之前在搜索一些资料的时候,发现开源中国这个博客网站有一大亮点。那就是一张技能雷达图。大致如下:

但是遗憾的是CSDN官方并不支持这一实现,其实对于技能雷达图而言,言简意赅的能表现出一个技术者擅长的领域,以及不擅长的领域。
抱着玩一玩的态度,我也着手实现了一下针对CSDN博客用户的技能雷达图。下面先来看下最终实现的效果图。
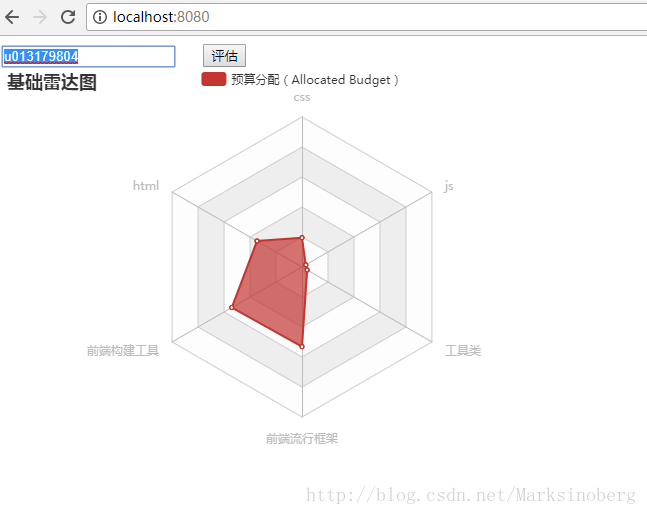
接下来记录一下整体的实现流程。
思路
根据用户指定的博客ID,找到其文章分类情况。然后分别计算分类下文章的得分情况。
这个得分默认按照CSDN官方的规则计算。即:
- 博文每增加300个浏览量,积分加1
- 被人评论加一分
- 被人点赞加一分
- 被人点踩减一分
这里用的规则不是很适合,但是一般而言,一篇博客的浏览量,在一定程度上也代表了这篇文章的质量。
核心代码
计算部分
按照思路,这又是一个简单爬虫相关了。代码中已经做了比较详细的注释。
#!usr/bin/env python
# coding: utf8
import requests
import math
import re
from bs4 import BeautifulSoup
class Radar(object):
"""
技术雷达实现
"""
def __init__(self, username):
"""初始化用户名以及相应的域名前缀"""
self.username = username
self.domain = "http://blog.csdn.net"
def download(self, url):
"""下载通用方法"""
headers = {
'Host': 'blog.csdn.net',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
return response.text if response.status_code == 200 else None
def str_concat(self, *args):
""" 字符串拼接方法,满足不定参数的实现"""
tempstr = ''
for item in args:
tempstr += item
return tempstr
def get_catagories(self):
"""
计算username对应的文章类别信息,获取类别名称, 对应的URL以及为其设置编号
"""
url = self.str_concat(self.domain, '/', self.username)
html = self.download(url=url)
soup = BeautifulSoup(html, 'html.parser')
temp_catagories = soup.find_all('div', {'id': 'panel_Category'})[-1].find_all('a')
catagory = []
for index, item in enumerate(temp_catagories):
counts = soup.find_all('div', {'id': 'panel_Category'})[-1].find_all('span')[index+1].get_text().lstrip('(').rstrip(')')
obj = {
"url": self.str_concat(self.domain, item.attrs['href']),
"name": item.get_text(),
"counts": int(counts)
}
catagory.append(obj)
# 返回类别相关的计算结果
return catagory
def trim_list(self, ls):
"""
列表去重
"""
return list(set(ls))
def get_posts(self, catagory_url, counts):
"""
根据给定的类别URL,获取该类别下所有的文章的链接以及标题信息等
"""
html = self.download(url=catagory_url)
# 先使用正则来获取给类别对应的文章总数,以及总页数
posts_number, pages = counts, math.ceil(counts/20)
html = None
# 声明一个保存文章信息的容器列表
posts = []
# 对每一页的链接进行爬取,获取对应页面文章的标题以及链接 int(pages)+1
for index in range(1, int(pages) + 1):
# print("正在处理第{}页".format(index))
url = self.str_concat(catagory_url, '/', str(index))
html = self.download(url=url)
soup = BeautifulSoup(html, 'html.parser')
page_posts = soup.find_all('span', {'class': 'link_title'})
for item in page_posts:
url = re.findall(re.compile('href="(.*?)"'), str(item))
if(url == []):
continue
posts.append(self.str_concat(self.domain, url[0]))
# print("第{}页的数据为:{}个".format(index, len(page_posts)))
return self.trim_list(posts)
def get_detail(self, posturl):
"""
根据指定的博文URL链接,计算出改文章大致的得分情况。
默认按照CSDN官方计算规则实现。
每300浏览量加一分;一个赞加一分;一个评论加一分;一个踩扣一分
"""
html = self.download(url=posturl)
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('span', {'class': 'link_title'}).get_text()
watches = re.findall(re.compile('.*?(\d+).*?'), soup.find('span',{'class': "link_view"}).get_text())[0]
comments = re.findall(re.compile('.*?\((\d+)\).*?'), soup.find('span',{'class': "link_comments"}).get_text())[0]
diggs = soup.find('dl', {'id': 'btnDigg'}).find('dd').get_text()
buries = soup.find('dl', {'id': 'btnBury'}).find('dd').get_text()
# 简单 计算出每篇文章的得分情况
print('正在计算 {} 的得分情况。'.format(posturl))
return int(watches)/300+int(comments)+int(diggs)-int(buries)
整合胶水
模块功能已经完善了,接下来就是将这一个个的小模块给整合起来,在更高层次上做伪自动化。
#!/usr/bin/env python
# coding: utf8
from compute import Radar
def compute(username):
"""
计算出username对应的文章得分情况。
"""
radar = Radar(username=username)
catagroies = radar.get_catagories()
for catagory in catagroies:
# 先求出每一个分类下的所有的文章链接。然后计算出总分数
counts = catagory['counts']
posturls = radar.get_posts(catagory_url=catagory['url'], counts=counts)
score = 0
for posturl in posturls:
score += radar.get_detail(posturl=posturl)
print('{}的总体得分为:{}'.format(catagory['name'], score))
catagory['score'] = score
return catagroies服务器端
为了实现技能雷达图的目标,需要开一个本地的web服务,因为Flask比较顺手,所以就用它好了。
#!/usr/bin/env python
# coding: utf8
import json
from utils import compute
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/api/user/<username>', methods=['GET', 'POST'])
def get_user_score(username):
catagories = compute(username=username)
return json.dumps(catagories)
@app.route('/')
def home():
return render_template('index.html')
if __name__ == "__main__":
app.run(host='localhost', port=8080, debug=True)
下面的这个接口,作为待会的ajax请求调用。
http://localhost:8080/api/user/username(博客ID)前端
因为用到了JQuery和echarts,所以要对flask进行静态资源和模板的设置。
具体的做法如下:
- 对于模板: 模板文件放到网站根目录的templates下
- 对于CSS,JS,Image。放到网站根目录下的static目录下。
具体引用时按照文件在服务器上的绝对路径进行处理。比如static目录下的js目录下的jquery.min.js文件,在模板中要这么写:
<script src="/static/js/jquery.min.js"</script>其他静态资源文件同理。
然后就是使用ajax实现对技能数据的获取以及更新了。详见下面的完整代码:
<html>
<head>
<meta charset="UTF-8">
<title>技术雷达图</title>
<script src="/static/echarts.min.js"></script>
<script src="/static/jquery-2.2.4.min.js"></script>
</head>
<body>
<input type="text" id="username" placeholder="请输入CSDN博主ID">
<input type="button" id="compute" value="评估"><br/>
<div id="container" style="width: 600px;height:400px;"></div>
</body>
<script>
var mycharts = echarts.init(document.getElementById('container'));
mycharts.showLoading();
var names = [];
var scores = [];
function prepare_data() {
$(document).ready(function () {
$.ajax({
url: 'http://localhost:8080/api/user/' + $("#username").val(),
dataType: 'json',
success: function (result) {
mycharts.hideLoading();
// 计算相关数据
for (var index = 0; index < result.length; index++) {
names.push({
name: result[index].name,
max: 25
});
scores.push(
result[index].score
);
}
console.log(JSON.stringify(names));
console.log(JSON.stringify(scores));
show_data();
},
error: function (err) {
console.log(JSON.stringify(err));
}
})
});
}
function show_data() {
var option = {
title: {
text: '基础雷达图'
},
tooltip: {},
legend: {
data: ['预算分配(Allocated Budget)', '实际开销(Actual Spending)']
},
radar: {
indicator: names
},
series: [{
name: '预算 vs 开销(Budget vs spending)',
type: 'radar',
areaStyle: { normal: {} },
data: [
{
value: scores,
name: '预算分配(Allocated Budget)'
}
]
}]
};
mycharts.setOption(option);
// 触发ajax事件,计算给定用户名博主的技术雷达计算。
// 先响应一个加载动画比较好。
mycharts.hideLoading();
}
$("#compute").click(function () {
prepare_data();
});
</script>
</html>最终效果
因为系统是实时计算的,所以对于文章比较多的用户而言,需要等待较长的时间,但是功能上差不多就算是完成了。
总结
回顾一下,这里的计算规则其实还是有很大漏洞的。应该将类别的总积分除以类别下文章的数目,求取一个比较平均的值来降低误差。
另外,雷达图上限是随意指定的,所以没什么价值。正规而言应该是需要一套比较严格的标准来进行参考,这样才有价值。
echarts确实是一款网页展示图标的神器,而且官网上给的例子非常的清晰,准备好数据,交给ajax,这样就完事了,省心,省力。