前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 刘铨@CCIS Lab
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
一、分析URL
1、分析豆瓣影评URL
首先在豆瓣中,找到我们想要爬取的电影《冰雪奇缘2》

2、查看影片评论

二、爬取评论
分析网页源码
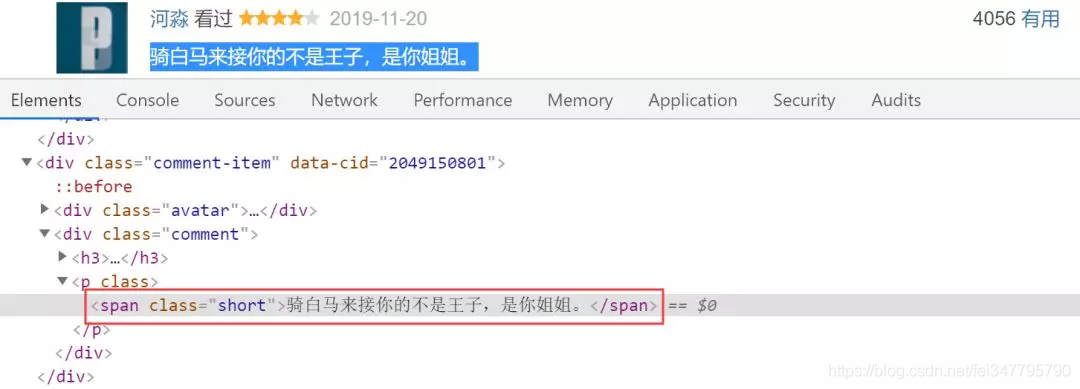
分析源码,可以看到评论在这个标签中,即代码为:
import urllib.request
from bs4 import BeautifulSoup
def getHtml(url):
"""获取url页面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
def getComment(url):
"""解析HTML页面"""
html = getHtml(url)
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
onePageComments.append(comment.getText()+'\n')
return onePageComments
if __name__ == '__main__':
f = open('冰雪奇缘2.txt', 'w', encoding='utf-8')
for page in range(10): # 豆瓣爬取多页评论需要验证。
url = 'https://movie.douban.com/subject/25887288/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
print('第%s页的评论:' % (page+1))
print(url + '\n')
for i in getComment(url):
f.write(i)
print(i)
print('\n')
这里要注意的是,未登录用户只能查看前十页的评论,爬取更多评论需要先模拟登录。
三、进行词云展示
数据抓取下来之后,我们就来使用词云分析一下这部电影:
1、使用结巴分词
因为我们下载的影评是一段一段的文字,而我们做的词云是统计单词出现的次数,所以需要先分词。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
text = open("冰雪奇缘2.txt","rb").read()
#结巴分词
wordlist = jieba.cut(text,cut_all=False)
wl = " ".join(wordlist)
2、使用词云分析
#设置词云
wc = WordCloud(background_color = "white", #设置背景颜色
mask = imread('black_mask.png'), #设置背景图片
max_words = 2000, #设置最大显示的字数
stopwords = ["的", "这种", "这样", "还是","就是", "这个", "没有" , "一个" , "什么", "电影", "一部","第一部", "第二部"], #设置停用词
font_path = "C:\Windows\Fonts\simkai.ttf", # 设置为楷体 常规
#设置中文字体,使得词云可以显示(词云默认字体是“DroidSansMono.ttf字体库”,不支持中文)
max_font_size = 60, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl)#生成词云
wc.to_file('result.png')
#展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()

最终结果:

.