爬虫与浏览器对比
相同点
本质上都是通过 http/https 协议请求互联网数据
不同点
-
爬虫一般为自动化程序,无需用用户交互,而浏览器不是
-
运行场景不同;浏览器运行在客户端,而爬虫一般都跑在服务端
-
能力不同;浏览器包含渲染引擎、javascript 虚拟机,而爬虫一般都不具备这两者。
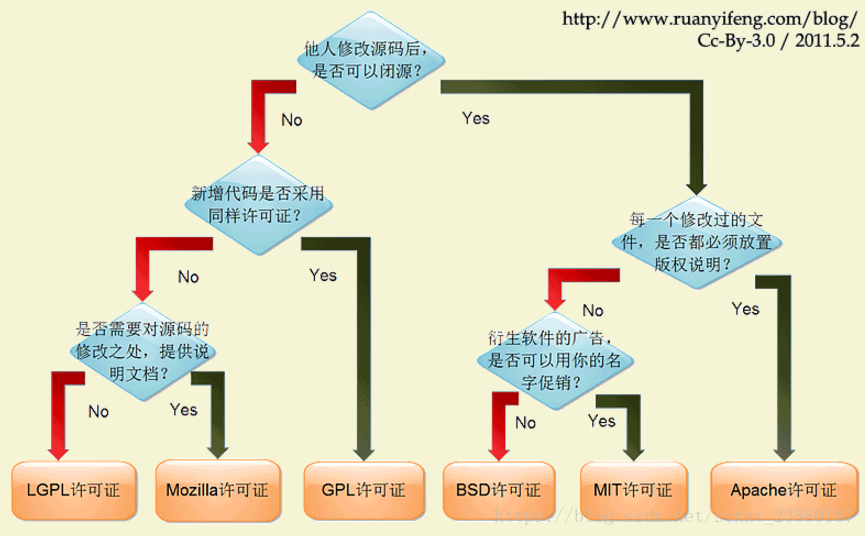
开源许可证
大概有上百种。很少有人搞得清楚它们的区别。即使在最流行的六种----GPL、BSD、MIT、Mozilla、Apache和LGPL
模块(Module)和包(Package)
在Python中,一个.py文件就称之为一个模块
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。(包由很多模块组成,包就是命名空间)
每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码
mycompany #包
├─ __init__.py
├─ abc.py #模块
└─ xyz.py
if __name__ == '__main__'详解
其中 if __name__ =='__main__': 确保服务器只会在该脚本被 Python 解释器直接执行的时候才会运行,而不是作为模块导入的时候。
其中__name__属性的意思:
1、__name__是一个变量。前后加了双下划线是因为是因为这是系统定义的名字。普通变量不要使用此方式命名变量。
2、__name__就是标识模块的名字的一个系统变量。这里分两种情况:假如当前模块是主模块(也就是调用其他模块的模块),那么此模块名字就是__main__,通过if判断这样就可以执行“__mian__:”后面的主函数内容;假如此模块是被import的,则此模块名字为文件名字(不加后面的.py),通过if判断这样就会跳过“__mian__:”后面的内容。
通过上面方式,python就可以分清楚哪些是主函数,进入主函数执行;并且可以调用其他模块的各个函数等等。
神级总结:
one.py
#coding=utf-8
# file one.py
# 在使用自身的时候,就是main,比如你执行:
# python one.py
# 此时在one.py里面的name就是main
# 如果你在two中import one,那么name就是文件名
'''
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
'''
def func():
print("func() in one.py")
print("top-level in one.py")
if __name__ == "__main__":
print("one.py is being run directly")
else: #其他导入会执行,类似测试吧
print("one.py is being imported into another module")two.py
#coding=utf-8
# file two.py
'''
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
'''
import one #导入就会自动执行,知道是当前的还是以前的
print("top-level in two.py")
one.func()
if __name__ == "__main__":
print("two.py is being run directly")
else:
print("two.py is being imported into another module")