思路
其实你在做完一些常规的反反爬措施之后基本能爬了,这里我关于IP我讲一下:
我主要是爬完一个职位之后睡眠1-3秒,随机选择
p=random.randint(1,3)
time.sleep(p)
其他也没有什么特别的了,我是牺牲了爬取的速度,反正是比较慢的,对多线程、多进程不是很熟,所以就没有用。
实战操作
实现:对智联招聘上搜索 数据分析 的职位相关信息的爬取,如职位名称、薪资、工作经验等等。具体看如下图:
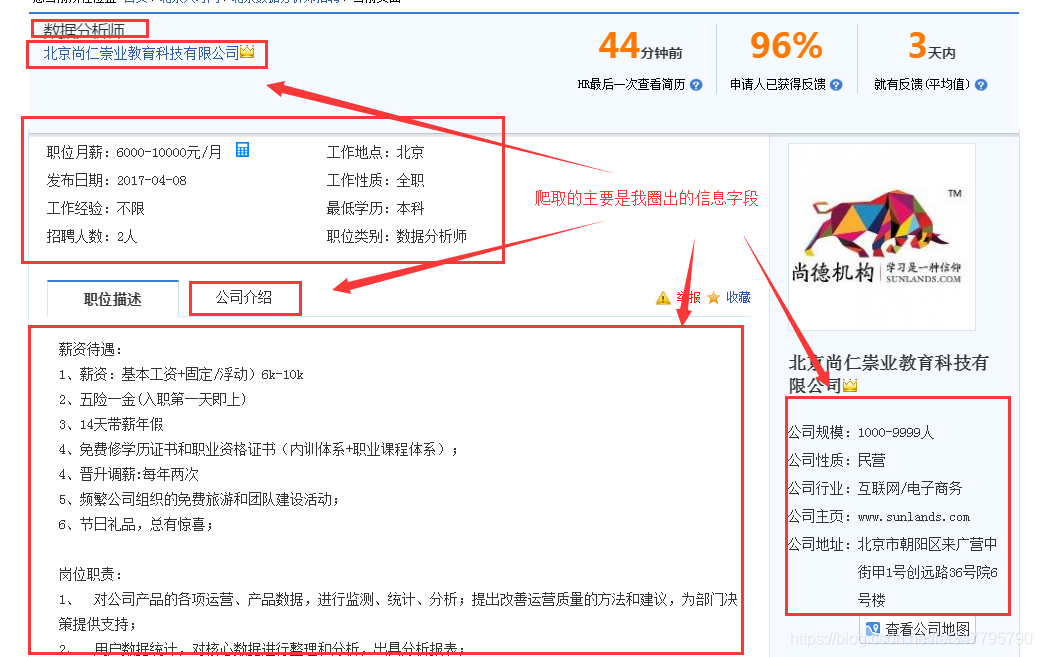
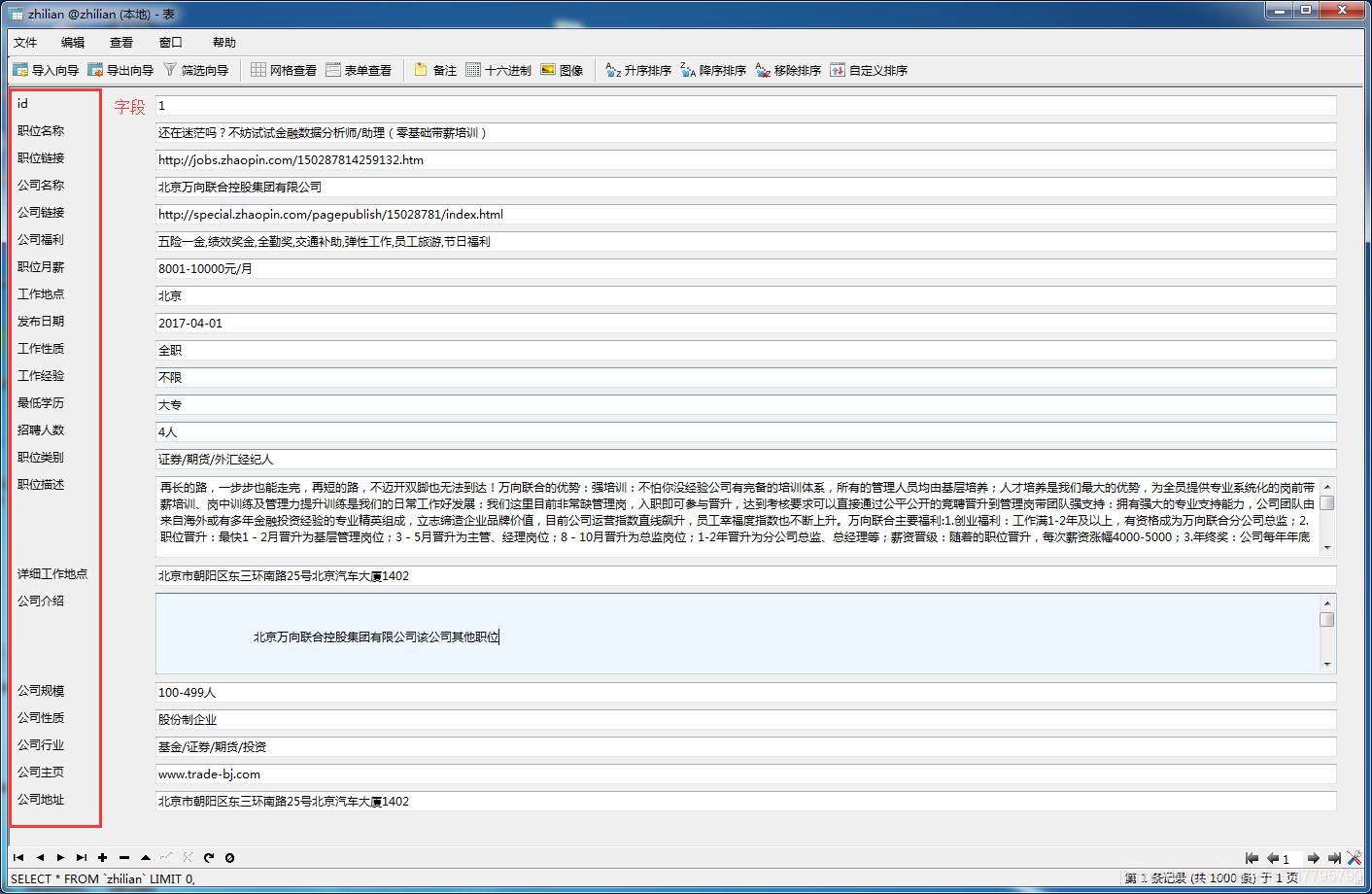
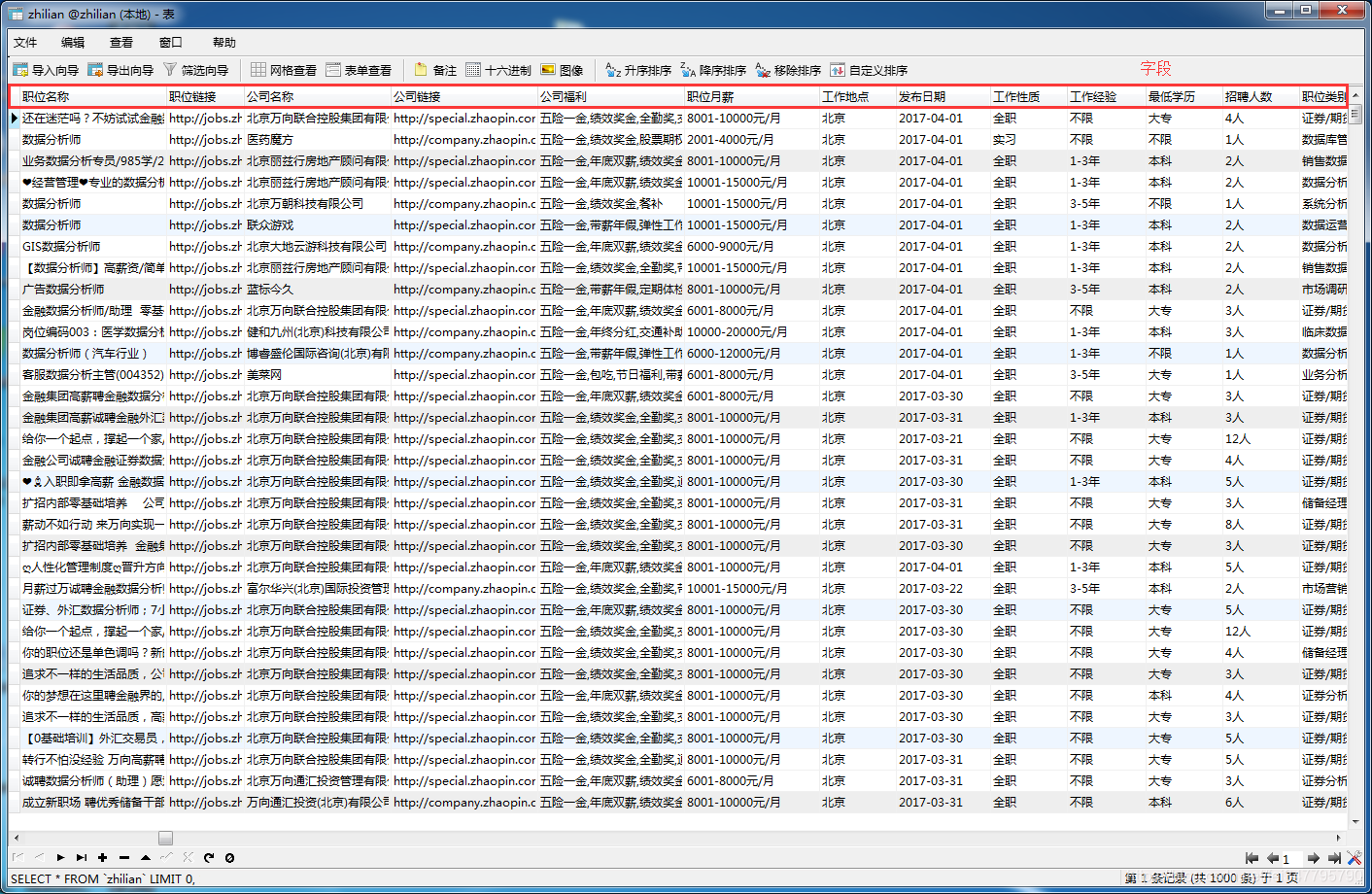
二、运行
先设置好place_name.py文件中 place_name 和 job_name,你要爬取的城市名称和职位名称。
zhilian.py中配置好数据库信息的函数。
最后运行zhilian.py文件即可。
places_name.py
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
def get_start_url():
'''
得到不同城市的起始链接
return:是包含不同城市的起始url
'''
# 先主要爬主要城市,看不同需求,也可以爬全国,只要把智联的候选地点全部抓取下来即可
place_name = ['北京','上海', '广州', '深圳', '天津', '武汉', '西安', '成都', '大连', '长春', '沈阳', '南京', '济南', '青岛',
'杭州', '苏州', '无锡', '宁波', '重庆', '郑州', '长沙', '福州', '厦门', '哈尔滨', '石家庄', '合肥', '惠州']
job_name = ['数据分析', 'php', '大数据', 'java', 'UI', 'IOS', '安卓', 'C++', 'python', '前端', '.net', '测试', '产品经理', '网络营销',
'嵌入式', '项目经理', 'VR', 'AR']
total_urls = []
for keyword in job_name:
list_urls = []
for i in place_name:
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=' + str(i) + '&kw=' + keyword
list_urls.append(url)
total_urls.append((keyword, list_urls))
return total_urls
zhilian.py
import re,requests,places_name
from lxml import etree
import pymysql,sys
import logging,time,random
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
urls=places_name.get_start_url()
'''保存日志方便查看'''
logging.basicConfig(filename='logging.log',
format='%(asctime)s %(message)s',
filemode="w", level=logging.DEBUG)
reload(sys)
sys.setdefaultencoding( "utf-8" )
header={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
a=1;count=1
def Connect():
'''链接本地数据库,数据库名为zhilian'''
host = "localhost"
dbName = "zhilian"
user = "root"
password = "root"
db = pymysql.connect(host, user, password, dbName, charset='utf8')
return db
cursorDB = db.cursor()
return cursorDB
def CreateTable():
'''创建数据表zhilian'''
db = Connect()
cur = db.cursor()
create_sql = "create table if not exists zhilian(id int(11) not null auto_increment,职位名称 varchar(255) default null,职位链接 varchar(255) default null,公司名称 varchar(255) default null,公司链接 varchar(255) defau" \
"lt null,公司福利 varchar(255) default null,职位月薪 varchar(255) default null,工作地点 varchar(255) default null,发布日期 varchar(255) defa" \
"ult null,工作性质 varchar(255) default null,工作经验 varchar(255) default null,最低学历 varchar(255) default null,招聘人数 varchar(255) default null,职位类别 varchar(255) default null,职位描述 TEXT,详细工作地点 varc" \
"har(255) default null,公司介绍 text,公司规模 varchar(255) default null,公司性质 varchar(255) default null,公司行业 varchar(255) defa" \
"ult null,公司主页 varchar(255) default null,公司地址 varchar(255) default null,关键词 varchar(255) default null,primary key(id)) ENGINE=MyISAM DEFAULT CHARSET=utf8"
cur.execute(create_sql)
db.commit()
db.close()
cur.close()
p_rint1='数据表创建成功'
print '数据表创建成功'
logging.info(p_rint1)
def get_content(job_url):
'''获取详细页面的信息'''
global a,count
p=random.randint(1,3)
time.sleep(p)
html=requests.get(job_url,headers=header,timeout=10)
response = etree.HTML(html.content)
link=job_url #职位链接
if u'jobs.zhaopin' in link:
for i in response.xpath('//div[@class="inner-left fl"]'):
job_name = i.xpath('h1/text()') # 职位名称
company_name = i.xpath('h2/a/text()') # 公司名称
company_link = i.xpath('h2/a/@href') # 公司链接
advantage = ','.join(i.xpath('div[1]/span/text()')) # 公司福利
for i in response.xpath('//ul[@class="terminal-ul clearfix"]'):
salary = i.xpath('li[1]/strong/text()') # 职位月薪
place = i.xpath('li[2]/strong/a/text()') # 工作地点
post_time = i.xpath('li[3]//span[@id="span4freshdate"]/text()') # 发布日期
job_nature = i.xpath('li[4]/strong/text()') # 工作性质
work_experience = i.xpath('li[5]/strong/text()') # 工作经验
education = i.xpath('li[6]/strong/text()') # 最低学历
job_number = i.xpath('li[7]/strong/text()') # 招聘人数
job_kind = i.xpath('li[8]/strong/a/text()') # 职位类别
html_body=html.content
reg = r'<!-- SWSStringCutStart -->(.*?)<!-- SWSStringCutEnd -->'
reg = re.compile(reg, re.S)
content = re.findall(reg, html_body)
try:
content = content[0].strip() # strip去空白
reg_1 = re.compile(r'<[^>]+>') # 去除html标签
content = reg_1.sub('', content).replace(' ', '')
job_content= content # 职位描述
except Exception,e:
job_content=''
for i in response.xpath('//div[@class="tab-inner-cont"]')[0:1]:
job_place = i.xpath('h2/text()')[0].strip() #工作地点(具体)
for i in response.xpath('//div[@class="tab-inner-cont"]')[1:2]:
reg = re.compile(r'<[^>]+>')
company_content = reg.sub('',i.xpath('string(.)')).replace(' ', '') # 公司的介绍
company_info = company_content
for i in response.xpath('//ul[@class="terminal-ul clearfix terminal-company mt20"]'):
if u'公司主页' in i.xpath('string(.)'):
company_size = i.xpath('li[1]/strong/text()')
company_nature =i.xpath('li[2]/strong/text()')
company_industry = i.xpath('li[3]/strong/a/text()')
company_home_link = i.xpath('li[4]/strong/a/text()')
company_place = i.xpath('li[5]/strong/text()')
else:
company_size = i.xpath('li[1]/strong/text()')
company_nature = i.xpath('li[2]/strong/text()')
company_industry = i.xpath('li[3]/strong/a/text()')
company_home_link = [u'无公司主页']
company_place = i.xpath('li[4]/strong/text()')
if a==1:
'''第一次创建数据表'''
CreateTable()
a = 0
#插入数据
db = Connect()
cur = db.cursor()
item_list = [str(job_name[0]),
str(link),
str(company_name[0]),
str(company_link[0]),
str(advantage),
str(salary[0]),
str(place[0]),
str(post_time[0]),
str(job_nature[0]),
str(work_experience[0]),
str(education[0]),
str(job_number[0]),
str(job_kind[0]),
str(job_content),
str(job_place),
str(company_info),
str(company_size[0]),
str(company_nature[0]),
str(company_industry[0]),
str(company_home_link[0]),
str(company_place[0].strip()),
str(keyword)]
insert_sql = 'insert into zhilian(职位名称,职位链接,公司名称,公司链接,公司福利,职位月薪,工作地点,发布日期,工作性' \
'质,工作经验,最低学历,招聘人数,职位类别,职位描述,详细工作地点,公司介绍,公司规模,公司性质,公司行业,公司主页,公司地址,关键词)value(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
print '第' + str(count) + '个抓取成功', item_list
log='第' + str(count) + '个抓取成功 '+','.join(item_list[0:13])
logging.info(log)
count += 1
cur.execute(insert_sql, item_list)
db.commit()
db.close()
cur.close()
else:
p_rint2='出错,校招'
print '出错,校招'
logging.info(p_rint2)
def get_job_url(url):
'''得到每个职位的链接地址'''
html=requests.get(url,headers=header,timeout=10)
response=etree.HTML(html.content)
job_urls=response.xpath('//*[@id="newlist_list_content_table"]/table/tr[1]/td[1]/div/a/@href')
for job_url in job_urls:
'''遍历职位链接,准备抓取信息字段'''
try:
get_content(job_url)
except Exception,e:
p_rint3= e,'--------get_content'
print e,'--------get_content'
logging.info(p_rint3)
continue
def get_page(url):
'''得到每个区的页数'''
html = requests.get(url,headers=header,timeout=10)
html=html.content
reg = r'共<em>(.*?)</em>个职位满足条件'
reg = re.compile(reg)
job_count = int(re.findall(reg, html)[0])
job_count_page = job_count / 60 + 1
if job_count_page<=90:
p_rint4='一共' + str(job_count) + '个职位,' + str(job_count_page) + ' 页'
print '一共' + str(job_count) + '个职位,' + str(job_count_page) + ' 页'
logging.info(p_rint4)
for i in range(1, job_count_page + 1):
'''循环每个区的页数,准备抓取职位链接地址'''
page = url.replace('&p=1', '&p=' + str(i))
try:
get_job_url(page)
except Exception,e:
p_rint5=e,'--------get_job_url'
print e,'--------get_job_url'
logging.info(p_rint5)
continue
else:
p_rint6='一共' + str(job_count) + '个职位,' + str(job_count_page) + ' 页,只能爬取前90页内容'
print '一共' + str(job_count) + '个职位,' + str(job_count_page) + ' 页,只能爬取前90页内容'
logging.info(p_rint6)
for i in range(1, 91):
'''循环每个区的页数,准备抓取职位链接地址'''
page = url.replace('&p=1', '&p=' + str(i))
try:
get_job_url(page)
except Exception,e:
p_rint7=e,'--------get_job_url'
print e,'--------get_job_url'
logging.info(p_rint7)
continue
global keyword
for tp in urls:
keyword = tp[0]
start_urls = tp[1]
for start_url in start_urls:
'''循环各城市url'''
html=requests.get(start_url,headers=header,timeout=10)
response=etree.HTML(html.content)
for i in response.xpath('/html/body/div[3]/div[3]/div[1]/div[3]/div[1]/div[2]'):
'''循环各城市的区url'''
area_url = i.xpath('a/@href')[1:]
area_url = ['http://sou.zhaopin.com' + i for i in area_url]
p_rint8=area_url
print area_url
logging.info(p_rint8)
for i in area_url:
'''遍历城市的取url,准备抓取页数总数'''
try:
get_page(i)
except Exception,e:
p_rint9=e,'--------get_page'
print e,'--------get_page'
logging.info(p_rint9)
continue