前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 程序员野客
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
实现过程
制作 Scrapy 爬虫需如下四步:
- 创建项目 :创建一个爬虫项目
- 明确目标 :明确你想要抓取的目标(编写 items.py)
- 制作爬虫 :制作爬虫开始爬取网页(编写 xxspider.py)
- 存储内容 :设计管道存储爬取内容(编写pipelines.py)
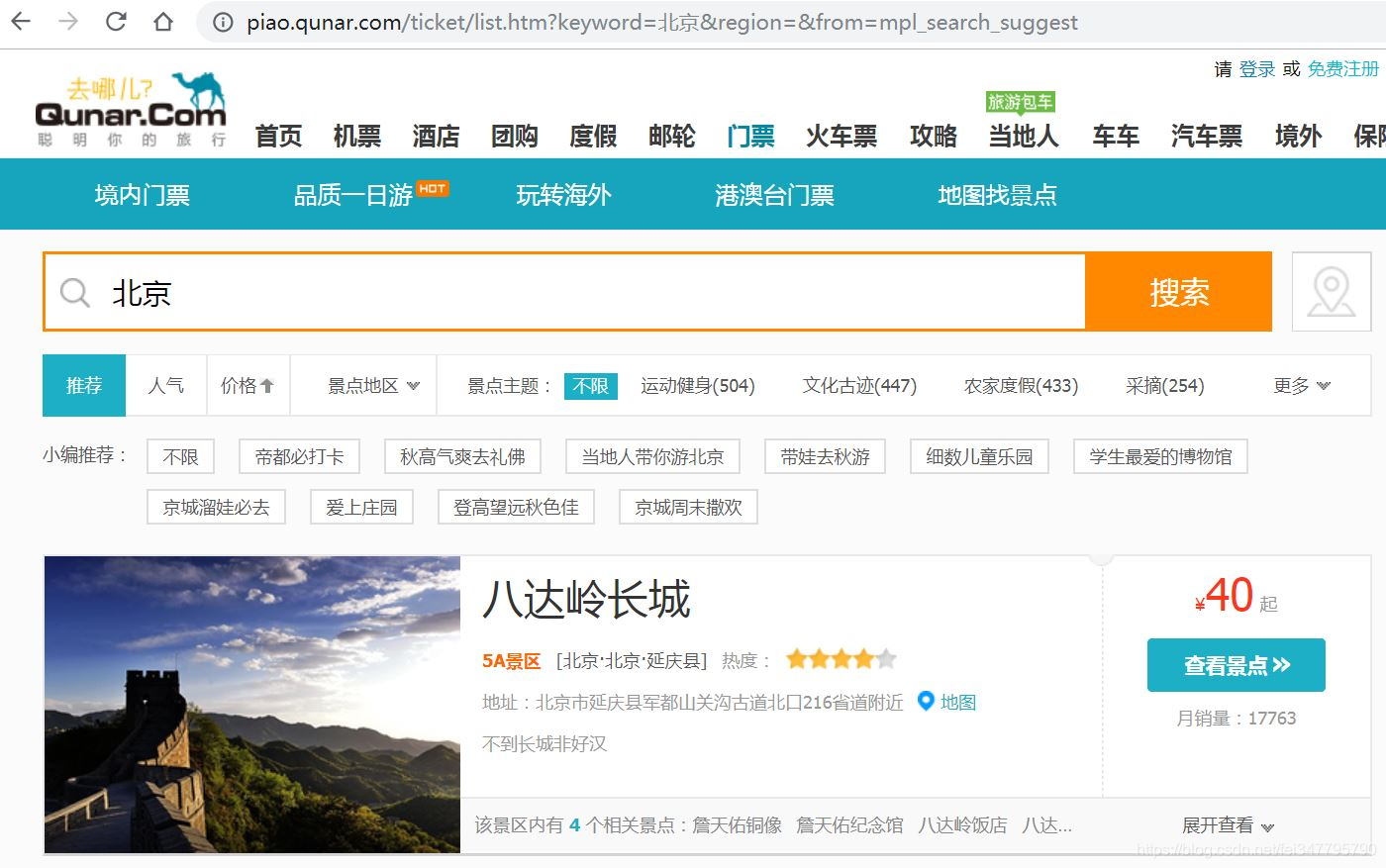
我们以爬取去哪儿网北京景区信息为例,如图所示:
创建项目
在我们需要新建项目的目录,使用终端命令 scrapy startproject 项目名 创建项目,我创建的目录结构如图所示:
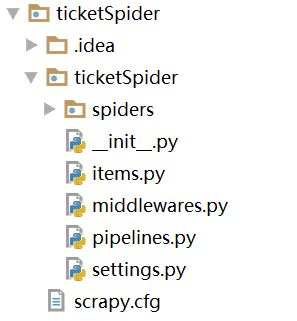
- spiders 存放爬虫的文件
- items.py 定义数据类型
- middleware.py 存放中间件
- piplines.py 存放数据的有关操作
- settings.py 配置文件
- scrapy.cfg 总的控制文件
定义 Item
Item 是保存爬取数据的容器,使用的方法和字典差不多。我们计划提取的信息包括:area(区域)、sight(景点)、level(等级)、price(价格),在 items.py 定义信息,源码如下:
import scrapy
class TicketspiderItem(scrapy.Item):
area = scrapy.Field()
sight = scrapy.Field()
level = scrapy.Field()
price = scrapy.Field()
pass
爬虫实现
在 spiders 目录下使用终端命令 scrapy genspider 文件名 要爬取的网址 创建爬虫文件,然后对其修改及编写爬取的具体实现,源码如下:
import scrapy
from ticketSpider.items import TicketspiderItem
class QunarSpider(scrapy.Spider):
name = 'qunar'
allowed_domains = ['piao.qunar.com']
start_urls = ['https://piao.qunar.com/ticket/list.htm?keyword=%E5%8C%97%E4%BA%AC®ion=&from=mpl_search_suggest']
def parse(self, response):
sight_items = response.css('#search-list .sight_item')
for sight_item in sight_items:
item = TicketspiderItem()
item['area'] = sight_item.css('::attr(data-districts)').extract_first()
item['sight'] = sight_item.css('::attr(data-sight-name)').extract_first()
item['level'] = sight_item.css('.level::text').extract_first()
item['price'] = sight_item.css('.sight_item_price em::text').extract_first()
yield item
# 翻页
next_url = response.css('.next::attr(href)').extract_first()
if next_url:
next_url = "https://piao.qunar.com" + next_url
yield scrapy.Request(
next_url,
callback=self.parse
)
简单介绍一下:
- name:爬虫名
- allowed_domains:允许爬取的域名
- atart_urls:爬取网站初始请求的 url(可定义多个)
- parse 方法:解析网页的方法
- response 参数:请求网页后返回的内容
yield
在上面的代码中我们看到有个 yield,简单说一下,yield 是一个关键字,作用和 return 差不多,差别在于 yield 返回的是一个生成器(在 Python 中,一边循环一边计算的机制,称为生成器),它的作用是:有利于减小服务器资源,在列表中所有数据存入内存,而生成器相当于一种方法而不是具体的信息,占用内存小。
爬虫伪装
通常需要对爬虫进行一些伪装
- 使用终端命令 pip install scrapy-fake-useragent 安装
- 在 settings.py 文件中添加如下代码:
DOWNLOADER_MIDDLEWARES = {
# 关闭默认方法
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 开启
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}
保存数据
我们将数据保存到本地的 csv 文件中,csv 具体操作可以参考:CSV 文件读写,下面看一下具体实现。
首先,在 pipelines.py 中编写实现,源码如下:
import csv
class TicketspiderPipeline(object):
def __init__(self):
self.f = open('ticker.csv', 'w', encoding='utf-8', newline='')
self.fieldnames = ['area', 'sight', 'level', 'price']
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
self.writer.writeheader()
def process_item(self, item, spider):
self.writer.writerow(item)
return item
def close(self, spider):
self.f.close()
然后,将 settings.py 文件中如下代码:
ITEM_PIPELINES = {
'ticketSpider.pipelines.TicketspiderPipeline': 300,
}
放开即可。
运行
我们在 settings.py 的同级目录下创建运行文件,名字自定义,放入如下代码:
from scrapy.cmdline import execute
execute('scrapy crawl 爬虫名'.split())
这个爬虫名就是我们之前在爬虫文件中的 name 属性值,最后在 Pycharm 运行该文件即可。