基础架构和流程
简单的爬虫架构由以下几部分构成:
- 爬虫调度器:总体协调其它几个模块的工作
- URL管理器:负责管理URL,维护已经爬取的URL集合和未爬取的URL集合
- 网页下载器:对未爬取的URL下载
- 网页解析器:解析已下载的html,并从中提取新的URL交给URL管理器,数据交给存储器处理
- 数据存储器:将html解析出来的数据进行存取
架构图如下: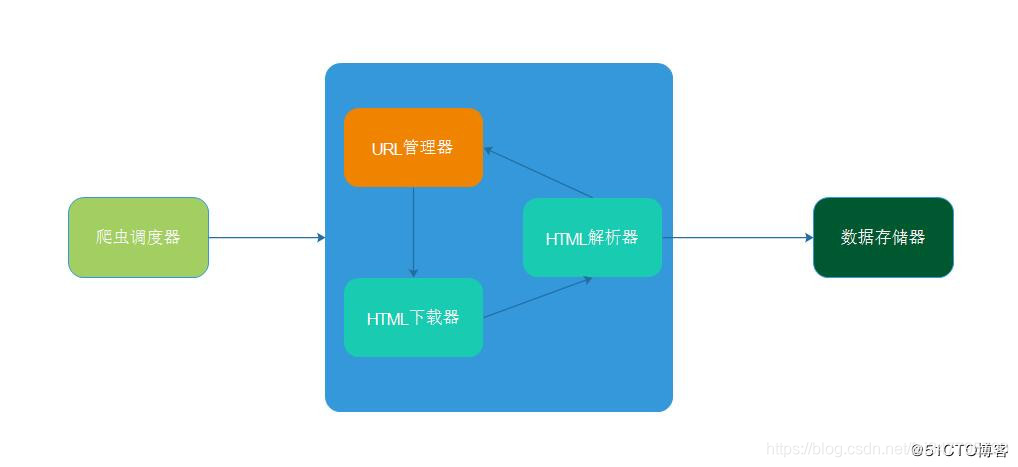
爬虫流程图如下: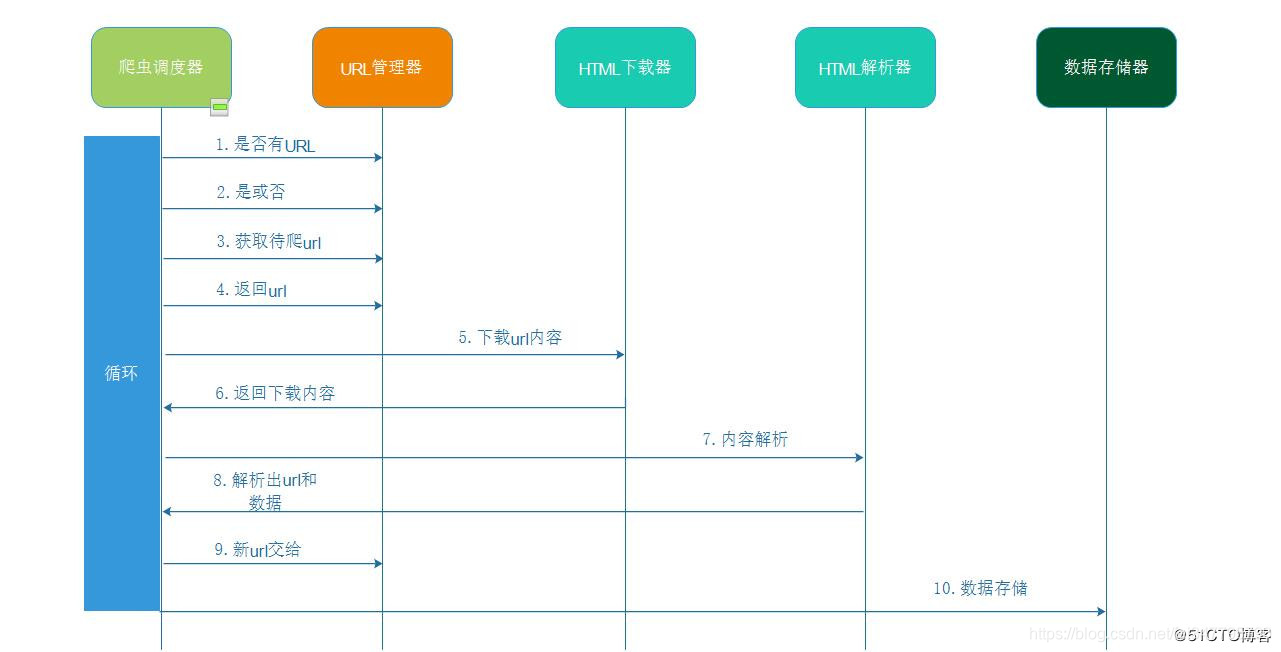
下面我们就分别按每个部分来拆分。
我们本次就拿百科搜索词条来演示,爬取百科内容标题和摘要信息,同时如果摘要中有链接,还会把连接的标题摘要下载下来。如下图: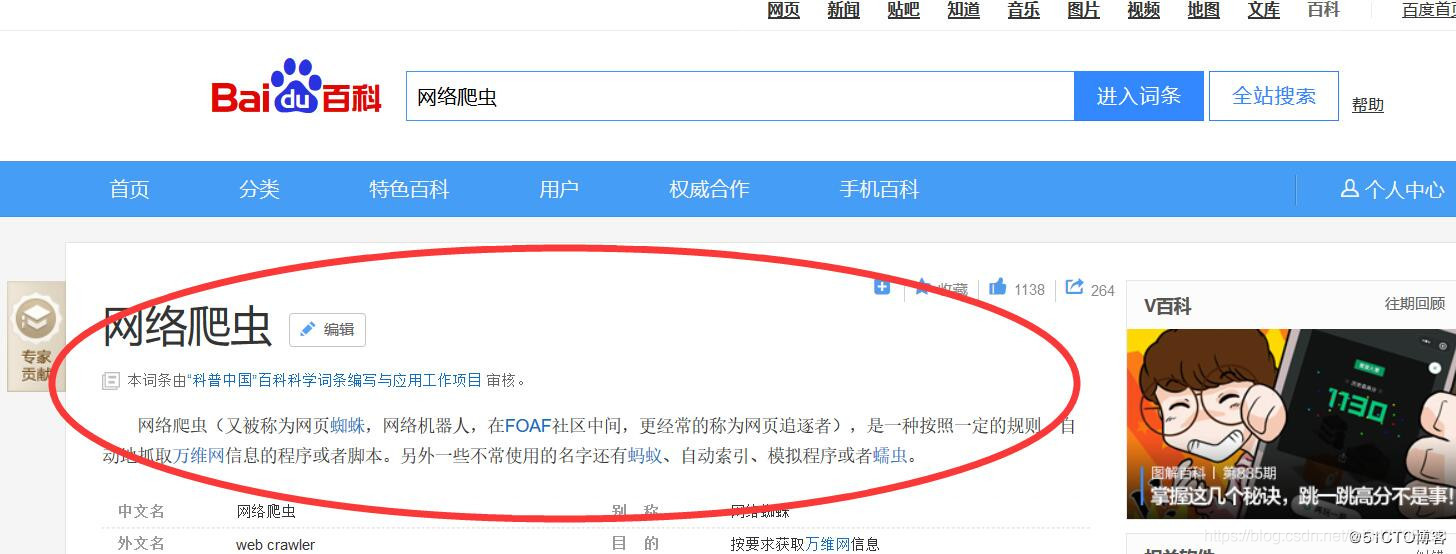
URL管理器
基本功能:
- 判断是否有待爬取的url
- 添加新的url到待爬取url集合中
- 获取未爬取的url
- 获取待爬取集合大小
- 获取已爬取集合大小
- 将爬取完成的url从待爬取url集合移动到已爬取url集合。
这里URL管理器还要用到set去重功能,防止程序进入死循环。大型互联网公司,由于缓存数据库的高性能,一般把url存储在缓存数据库中。小型公司,一般把url存储在内存中,如果想要永久存储,则存储到关系数据库中。
URL管理器代码
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
class UrlManager:
"""
URL管理器类
"""
def __init__(self):
"""
初始化未爬取集合new_urls和已爬取集合old_urls
"""
# python的set和其他语言类似, 是一个无序不重复元素集
self.new_urls = set()
self.old_urls = set()
def has_new_url(self):
"""
判断是否有未爬取的url
:return:
"""
return self.new_url_size() != 0
def get_new_url(self):
"""
获取未爬取的url
:return:
"""
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self, url):
"""
将新的url添加到未爬取的url集合中
:return:
"""
if url is None:
return
# 判断url是否在new_urls或old_urls中
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
"""
添加新的url到未爬取集合
:param urls: url集合
:return:
"""
if urls is None or len(urls) == 0:
return
# 循环将获取的url存入new_urls中
for url in urls:
self.add_new_url(url)
def new_url_size(self):
"""
获取未爬取集合大小
:return:
"""
return len(self.new_urls)
def old_url_size(self):
"""
获取已爬取集合大小
:return:
"""
return len(self.old_urls)
HTML下载器
HTML下载器就比较简单了,只是通过requests获取html内容即可(注意:要用到session,不然会报 TooManyRedirects 异常),具体看代码:
import requests
class HtmlDownload:
"""
HTML下载器类
"""
def download(self, url):
"""
下载html
:param url:根据url下载html内容
:return: 返回html
"""
# 创建session对象,这里一定要用session,不然会报TooManyRedirects异常
s = requests.session()
# 添加头部信息
s.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'
# 获取内容
resp = s.get(url)
# 要以content字节形式返回
return resp.content.decode()
HTML解析器
先来分析要爬取的网页:
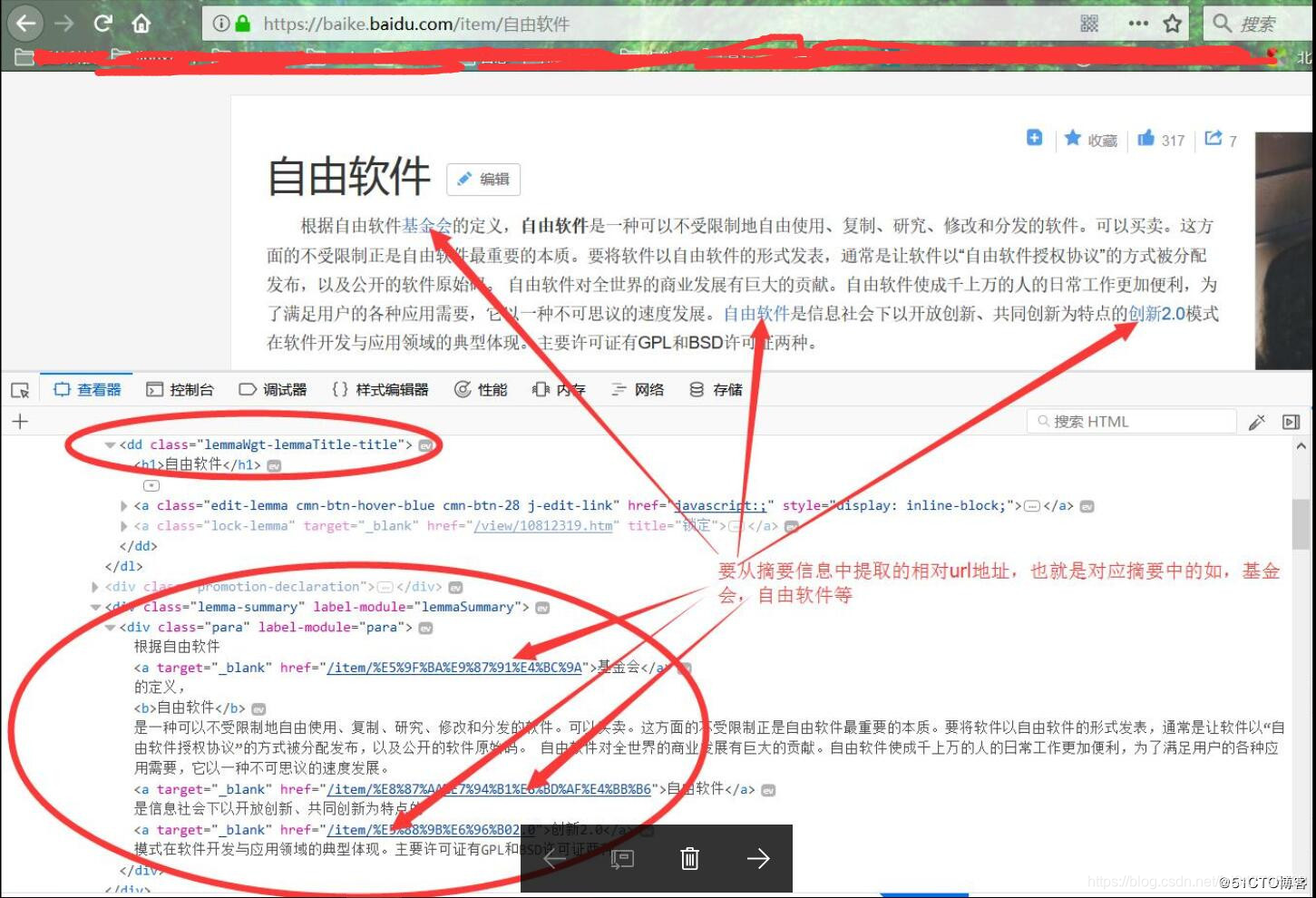
通过上面分析可以看到,我们需要的标题在
标签中,其中
标签中的a标签的herf是我们需要继续爬取的相对url通过上面分析可以看到,我们需要的标题在
标签中,其中
标签中的a标签的herf是我们需要继续爬取的相对url。
from bs4 import BeautifulSoup
class HtmlParse:
"""
HTML解析器类
"""
def __init__(self, baseurl='https://baike.baidu.com'):
"""
初始化基础url
:param baseurl:基础url
"""
self.baseurl = baseurl
def parse_data(self, page):
"""
获取网页数据
:param page:获取的html
:return:解析后要存储的数据
"""
# 创建实例
soup = BeautifulSoup(page, 'lxml')
# 获取标题
title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1').string
# 获取摘要
summary = soup.find('div', class_='para').text
# 完整的数据信息
data = title + summary
return data
def parse_url(self, page):
"""
获取网页url
:param page:获取的html
:return:解析后获取的新url
"""
# 创建实例
soup = BeautifulSoup(page, 'lxml')
# 所有的<div class="para" label-module="para">中a标签
anodes = soup.find('div', class_='para').find_all('a')
# new_url set集
new_urls = set()
# 循环获取相对路径(href),与baseurl拼成全url
for anode in anodes:
link = anode.get('href')
# 完整路径
fullurl = self.baseurl + link
# 添加到未爬取集合new_urls中
new_urls.add(fullurl)
return new_urls
数据存储器
解析出来的数据就直接追加保存到文件就可以了。
class DataStore:
"""
数据存储器类
"""
def store_data(self, data, name='baike.txt'):
"""
将获取的数据存储到文件中
:param data: 解析的数据
:param name: 本地文件名
:return:
"""
with open(name, 'a', encoding='utf-8') as fp:
fp.write('\r\n')
fp.write(data)
爬虫调度器
爬虫调度器主要负责以上几个模块的调度
from spider.Datastore import DataStore
from spider.Htmldownload import HtmlDownload
from spider.Htmlparse import HtmlParse
from spider.Urlmanager import UrlManager
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
class SpiderMain:
"""
爬虫调度器类
"""
def __init__(self):
"""
初始化各模块
"""
self.manager = UrlManager()
self.download = HtmlDownload()
self.parse = HtmlParse()
self.output = DataStore()
def spider(self, url):
"""
爬虫主程序
:param url:初始url
:return:
"""
# 添加初始url到未爬取的new_urls中
self.manager.add_new_url(url)
# 通过while循环获取是否还有新的url要爬取,爬取了5条就结束,防止死循环下去
while self.manager.has_new_url() and self.manager.old_url_size() < 5:
try:
# 获取url
new_url = self.manager.get_new_url()
# 获取html
html = self.download.download(new_url)
# 解析后的新url
new_urls = self.parse.parse_url(html)
# 解析后要存储的数据
data = self.parse.parse_data(html)
# 添加解析后的新url到new_urls集中
self.manager.add_new_urls(new_urls)
# 保存数据
self.output.store_data(data)
print('已经抓取%s 个链接' % self.manager.old_url_size())
except Exception as e:
print('failed')
print(e)
if __name__ == '__main__':
# 实例化爬虫调度器类
spidermain = SpiderMain()
# 输入初始url进行爬取
spidermain.spider('https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB')
运行结果(只爬取了5条):
已经抓取1 个链接
已经抓取2 个链接
已经抓取3 个链接
已经抓取4 个链接
已经抓取5 个链接
好,今天的爬虫基础框架,就到这里了。