前面我已经介绍过解析CSS图片偏移反爬和字体反爬的数据,链接如下:
- Python提取CSS图片背景偏移定位的数据:https://blog.csdn.net/as604049322/article/details/118401598
- 2万字硬核剖析网页自定义字体解析:https://blog.csdn.net/as604049322/article/details/119333427
- woff字体图元结构剖析,自定义字体的制作与匹配和识别:https://blog.csdn.net/as604049322/article/details/119415686
最后一篇主要针对几年后,各大厂对字体反爬升级到轮廓图顺序随机,甚至基础字形随机的情况。近几年内还不需要理解的那么深,看不懂直接收藏即可,因为目前还没有任何一个网站的字体反爬搞的我想象的那么复杂~
SVG映射反爬示例
今天呢,我将分享一个相对非常简单的小例子,SVG文字图片偏移反爬数据提取。
这种反爬机制相对前两种来说,反爬强度也弱了很多,所以现在已经很少有网站还在继续采用这种反爬机制。
这里找到了一个SVG映射反爬的练习网站可以玩一下,网址是:http://www.porters.vip/confusion/food.html
分析一下DOM结构:

可以清楚的看到使用了CSS图片背景偏移来定位显示相应的数据,不过这张图片是svg格式的文字图片,
查看svg的内容如下:

说明这种svg实际存储仍然是纯文本的。
那么我们完全可以解析svg,根据background的偏移值定位匹配在svg实际的文本直接提取。
为了提取css数据简单一些,这里我直接使用selenium操作,首先打开目标网址:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'http://www.porters.vip/confusion/food.html#'
browser.get(url)
通过food.css的第4行开始的代码块可以知道,所有使用svg文字图片定位的标签的css样式是d[class^="vhk"]
那么我们通过任意一个具备该样式的元素取出svg的地址:
d_tag = browser.find_element_by_css_selector('d[class^="vhk"]')
background_image_url = d_tag.value_of_css_property("background-image")
svg_url = background_image_url[5:-2]
svg_url
'http://www.porters.vip/confusion/font/food.svg'
今天呢,为了解析方便介绍一个新库requests-html该框架作者就是 requests 的作者。
使用 pip install requests-html 即可安装,它相对于之前的requests 有哪些高级功能呢?可以参考官方手册查询地址:https://requests-html.kennethreitz.org/
对于我个人而言,目前最方便的是内置了CSS和xpath选择器,再也不需要为了解析数据额外导包了。
今天我们就直接使用这个库的xpath选择器来提取上述svg文件中的数据。观察上述svg内容的xml结构可以知道,每个text节点的x属性都一致,属性按顺序递增。
那么我使用requests-html库的下载和解析代码如下:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get(svg_url)
xs = []
ys = []
data = []
for text_tag in r.html.xpath(r"//text"):
if not xs:
xs.extend(map(int, text_tag.xpath(".//@x")[0].split()))
ys.append(int(text_tag.xpath(".//@y")[0]))
data.append(list(text_tag.xpath(".//text()")[0]))
print(xs)
print(ys)
print(data)
[14, 28, 42, 56, 70, 84, 98, 112, 126, 140, 154, 168, 182, 196, 210, 224, 238, 252, 266, 280, 294, 308, 322, 336, 350, 364, 378, 392, 406, 420, 434, 448, 462, 476, 490, 504, 518, 532, 546, 560, 574, 588, 602, 616, 630, 644, 658, 672, 686, 700, 714, 728, 742, 756, 770, 784, 798, 812, 826, 840, 854, 868, 882, 896, 910, 924, 938, 952, 966, 980, 994, 1008, 1022, 1036, 1050, 1064, 1078, 1092, 1106, 1120, 1134, 1148, 1162, 1176, 1190, 1204, 1218, 1232, 1246, 1260, 1274, 1288, 1302, 1316, 1330, 1344, 1358, 1372, 1386, 1400, 1414, 1428, 1442, 1456, 1470, 1484, 1498, 1512, 1526, 1540, 1554, 1568, 1582, 1596, 1610, 1624, 1638, 1652, 1666, 1680, 1694, 1708, 1722, 1736, 1750, 1764, 1778, 1792, 1806, 1820, 1834, 1848, 1862, 1876, 1890, 1904, 1918, 1932, 1946, 1960, 1974, 1988, 2002, 2016, 2030, 2044, 2058, 2072, 2086, 2100]
[38, 83, 120, 164]
[['1', '5', '4', '6', '6', '9', '1', '3', '6', '4', '9', '7', '9', '7', '5', '1', '6', '7', '4', '7', '9', '8', '2', '5', '3', '8', '3', '9', '9', '6', '3', '1', '3', '9', '2', '5', '7', '2', '0', '5', '7', '3'], ['5', '6', '0', '8', '6', '2', '4', '6', '2', '8', '0', '5', '2', '0', '4', '7', '5', '5', '4', '3', '7', '5', '7', '1', '1', '2', '1', '4', '3', '7', '4', '5', '8', '5', '2', '4', '9', '8', '5', '0', '1', '7'], ['6', '7', '1', '2', '6', '0', '7', '8', '1', '1', '0', '4', '0', '9', '6', '6', '6', '3', '0', '0', '0', '8', '9', '2', '3', '2', '8', '4', '4', '0', '4', '8', '9', '2', '3', '9', '1', '8', '5', '9', '2', '3'], ['6', '8', '4', '4', '3', '1', '0', '8', '1', '1', '3', '9', '5', '0', '2', '7', '9', '6', '8', '0', '7', '3', '8', '2']]
可以看到这样就已经成功的提取出了需要的数据。
以下我们首先以电话号码为例演示获取偏移值:
import re
d_tags = browser.find_elements_by_css_selector('.more d[class^="vhk"]')
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("\d+", position))
print(position, x, y)
-8px -15px 8 15
-274px -141px 274 141
-274px -141px 274 141
-176px -141px 176 141
-7px -15px 7 15
-288px -141px 288 141
-288px -141px 288 141
-7px -15px 7 15
这样就解析出了每个数字位置对应的svg图片偏移数值。
如果理解这些数呢?我将第一个数字人工先改成-8px -15px,截图如下:
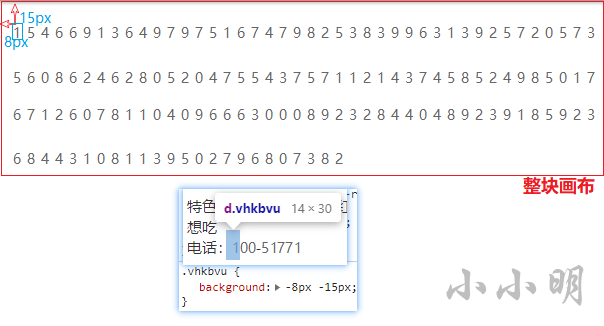
红色部分就是整块图片画布,-8px表示向左偏移8像素,-15px表示向上偏移15像素,这样左上角这部分就会被裁剪掉,然后只获取指定长度和宽度范围的图片,就得到图中蓝框的部分显示在界面上。
那么如何匹配获取到我们需要的数据呢?
这时就可以通过2分查找获取插入点,例如对于右上角1那个数字,可以通过下面的方式获取:
from bisect import bisect
data[bisect(ys, 15)][bisect(xs, 8)]
'1'
刷新页面后,重新批量测试一下:
import re
d_tags = browser.find_elements_by_css_selector('.more d[class^="vhk"]')
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("\d+", position))
print(x, y, data[bisect(ys, y)][bisect(xs, x)])
从结果看每个节点都精准的匹配上对应的文本数字:
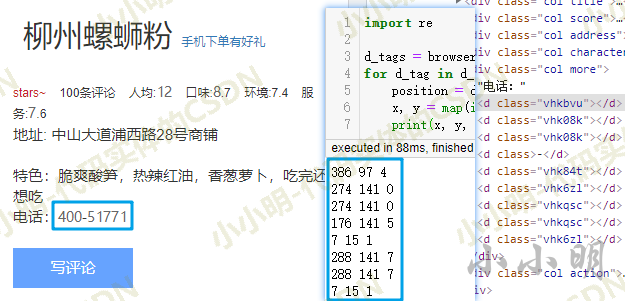
此时考虑将以上svg节点都替换成对应的文本后,就可以直接整体提取文本数据(调用JavaScript脚本进行节点替换):
import re
def parseAndReplaceSvgNode(d_tags):
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("\d+", position))
num = data[bisect(ys, y)][bisect(xs, x)]
# 替换节点为普通文本
browser.execute_script(f"""
var element = arguments[0];
element.parentNode.replaceChild(document.createTextNode("{num}"), element);
""", d_tag)
d_tags = browser.find_elements_by_css_selector('.more d[class^="vhk"]')
parseAndReplaceSvgNode(d_tags)
phone = browser.find_element_by_css_selector('.more').text
phone
'电话:400-51771'
执行后,对应的svg节点都转换成对应的文本节点:
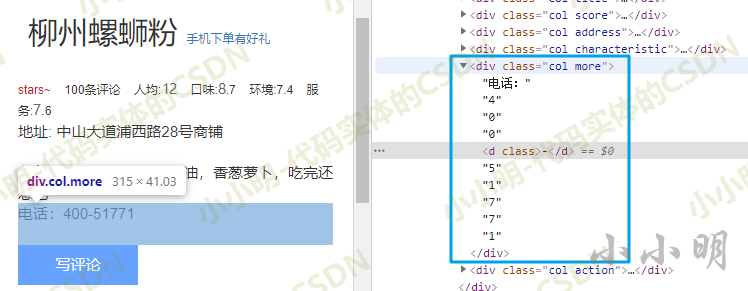
这样我们就可以很方便的解析所有需要的数据了。
基于此,相关基础知识我已经解析完全,下面公布完整处理代码:
import re
from requests_html import HTMLSession
from selenium import webdriver
from bisect import bisect
def parseAndReplaceSvgNode(d_tags):
for d_tag in d_tags:
position = d_tag.value_of_css_property("background-position")
x, y = map(int, re.findall("\d+", position))
num = data[bisect(ys, y)][bisect(xs, x)]
# 替换节点为普通文本
browser.execute_script(f"""
var element = arguments[0];
element.parentNode.replaceChild(document.createTextNode("{num}"), element);
""", d_tag)
browser = webdriver.Chrome()
url = 'http://www.porters.vip/confusion/food.html#'
browser.get(url)
d_tag = browser.find_element_by_css_selector('d[class^="vhk"]')
background_image_url = d_tag.value_of_css_property("background-image")
svg_url = background_image_url[5:-2]
session = HTMLSession()
html_session = session.get(svg_url)
xs = []
ys = []
data = []
for text_tag in html_session.html.xpath(r"//text"):
if not xs:
xs.extend(map(int, text_tag.xpath(".//@x")[0].split()))
ys.append(int(text_tag.xpath(".//@y")[0]))
data.append(list(text_tag.xpath(".//text()")[0]))
# 一次性替换掉整个DOM中所有的svg节点为对应的文本
parseAndReplaceSvgNode(
browser.find_elements_by_css_selector('d[class^="vhk"]'))
# 删除a标签
element = browser.find_element_by_css_selector('.title a')
browser.execute_script("""
var element = arguments[0];
element.parentNode.removeChild(element);
""", element)
# 获取标题
title = browser.find_element_by_class_name("title").text
# 获取评论
comment = browser.find_element_by_class_name("comments").text
# 人均
avgPrice = browser.find_element_by_class_name('avgPriceTitle').text
# 口味、环境、服务
comment_score_tags = browser.find_elements_by_css_selector(
".comment_score .item")
taste = comment_score_tags[0].text
environment = comment_score_tags[1].text
service = comment_score_tags[2].text
# 地址
address = browser.find_element_by_css_selector('.address .address_detail').text
# 特色
characteristic = browser.find_element_by_css_selector(
'.characteristic .info-name').text
# 电话
phone = browser.find_element_by_class_name("more").text
print(title, comment, avgPrice, taste, environment,
service, address, characteristic, phone)
柳州螺蛳粉 100条评论 人均:12 口味:8.7 环境:7.4 服务:7.6 中山大道浦西路28号商铺 特色:脆爽酸笋,热辣红油,香葱萝卜,吃完还想吃 电话:400-51771
可以看到这样就完美准确的提取出了每一个文本。