1.1 获取页面信息
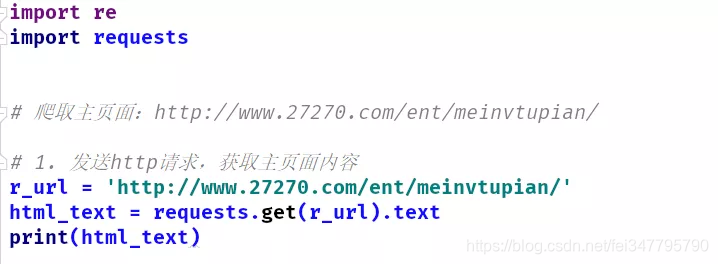
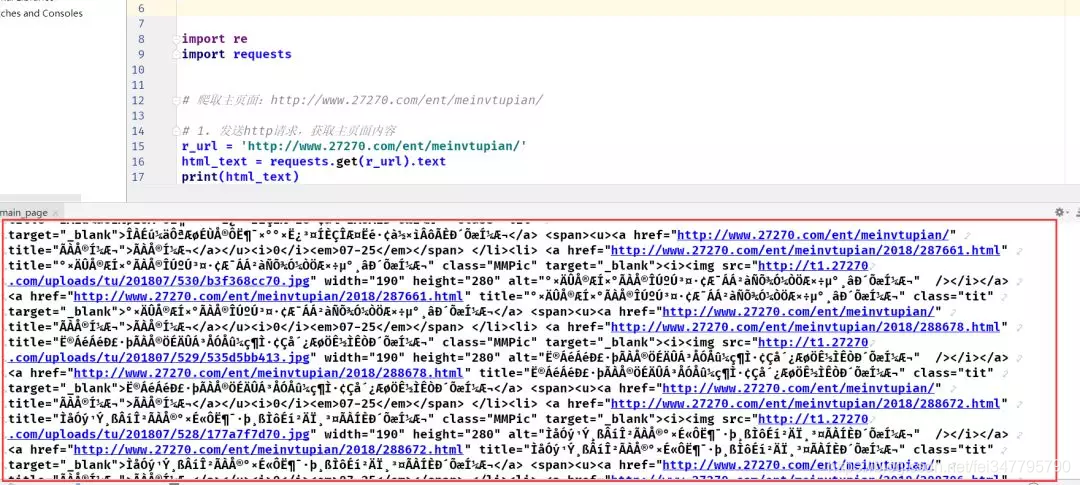
1.2 发现获取页面内容出现乱码
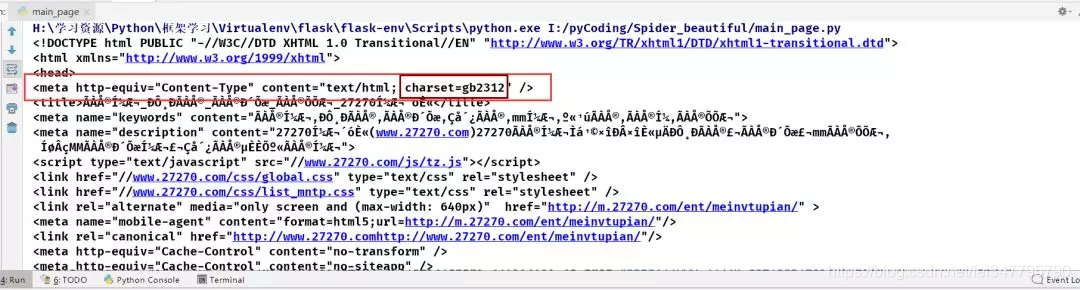
1.3 分析页面信息得原页面编码为:gb2312,修改获取内容编码
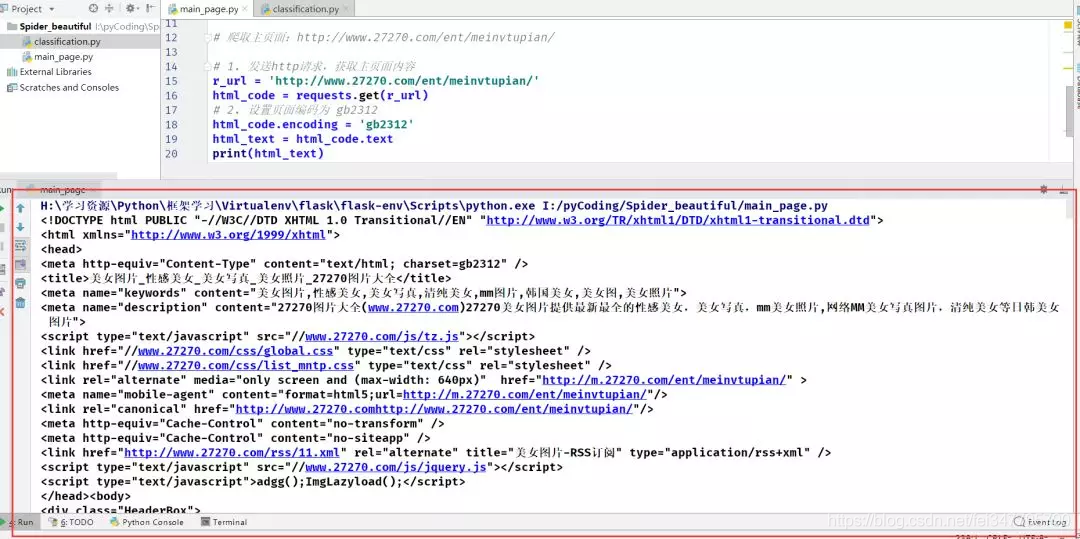
2.1 主页面源码已经获取到了,那我们到网页里看看源码的效果图吧
完整代码
import re
import os
import requests
'''
小编准备的python学习资料,加群:1136201545 即可免费获取!
'''
# 爬取主页面:http://www.27270.com/ent/meinvtupian/
# 下载图片函数
'''
folder_name : 文件夹名称,按图片简介
picture_address : 一组图片的链接
'''
def download_pictures(folder_name, picture_address):
file_path = r'G:\Beautiful\{0}'.format(folder_name)
if not os.path.exists(file_path):
# 新建一个文件夹
os.mkdir(os.path.join(r'G:\Beautiful', folder_name))
# 下载图片保存到新建文件夹
for i in range(len(picture_address)):
# 下载文件(wb,以二进制格式写入)
with open(r'G:\Beautiful\{0}\0{1}.jpg'.format(folder_name,i+1), 'wb') as f:
# 根据下载链接,发送请求,下载图片
response = requests.get(picture_address[i][0])
f.write(response.content)
# 1. 发送http请求,获取主页面内容
r_url = 'http://www.27270.com/ent/meinvtupian/'
html_code = requests.get(r_url)
# 2. 设置页面编码为 gb2312
html_code.encoding = 'gb2312'
html_text = html_code.text
# print(html_text)
# 3. 从主页面提取出所有图片组简介及图片组的链接
# pattern = r'<a href="(.*?)" title=".*?" class="MMPic" target="_blank"><i><img src=".*?" width="190" height="280" alt=".*?" /></i></a>'
# 3.1 获取链接
pattern01 = r'<a href="(.*?)" title=".*?" class="tit" target="_blank">.*?</a> <span><u><a href="http://www.27270.com/ent/meinvtupian/" title="美女图片">美女图片</a>'
beautiful_url = re.findall(pattern01, html_text)
# print(beautiful_url)
print(len(beautiful_url))
# 3.2 获取简介
pattern02 = r'<a href=".*?" title=".*?" class="MMPic" target="_blank"><i><img src=".*?" width="190" height="280" alt="(.*?)" /></i></a>'
beautiful_words = re.findall(pattern02, html_text)
# print(beautiful_words)
print(len(beautiful_words))
# len(beautiful_url)
for i in range(len(beautiful_url)):
# 4.1 请求单个页面
picture_codes = requests.get(beautiful_url[i])
picture_codes.encoding = 'gb2312'
picture_words = picture_codes.text
picture_address = []
# 4.2 在页面中找到图片url
# print(picture_words)
pattern03 = r'<img alt="%s" src="(.*?)" />'%beautiful_words[i]
picture_01 = re.findall(pattern03, picture_words)
picture_address.append(picture_01)
# 4.3 翻页爬取
# 4.3.1 获取翻页链接
pattern04 = r"<li><a href='(.*?)'>.*?</a></li>"
pictures_url = re.findall(pattern04, picture_words)
print(pictures_url)
print(pattern03)
# 4.3.2 翻页,获取图片地址
for j in range(len(pictures_url)):
other_picture_url = r'http://www.27270.com/ent/meinvtupian/2018/{0}'.format(pictures_url[j])
pictures_codes = requests.get(other_picture_url)
pictures_codes.encoding = 'gb2312'
pictures_words = pictures_codes.text
picture_02 = re.findall(pattern03, pictures_words)
picture_address.append(picture_02)
print(picture_address)
download_pictures(beautiful_words[i],picture_address)
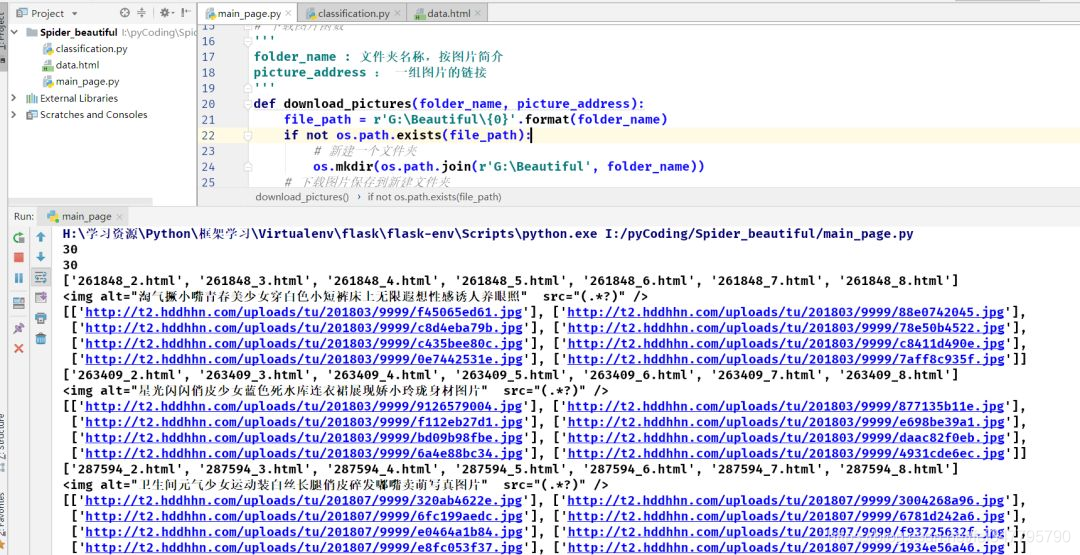
运行结果
 .
.
