接口分析
爬数据需要先思考从哪里爬?经过一番搜索和考虑,我发现天天基金网的数据既比较全,又十分容易爬取,所以就从它入手了。
首先,随便点开一支基金,我们可以看到域名就是该基金的代码,十分方便,其次下面有生成的净值图。
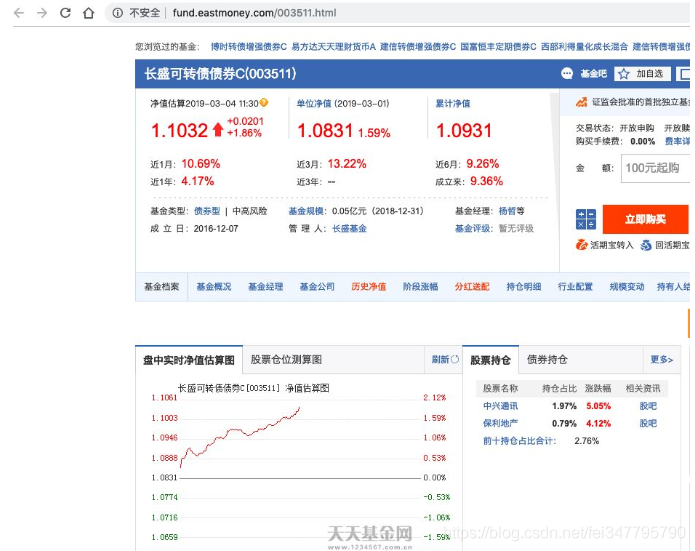
基金详情
打开chrome的开发者调试,选择Network,然后刷新一下,很快我们就能发现我们想要的东西了。可以看到,这是基金代码加当前时间的一个接口
请求的url:
http://fund.eastmoney.com/pingzhongdata/003511.js?v=20190304115823
也就是说我们可以简单的通过
http://fund.eastmoney.com/pingzhongdata/
基金代码.js?v=当前时间这样一个接口就能获取到相应的数据了。
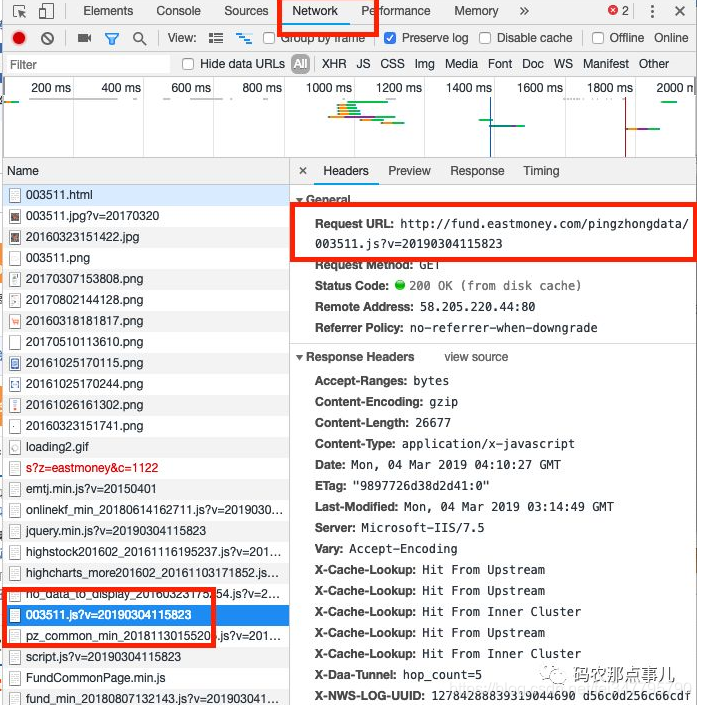
打开开发者模式
现在我们来看看这个文件的具体内容是什么?
显然,这里面的东西就是我们想要的,Data_netWorthTrend里面的"y"就包含了每一天的净值
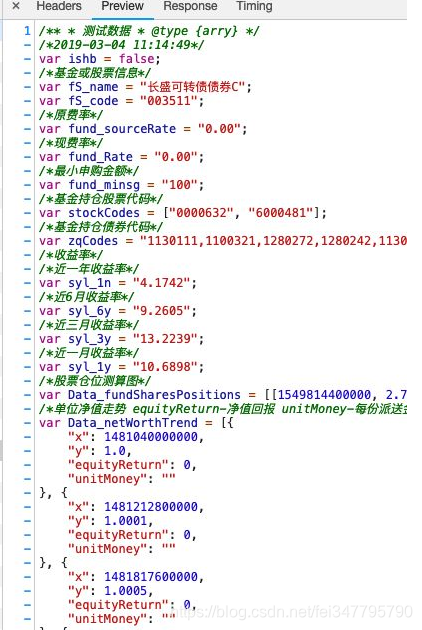
获取数据
现在我们的接口已经十分明确了,就是http://fund.eastmoney.com/pingzhongdata/基金代码.js?v=当前时间
通过基金代码和当前时间我们就能够获取到相应的数据,接下来就是需要将我们想要的数据从获取的文件中提取出来了,也就是我们说的数据清洗的过程。
这个网站提供的数据不是常见的json格式,因此提取会有点麻烦,比如通过字符串查找等,但是由于这个是js文件,因此,我找到了更合适的方法——利用了PyExecJs模块就能很方便地编译解析js代码啦。
现在直接上代码。
首先终端里,pip install PyExecJs安装上该模块。然后引入这些模块
import requests
import time
import execjs
接口构造
构造一个url
def getUrl(fscode):
head = 'http://fund.eastmoney.com/pingzhongdata/'
tail = '.js?v='+ time.strftime("%Y%m%d%H%M%S",time.localtime())
return head+fscode+tail
获取净值
def getWorth(fscode):
#用requests获取到对应的文件
content = requests.get(getUrl(fscode))
#使用execjs获取到相应的数据
jsContent = execjs.compile(content.text)
name = jsContent.eval('fS_name')
code = jsContent.eval('fS_code')
#单位净值走势
netWorthTrend = jsContent.eval('Data_netWorthTrend')
#累计净值走势
ACWorthTrend = jsContent.eval('Data_ACWorthTrend')
netWorth = []
ACWorth = []
#提取出里面的净值
for dayWorth in netWorthTrend[::-1]:
netWorth.append(dayWorth['y'])
for dayACWorth in ACWorthTrend[::-1]:
ACWorth.append(dayACWorth[1])
print(name,code)
return netWorth, ACWorth
查看数据
这样我们就可以通过基金代码来查到对应的数据啦
netWorth, ACWorth = getWorth('003511')
print(netWorth)
可以看到,最近一天的净值是1.0831,从网站上我们也可以验证一下这个数据是否正确
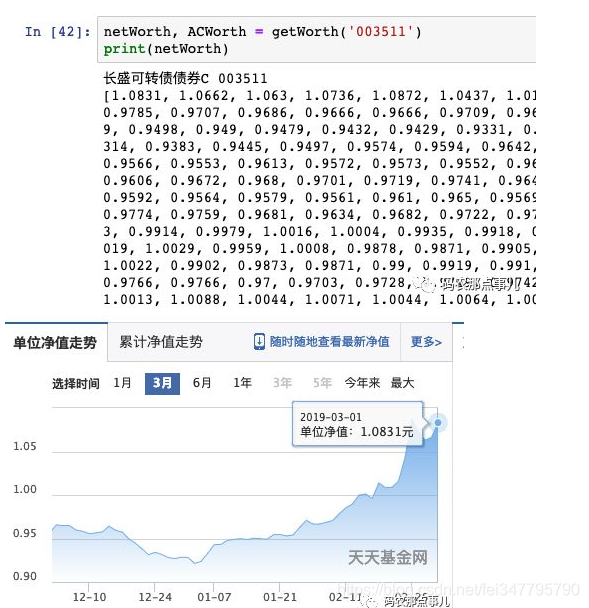
当然,我们也可以自己画一个走势图来验证一下
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.plot(netWorth[:60][::-1])
plt.show()
可以看到,和天天基金网画的是一样的。
不过这个方法获取的数据有个小问题,就是无法获得对应的确切日期。我们如果分析最近几个周、几个月的数据,其实也可以不需要了解具体某一天的数据,取最近20天、40天等方式即可。当然,也可以从当天开始逆推回去,给每个净值标上日期,不过这个需要忽略节假日,处理起来比较麻烦且必要性不大,我就没有做这个处理。
获取所有基金数据
这里我通过同样的方式,找到了所有基金列表的接口。
通过’http://fund.eastmoney.com/js/fundcode_search.js’便可以直接获取到所有的基金代码,再通过基金代码可以遍历爬取所有基金的数据,具体就不再演示了,下面提供一个可用的代码供参考。
我将下载的数据存成了csv,方便excel打开或用代码读取。当然,总共有近8000支基金,爬取需要大量的时间,因此我将它放在了服务器后台爬取,如果你想提高效率,可以改写成多进程同步爬取,时间将会大大缩短。
import requests
import time
import execjs
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
def getUrl(fscode):
head = 'http://fund.eastmoney.com/pingzhongdata/'
tail = '.js?v='+ time.strftime("%Y%m%d%H%M%S",time.localtime())
return head+fscode+tail
# 根据基金代码获取净值
def getWorth(fscode):
content = requests.get(getUrl(fscode))
jsContent = execjs.compile(content.text)
name = jsContent.eval('fS_name')
code = jsContent.eval('fS_code')
#单位净值走势
netWorthTrend = jsContent.eval('Data_netWorthTrend')
#累计净值走势
ACWorthTrend = jsContent.eval('Data_ACWorthTrend')
netWorth = []
ACWorth = []
for dayWorth in netWorthTrend[::-1]:
netWorth.append(dayWorth['y'])
for dayACWorth in ACWorthTrend[::-1]:
ACWorth.append(dayACWorth[1])
print(name,code)
return netWorth, ACWorth
def getAllCode():
url = 'http://fund.eastmoney.com/js/fundcode_search.js'
content = requests.get(url)
jsContent = execjs.compile(content.text)
rawData = jsContent.eval('r')
allCode = []
for code in rawData:
allCode.append(code[0])
return allCode
allCode = getAllCode()
netWorthFile = open('./netWorth.csv','w')
ACWorthFile = open('./ACWorth.csv','w')
for code in allCode:
try:
netWorth, ACWorth = getWorth(code)
except:
continue
if len(netWorth)<=0 or len(ACWorth)<0:
print(code+"'s' data is empty.")
continue
netWorthFile.write("\'"+code+"\',")
netWorthFile.write(",".join(list(map(str, netWorth))))
netWorthFile.write("\n")
ACWorthFile.write("\'"+code+"\',")
ACWorthFile.write(",".join(list(map(str, ACWorth))))
ACWorthFile.write("\n")
print("write "+code+"'s data success.")
netWorthFile.close()
ACWorthFile.close()