link.get("href")
title = link.xpath("div[@class='random_title']/text()")[0] # 获取文件头部
path = './biaoqings/{}'.format(title.strip()) # 硬编码了,你要先在项目根目录创建一个biaoqings的文件夹
if not os.path.exists(path):
os.mkdir(path)
else:
pass
async with s.get(url, headers=headers, timeout=3) as res:
if res.status == 200:
new_html = await res.text()
new_html_format = etree.HTML(new_html)
imgs = new_html_format.xpath("//div[@class='artile_des']")
for img in imgs:
try:
img = img.xpath("table//img")[0]
img_down_url = img.get("src")
img_title = img.get("alt")
except Exception as e:
print(e)
async with s.get(img_down_url, timeout=3) as res:
img_data = await res.read()
try:
with open("{}/{}.{}".format(path,img_title.replace('\r\n',""),img_down_url.split('.')[-1]),"wb+") as file:
file.write(img_data)
except Exception as e:
print(e)
else:
pass
else:
print("网页访问失败")
等着,大量的表情包就来到了我的碗里。