今天比较闲,简单的做了一个命令行下的聊天机器人,接口还是之前做android聊天机器人的时候申请的key,没想到现在还没有失效。╭(╯^╰)╮
先放个下载地址吧:

https://github.com/guoruibiao/chatter/raw/master/panda.rar
原理
接口
原理就是使用图灵机器人接口。网址如下:http://www.tuling123.com/
官网简易使用post的方式进行网络请求,所以最好也是按照官网的来。
发送的格式是一致的,但是返回的数据类型却不是一致的。这一点可以通过返回的JSON串中的code属性进行区分。
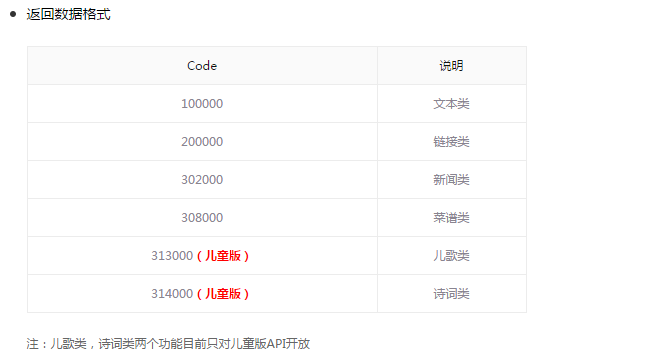
详细的信息,可以参照API中的讲解,异常的详细,(^__^) 嘻嘻……
http://www.tuling123.com/help/h_cent_webapi.jhtml?nav=doc
语音
这里和之前Android上写的不同,那就是添加了语音模块,也就是说,电脑会通过扬声器来和您对话。
依赖: pyttsx
详细的使用可以参考一下博主之前写过的这篇文章:
http://blog.csdn.net/Marksinoberg/article/details/52137547?locationNum=1&fps=1
代码实现
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# __author__ = '郭 璞'
# __date__ = '2016/10/31'
# __Desc__ = 图灵机器人测试
import requests
import urllib, urllib2
import json
import jieba
import pyttsx
from random import randint
# 一次性初始化语音引擎,减少资源的打开关闭开销
engine = pyttsx.init()
# 对语句进行分词,分词列表中将包含查询所需的关键字,这里暂且用不到了(接口已经完成了此项任务)
def parseText(text):
words = []
words = jieba.cut(text, cut_all=True)
return list(set(words))
# 根据post方式获取到返回信息
def getResult(url, payload):
res = requests.post(url=url, data=payload)
return res
def getData(url, payload):
payload = urllib.urlencode(payload)
req = urllib2.Request(url=url, data=payload)
return urllib2.urlopen(req).read()
# 初始化语音引擎,让电脑读出来
def say(text):
rate = engine.getProperty('rate')
# 控制一下语速
engine.setProperty('rate', rate - 64 + randint(10, 36))
engine.say(text)
engine.runAndWait()
# 根据返回的code来判断属于哪一类的json数据串,方便接下来的拆解,共有
# 10 0000 文本类
# 20 0000 链接类
# 30 2000 新闻类
# 30 8000 菜谱类
# 31 3000 儿歌类(仅针对于儿童版)
# 31 4000 诗词类(仅针对于儿童版)
def switch(result):
code = result['code']
if code == 100000:
text = result['text']
print text
say(text)
elif code == 200000:
text = result['text']
url = result['url']
print text, url
say(text + '. 不妨,点击后面的链接查看详情吧')
elif code == 302000:
text = result['text']
newslist = result['list']
# 循环读取每一个条目的新闻内容
for item in range(len(newslist)):
article = newslist[item]['article']
source = newslist[item]['source']
detailurl = newslist[item]['detailurl']
print article, source, detailurl
elif code == 308000:
text = result['text']
menu = result['list']
# 循环的打出每一条菜谱的详细信息
for item in menu:
name = item['name']
icon = item['icon']
info = item['info']
detailurl = item['detailurl']
print name, icon, info, detailurl
else:
print '我竟无言以对,╭(╯^╰)╮'
say('我表示不知道说什么好了')
# 根据关键字的不同,组装出不同的post数据,以便于获取不同的结果集
def main(url='http://www.tuling123.com/openapi/api', text='你好'):
payload = {
'key': '您申请的APPkey',
'info': text,
# userid 官网上说是针对每一个用户实现的不同的编号即可,这里随意指定不重复即可
'userid': '1357924680'
}
# 将返回的数据以json的方式打开,并读取Reponse的内容部分
# result = json.loads(getResult(url, payload).text)
result = json.loads(getData(url, payload))
# 根据code的不同,跳转到不同的分支,实现条件语句
switch(result)
if __name__ == '__main__':
print '嗨,我是专门为你打造的一个聊天机器人,随便和我聊些什么吧,我可以陪您聊天,给您讲笑话,查新闻,查航班,查车票,还能为您找菜谱呢(*^__^*) 嘻嘻……\n\n\n'.encode('gbk')
username = raw_input('输入姓名后即可开始聊天,按Ctrl+C退出: '.encode('gbk'))
question = raw_input('%s: '.encode('gbk') % username)
while True:
question = question.decode('gbk')
main(text=question)
print '---------------------------------------------------'
question = raw_input('%s: '.encode('gbk') % username)
print '( ^_^ )/~~拜拜'.encode('utf-8')
如上所示,你可能会对import部分感到好奇,明显requests,jieba模块都没有用到,为什么还要引入呢?
答案就是一开始博主想利用pyinstaller将其打包成一个exe文件的,奈何种种原因没能成功。
一开始以为是requests这种第三方模块的问题,就用urllib,urllib2重写了一下,发现还是失败了。
究其根本是pyinstaller工具未能成功的将pyttsx打包, 因此而失败。
为了给自己一个警醒(纪念),就没有删掉这些没用的代码。
效果
由于图片不能显示声音,所以演示的效果不太好。
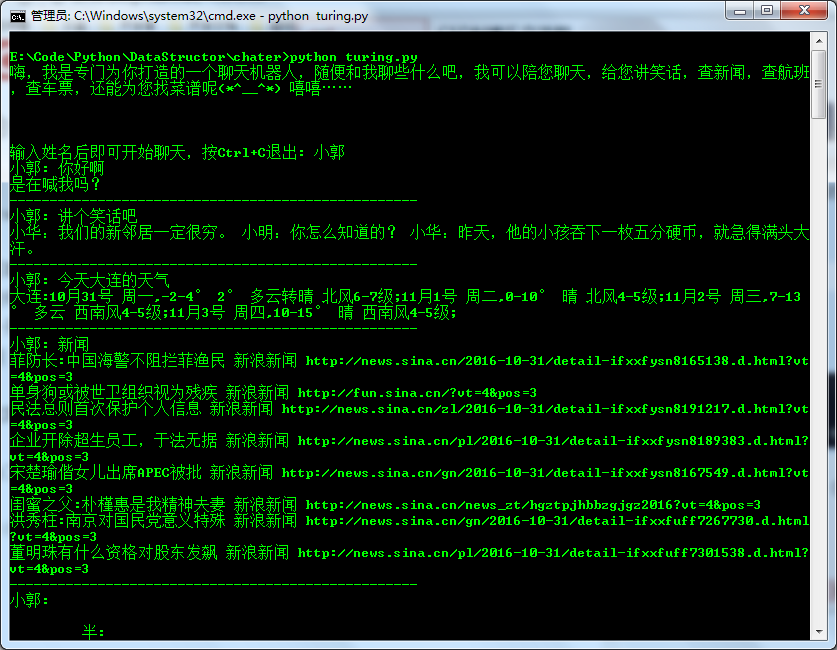
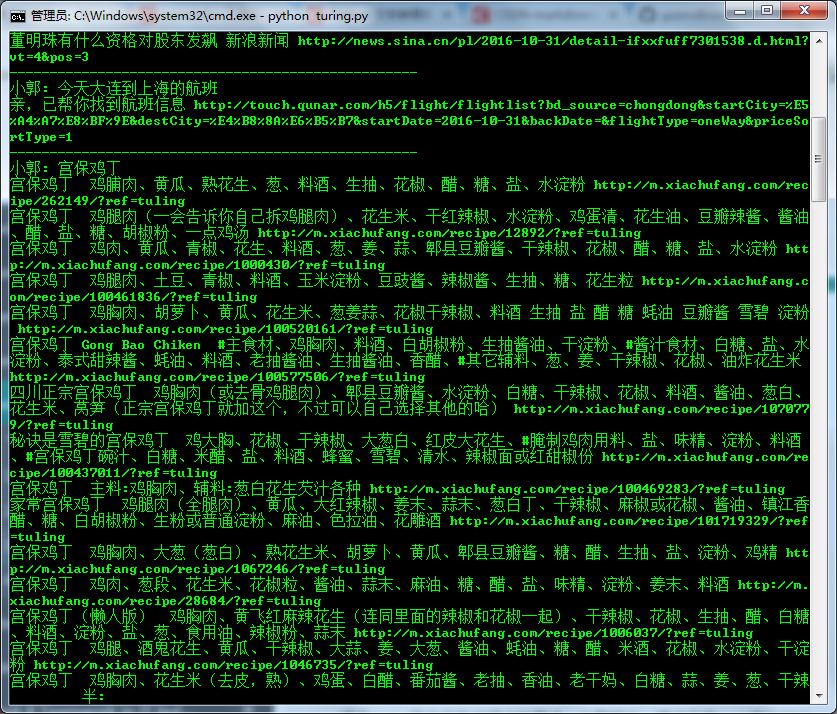
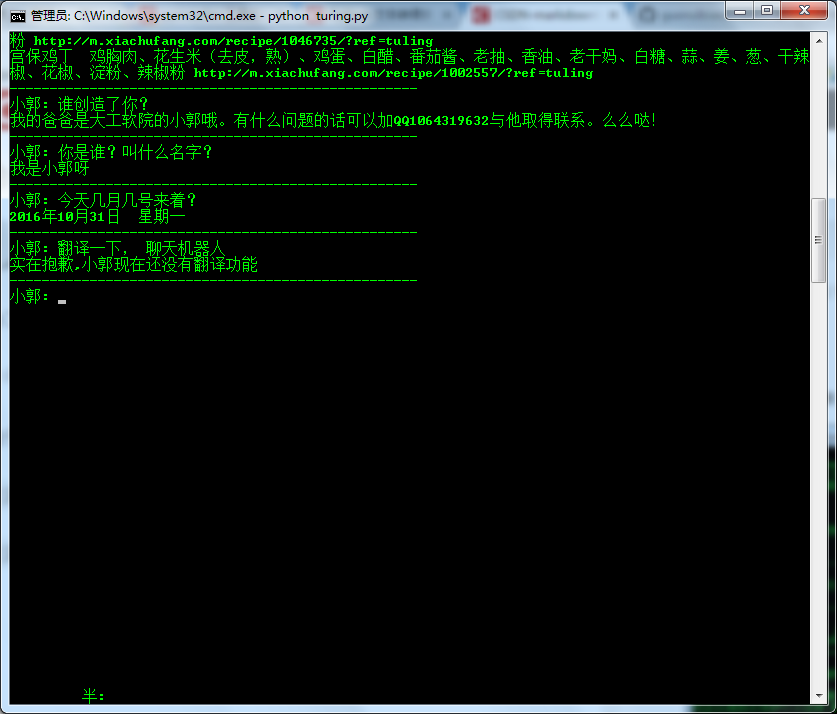
总结
总的来说,这次没有什么难点,还是对基础模块的使用,图灵机器人这个平台确实是一个比较好的锻炼平台。比较适合用来练手和巩固基础的知识技能。