概述:
Java中的异常机制是一个好东西。不过好东西也要正确地使用才行,不然就会让我们错误地认识它。在错误地认识状况下,就会错误地使用。这样就成了一个恶性地循环了。这不是我们愿意看到的。不要以为我们已经可以很好地使用异常了,下面就针对部分问题作一个讲解。这部分的问题中,有一些是来自《Effective Java》这本书中,有一部分是来自本人平时开发过程中遇到的。
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/50474230 -- Coding-Naga
1.是throw还是try-catch
这个是一个对刚接触编程开发的人来说,经常面临但又选择不好的问题。
由于我们开发的项目可不是像写Demo一样轻松,这里可能会有很多层次结构。我们要在具体哪一层的什么位置是使用try-catch这个异常呢,还是把异常throw到上一层呢?这里,我们首先要知道一件事,那就是try-catch和throw分别会发生什么情况呢?
try-catch: 捕获一个异常情况,并中止try块中的后续操作。且不会再向上抛出异常了。
throw: 当使用throw抛出一个异常时,当前的执行块(方法)会结束后续的执行。相当于一个return操作,并保证了上层在调用的时候可以捕获到这个异常,并做相应处理。
Demo示例如下:
- public class ExceptionClient {
- public static void main(String[] args) {
- ExceptionClient client = new ExceptionClient();
- client.showInfo();
- }
- private void showInfo() {
- try {
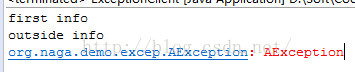
- System.out.println("first info");
- testException();
- System.out.println("second info");
- } catch (Exception e) {
- System.err.println(e);
- }
- System.out.println("outside info");
- }
- private void testException() throws AException {
- boolean f = true;
- if (f) {
- throw new AException("AException");
- }
- System.out.println("f is false.");
- }
- }
2.是使用受检的异常还是非受检的异常
首先我们要了解什么是受检异常和非受检异常,不过这里顾名思义,受检即接受检查。由于目前的IDE很是智能,当我们在使用受检异常而未try-catch这个异常时,IDE会给出错误提示。如下:

图-2 IDE对受检异常的检查
而非受检异常则不会被IDE识别。还有一点,因为前面说到IDE会检测到受检异常,所以,这里如果我们强行运行此代码,是通不过编译的,非受检异常则不会。
好了,说明了受检异常和非受检异常在使用过程中的区别。现在就来说说怎么创建这些不同的异常吧。
当我们要编写自定义的受检异常A.java时,A的class需要继承Exception,而非受检异常B.java则是继承RuntimeException。
由于受检异常会在使用的过程,强行限制开发人员去try-catch。而在try-catch此异常的时候,开发人员则可以对此异常进行修正并重新之前的操作(即恢复)。在RuntimeException中则没有这样的限制。所以,当我们试图告诉调用者,当前的异常是可以被修复,并允许重新去调用的时候,我们就使用受检的异常,当我们认为这是一个程序错误的时候,则需要使用非受检异常。
可能对在何时使用受检异常或非受检异常有了一些基本认识,然后你可能会问这样的一个问题:我们不是还有一个Error么,那么错误(Error)和异常有什么区别呢?下面就列举了这两者之间的区别
Exception:
1.可以是可被控制(checked) 或不可控制的(unchecked)。
2.表示一个由程序员导致的错误。
3.应该在应用程序级被处理。
Error:
1.总是不可控制的(unchecked)。
2.经常用来用于表示系统错误或低层资源的错误。
3.如何可能的话,应该在系统级被捕捉。
3.只针对不正确的条件才使用异常
关于这一点,首先我们应该了解的是Java在进行异常检查时消耗的系统资源,要比普通的程序调用高。那么,如果我们的程序在不停地进行异常检查,就会对程序整个的性能产生不小的影响。我们可以从一个小例子中看出这一点。如下:
假设现有10000000个元素的List,我们要对此List进行遍历,有三种方式,分别如下:
第一种:对每一种情况进行异常检查
- private void call_1(List<Integer> list) {
- long t = System.currentTimeMillis();
- try {
- int index = 0;
- while(true) {
- list.get(index++);
- }
- } catch (IndexOutOfBoundsException e) {
- LogUtils.printTimeUsed("不针对检查异常", t);
- }
- }
第二种:只对错误的情况进行异常检查
- private void call_2(List<Integer> list) {
- long t = System.currentTimeMillis();
- t = System.currentTimeMillis();
- int size = list.size();
- int index = 0;
- while(true) {
- if (index >= size) {
- try {
- list.get(index++);
- } catch (IndexOutOfBoundsException e) {
- LogUtils.printTimeUsed("针对性检查异常", t);
- break;
- }
- }
- list.get(index++);
- }
- }
第三种:普通的循环遍历
- private void call_3(List<Integer> list) {
- long t = System.currentTimeMillis();
- t = System.currentTimeMillis();
- int size = list.size();
- int index = 0;
- for (index = 0; index < size; index++) {
- list.get(index++);
- }
- LogUtils.printTimeUsed("循环遍历", t);
- }
测试结果:
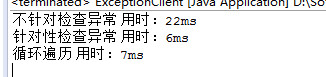
图-3 不同异常检查方式遍历List
从上面的测试结果中,我们可以看到不针对地检查异常(盲目地检查异常),比有针对性地检查异常性能上低了不少。所以,我们在使用异常的时候,请格外谨慎。需要去避免一些不必要的异常检查,以优化我们的程序代码
异常的一种经典应用:
api异常设计
大致有两种抛出的方法:
- 抛出带状态码RumtimeException异常
- 抛出指定类型的RuntimeException异常
这个是在设计service层异常时提到的,通过对service层的介绍,我们在service层抛出异常时选择了第二种抛出的方式,不同的是,在api层抛出异常我们需要使用这两种方式进行抛出:要指定api异常的类型,并且要指定相关的状态码,然后才将异常抛出,这种异常设计的核心是让调用api的使用者更能清楚的了解发生异常的详细信息,除了抛出异常外,我们还需要将状态码对应的异常详细信息以及异常有可能发生的问题制作成一个对应的表展示给用户,方便用户的查询。(如github提供的api文档,微信提供的api文档等),还有一个好处:如果用户需要自定义提示消息,可以根据返回的状态码进行提示的修改。
api验证约束
首先对于api的设计来说,需要存在一个dto对象,这个对象负责和调用者进行数据的沟通和传递,然后dto->domain在传给service进行操作,这一点一定要注意,第二点,除了说道的service需要进行基础判断(null判断)和jsr 303验证以外,同样的,api层也需要进行相关的验证,如果验证不通过的话,直接返回给调用者,告知调用失败,不应该带着不合法的数据再进行对service的访问,那么读者可能会有些迷惑,不是service已经进行验证了,为什么api层还需要进行验证么?这里便设计到了一个概念:编程中的墨菲定律,如果api层的数据验证疏忽了,那么有可能不合法数据就带到了service层,进而讲脏数据保存到了数据库。
所以缜密编程的核心是:永远不要相信收到的数据是合法的。
api异常设计
设计api层异常时,正如我们上边所说的,需要提供错误码和错误信息,那么可以这样设计,提供一个通用的api超类异常,其他不同的api异常都继承自这个超类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 2 | public class ApiException extends RuntimeException {protected Long errorCode ;protected Object data ;public ApiException(Long errorCode,String message,Object data,Throwable e){ super(message,e); this.errorCode = errorCode ; this.data = data ;}public ApiException(Long errorCode,String message,Object data){ this(errorCode,message,data,null);}public ApiException(Long errorCode,String message){ this(errorCode,message,null,null);}public ApiException(String message,Throwable e){ this(null,message,null,e);}public ApiException(){}public ApiException(Throwable e){ super(e);}public Long getErrorCode() { return errorCode;}public void setErrorCode(Long errorCode) { this.errorCode = errorCode;}public Object getData() { return data;}public void setData(Object data) { this.data = data;}} |
然后分别定义api层异常:ApiDefaultAddressNotDeleteException,ApiNotFindAddressException,ApiNotFindUserException,ApiNotMatchUserAddressException。
以默认地址不能删除为例:
1 2 3 4 5 6 | public class ApiDefaultAddressNotDeleteException extends ApiException {public ApiDefaultAddressNotDeleteException(String message) { super(AddressErrorCode.DefaultAddressNotDeleteErrorCode, message, null);}} |
AddressErrorCode.DefaultAddressNotDeleteErrorCode就是需要提供给调用者的错误码。错误码类如下:
1 2 3 4 5 6 | public abstract class AddressErrorCode { public static final Long DefaultAddressNotDeleteErrorCode = 10001L;//默认地址不能删除 public static final Long NotFindAddressErrorCode = 10002L;//找不到此收货地址 public static final Long NotFindUserErrorCode = 10003L;//找不到此用户 public static final Long NotMatchUserAddressErrorCode = 10004L;//用户与收货地址不匹配} |
ok,那么api层的异常就已经设计完了,在此多说一句,AddressErrorCode错误码类存放了可能出现的错误码,更合理的做法是把他放到配置文件中进行管理。
api处理异常
api层会调用service层,然后来处理service中出现的所有异常,首先,需要保证一点,一定要让api层非常轻,基本上做成一个转发的功能就好(接口参数,传递给service参数,返回给调用者数据,这三个基本功能),然后就要在传递给service参数的那个方法调用上进行异常处理。
此处仅以添加地址为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | @Autowiredprivate IAddressService addressService;/** * 添加收货地址 * @param addressDTO * @return */@RequestMapping(method = RequestMethod.POST)public AddressDTO add(@Valid @RequestBody AddressDTO addressDTO){ Address address = new Address(); BeanUtils.copyProperties(addressDTO,address); Address result; try { result = addressService.createAddress(addressDTO.getUid(), address); }catch (NotFindUserException e){ throw new ApiNotFindUserException("找不到该用户"); }catch (Exception e){//未知错误 throw new ApiException(e); } AddressDTO resultDTO = new AddressDTO(); BeanUtils.copyProperties(result,resultDTO); resultDTO.setUid(result.getUser().getId()); return resultDTO;} |
这里的处理方案是调用service时,判断异常的类型,然后将任何service异常都转化成api异常,然后抛出api异常,这是常用的一种异常转化方式。相似删除收货地址和获取收货地址也类似这样处理,在此,不在赘述。
api异常转化
已经讲解了如何抛出异常和何如将service异常转化为api异常,那么转化成api异常直接抛出是否就完成了异常处理呢? 答案是否定的,当抛出api异常后,我们需要把api异常返回的数据(json or xml)让用户看懂,那么需要把api异常转化成dto对象(ErrorDTO),看如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | @ControllerAdvice(annotations = RestController.class)class ApiExceptionHandlerAdvice {/** * Handle exceptions thrown by handlers. */@ExceptionHandler(value = Exception.class)@ResponseBodypublic ResponseEntity<ErrorDTO> exception(Exception exception,HttpServletResponse response) { ErrorDTO errorDTO = new ErrorDTO(); if(exception instanceof ApiException){//api异常 ApiException apiException = (ApiException)exception; errorDTO.setErrorCode(apiException.getErrorCode()); }else{//未知异常 errorDTO.setErrorCode(0L); } errorDTO.setTip(exception.getMessage()); ResponseEntity<ErrorDTO> responseEntity = new ResponseEntity<>(errorDTO,HttpStatus.valueOf(response.getStatus())); return responseEntity;}@Setter@Getterclass ErrorDTO{ private Long errorCode; private String tip;}} |
ok,这样就完成了api异常转化成用户可以读懂的DTO对象了,代码中用到了@ControllerAdvice,这是spring MVC提供的一个特殊的切面处理。
当调用api接口发生异常时,用户也可以收到正常的数据格式了,比如当没有用户(uid为2)时,却为这个用户添加收货地址,postman(Google plugin 用于模拟http请求)之后的数据:
1 2 3 4 | { "errorCode": 10003, "tip": "找不到该用户"} |
api异常设计参考地址:http://www.importnew.com/28000.html
想要更多干货、技术猛料的孩子,快点拿起手机扫码关注我,我在这里等你哦~
