前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
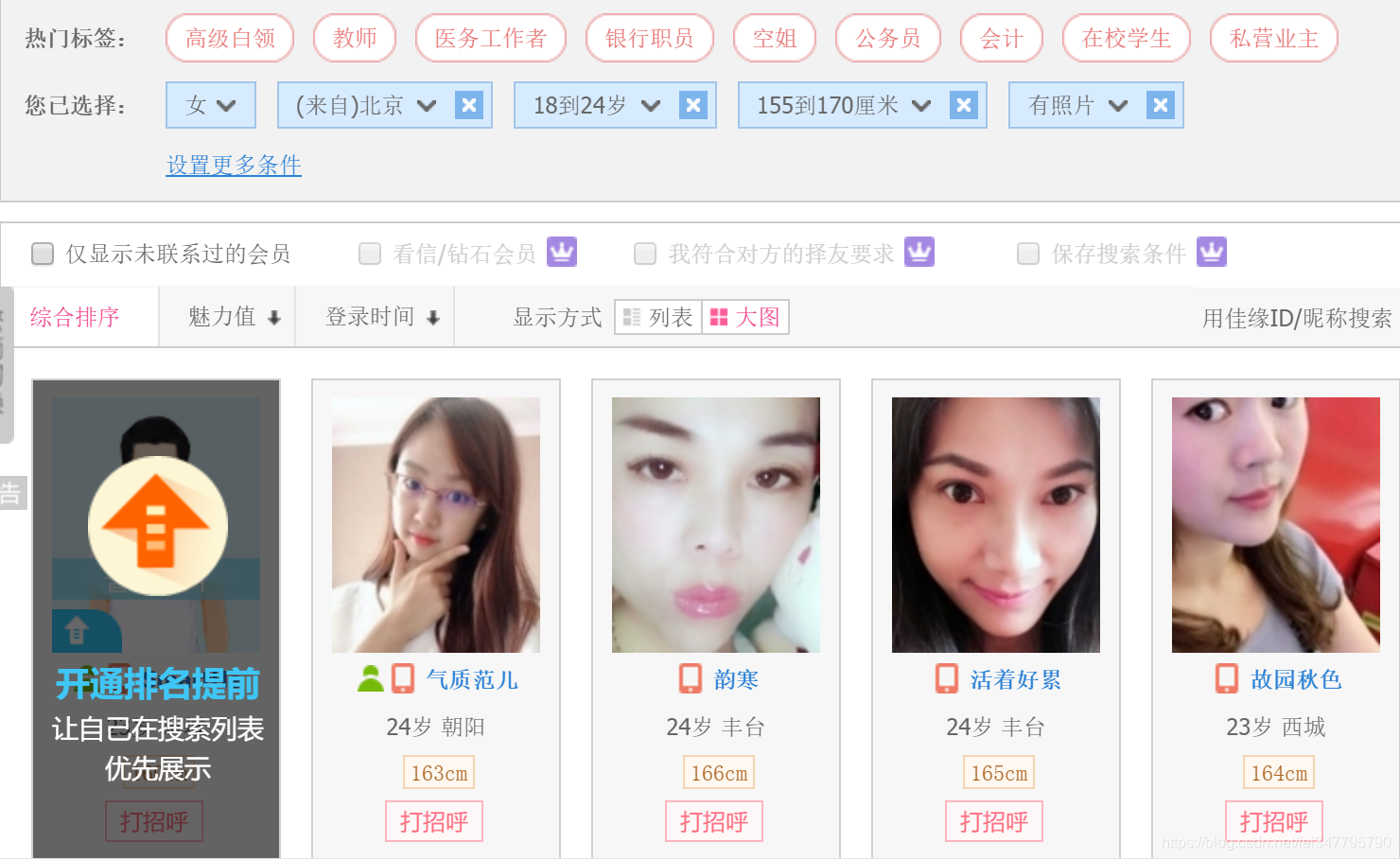
马上又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日。
翻着安静到死寂的聊天列表,我忽然惊醒,不行,我们不能这样下去,光羡慕别人有什么用,我们要行动起来,去找自己的幸福!!
筛选条件,嗯…性别女,年龄…18到24岁,身高嘛,无所谓啦,就按默认155-170吧,地区…嗯北京好,北京近一点,照片?那肯定要啊,必须的!!!
小姐姐们我来了~
基本环境配置
- 环境:python3.6
- 相关模块:
import requests
import json
import time
爬虫过程
爬虫部分还是我们之前的四步:分析目标网页,获取网页内容,提取关键信息,输出保存
1. 首先分析目标网页
按F12召唤开发者工具页面,切换到Network选项,然后在翻页的时候抓包,成功截获请求URL。
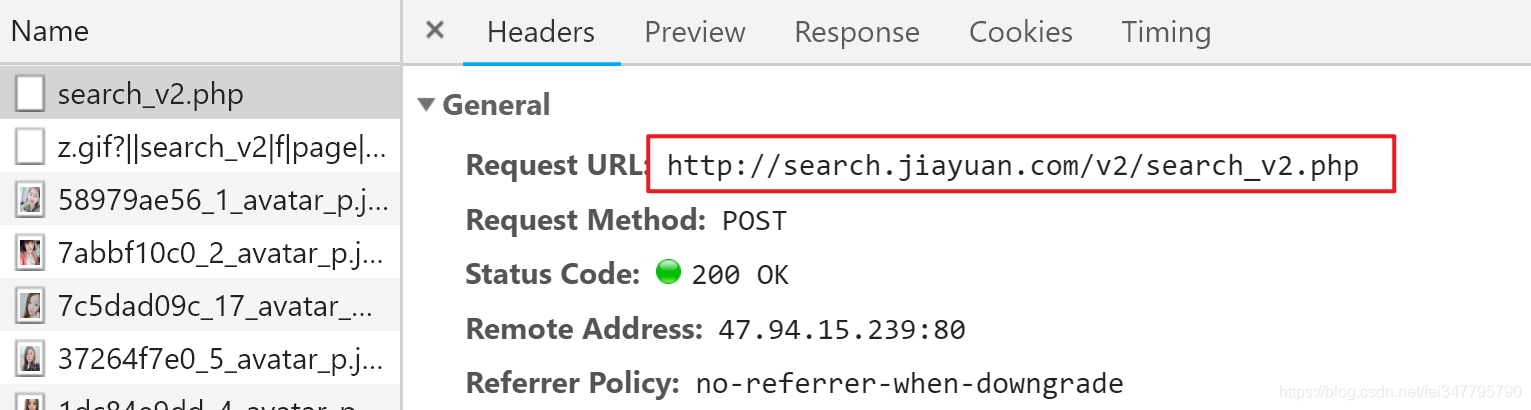
不过,这个请求是 POST 方法的,和我们之前见到的 GET 方法的请求有点不同。哪里不同呢…它有点短?
没错,它太短了,少了很多信息,比如我们搜索的条件,甚至连页码的信息都没有,光靠它怎么可能正确的找到小姐姐嘛!
别急,往下翻,其实, POST 方法请求的参数是放在 Form Data 的地方(怎么可能没有嘛是吧)
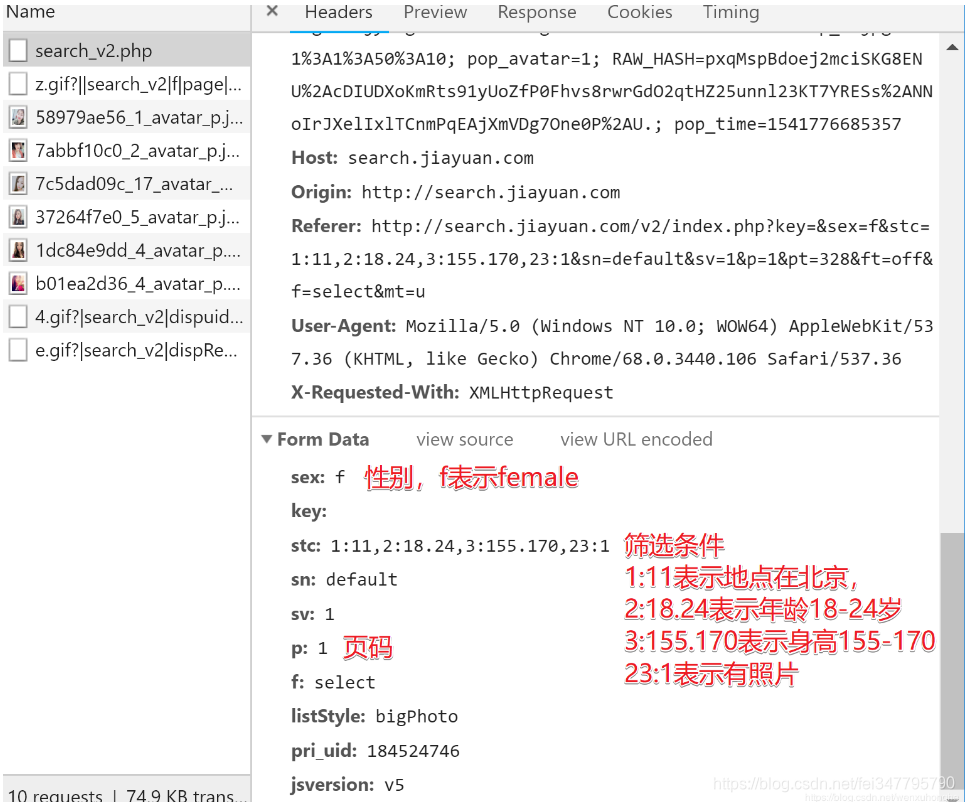
更多筛选条件及其对应的编号

完整代码:
import requests
import json
import time
def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Cookie': 'guider_quick_search=on; SESSION_HASH=f09e081981a0b33c26d705c2f3f82e8f495a7b56; PHPSESSID=e29e59d3eacad9c6d809b9536181b5b4; is_searchv2=1; save_jy_login_name=18511431317; _gscu_1380850711=416803627ubhq917; stadate1=183524746; myloc=11%7C1101; myage=23; mysex=m; myuid=183524746; myincome=30; COMMON_HASH=4eb61151a289c408a92ea8f4c6fabea6; sl_jumper=%26cou%3D17%26omsg%3D0%26dia%3D0%26lst%3D2018-11-07; last_login_time=1541680402; upt=4mGnV9e6yqDoj%2AYFb0HCpSHd%2AYI3QGoganAnz59E44s4XkzQZ%2AWDMsf5rroYqRjaqWTemZZim0CfY82DFak-; user_attr=000000; main_search:184524746=%7C%7C%7C00; user_access=1; PROFILE=184524746%3ASmartHe%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10; pop_avatar=1; RAW_HASH=n%2AazUTWUS0GYo8ZctR5CKRgVKDnhyNymEBbT2OXyl07tRdZ9PAsEOtWx3s8I5YIF5MWb0z30oe-qBeUo6svsjhlzdf-n8coBNKnSzhxLugttBIs.; pop_time=1541680493356'
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'unicode_escape'
print(r.url)
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
s = json.loads(html)
usrinfo = []
for key in s['userInfo']:
blist = []
uid = key['uid']
nickname = key['nickname']
sex = key['sex']
age = key['age']
work_location = key['work_location']
height = key['height']
education = key['education']
matchCondition = key['matchCondition']
marriage = key['marriage']
income = key['income']
shortnote = key['shortnote']
image = key['image']
blist.append(uid)
blist.append(nickname)
blist.append(sex)
blist.append(age)
blist.append(work_location)
blist.append(height)
blist.append(education)
blist.append(matchCondition)
blist.append(marriage)
blist.append(income)
blist.append(shortnote)
blist.append(image)
usrinfo.append(blist)
print(nickname,age,work_location)
writePage(usrinfo)
print('---' * 20)
def writePage(urating):
'''
Function : To write the content of html into a local file
html : The response content
filename : the local filename to be used stored the response
'''
import pandas as pd
dataframe = pd.DataFrame(urating)
dataframe.to_csv('Jiayuan_UserInfo.csv', mode='a', index=False, sep=',', header=False)
if __name__ == '__main__':
for page in range(1, 5916):
url = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=%s&f=select' % str(page)
html = fetchURL(url)
parserHtml(html)
# 为了降低被封ip的风险,每爬100页便歇5秒。
if page%100==99:
time.sleep(5)

由于决策树属于监督学习,需要一个给定的标签,因此需要自己根据用户的外貌、年龄、学历等多个维度的判断给出一个标签,最后生成的决策树在一定程度上就可以反映自己的择偶标准。针对女性的标签很简单粗暴,只有满意和不满意两种,有兴趣的同学可以按照真实的情况设置更多的标签,例如优秀、一般、备胎、不合格等等。因为外貌是选择对象过程中一个必不可少的要素,把相貌量化至关重要,因为没有相关的工具根据头像进行评分,只能个人主观进行量化,采用了当下非常流行的十分制。
为了增加打标签的效率,专门写了一个桌面窗口

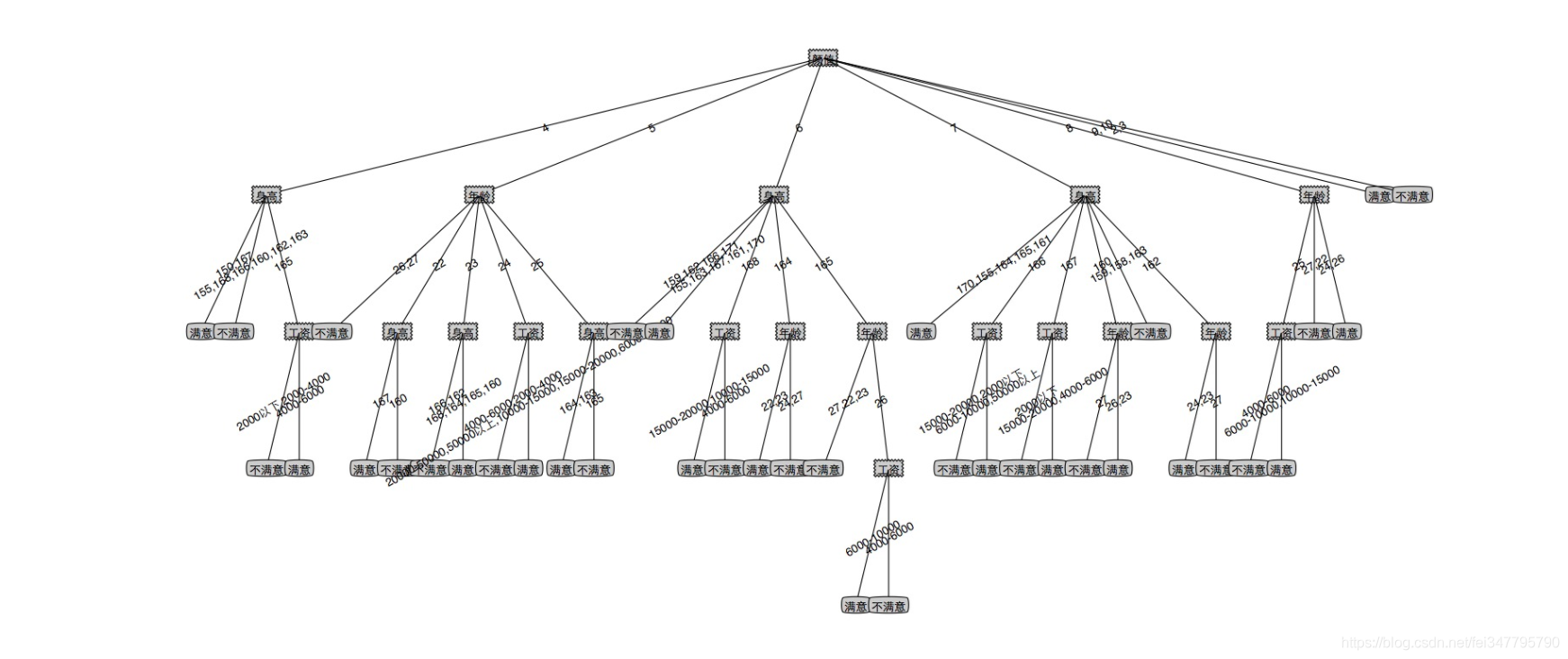
因为线很挤,调了很久只能拿到这个效果了。到这儿已经很清晰明了的阐明了主题,我就是一个外貌党,颜值高的pass,颜值低的忽略,不高不低的考虑的相当纠结。有兴趣的同学可以自己试一试。