前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
最近做了一个爬取千千音乐的demo,免去下载歌曲还要下载对应客户端的麻烦,刚开始接触爬虫,可能写的不太好,求别喷!话不多说,进入正题
1.获取主页信息(获取各个榜单的url)
这里想要说的就是关于千千音乐的登录问题,可能是我在浏览器其他地方登录了百度账号,导致点击退出之后它就会自动又登录上,本来想通过代码登录获取cookie等登录信息的,我也懒得清除缓存了,
索性直接从抓包工具中把请求头全部复制过来,稍微修改一下
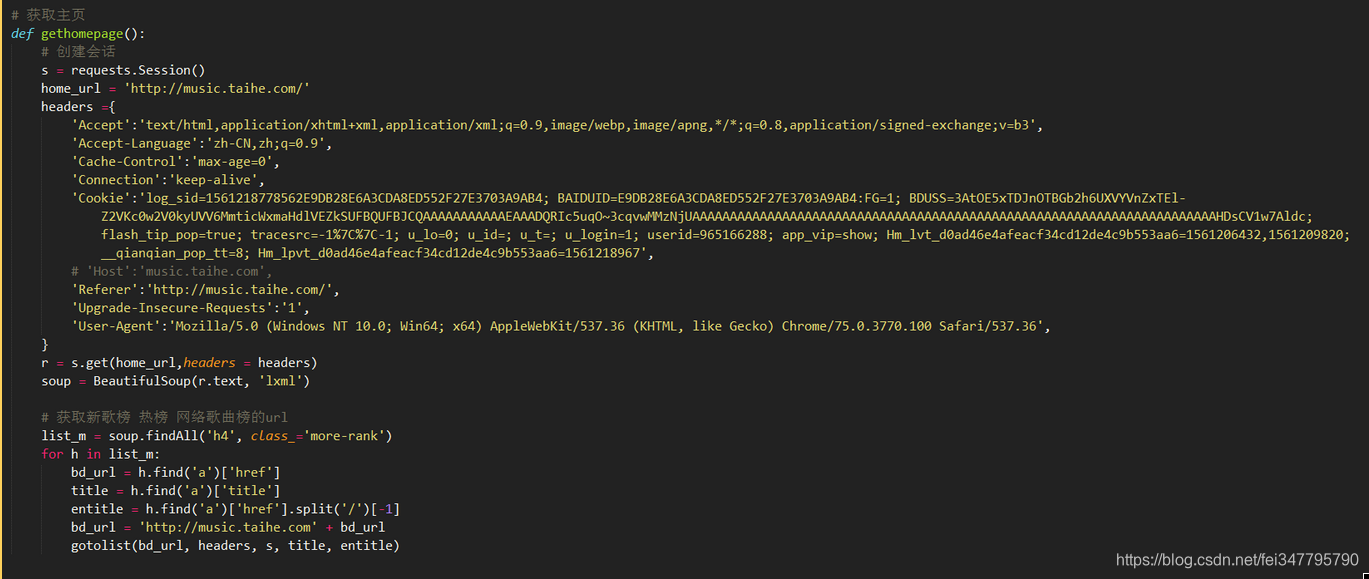
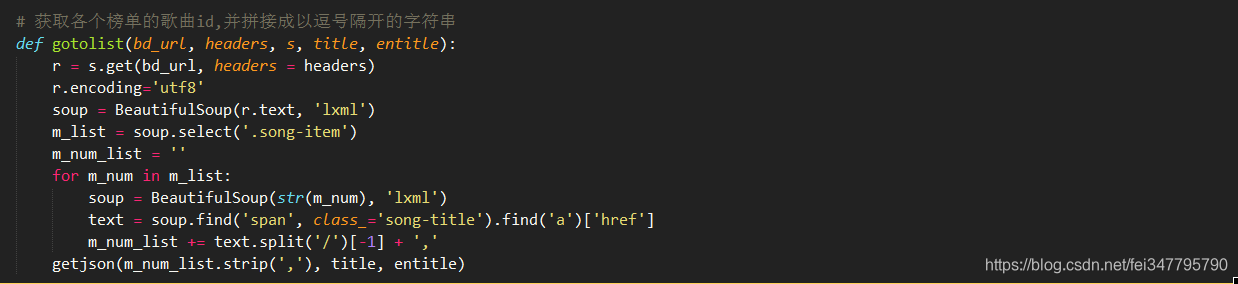
2.获取每个榜单中的每首歌曲的id
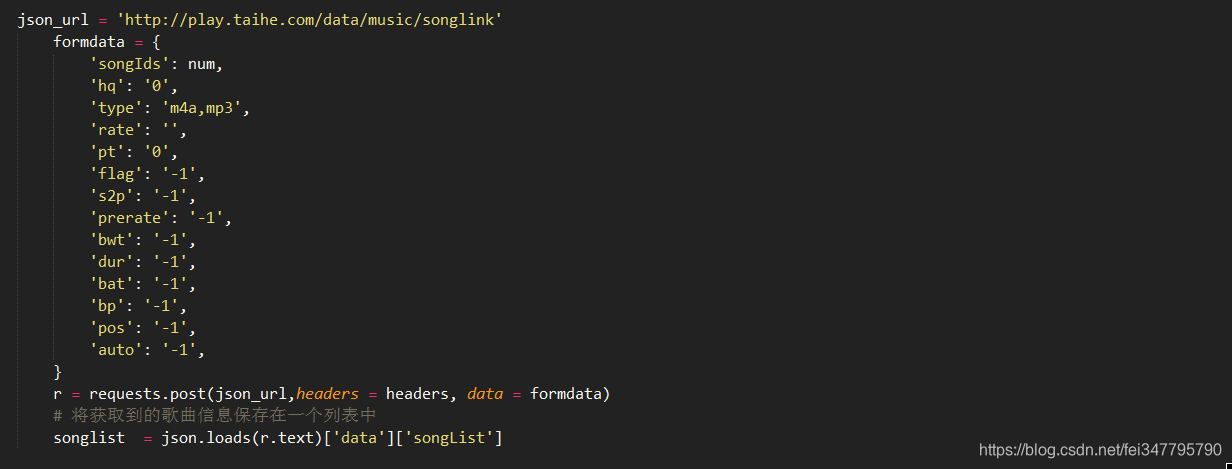
3.根据歌曲id获取每首歌曲的基本信息
4.遍历并下载歌曲
r = requests.get(music_url, timeout = 500)这行代码中的
timeout = 500得加上,数字可以按情况填写,因为我下载的时候如果不加这个参数下载到中途就会被服务器关闭连接,从而报错
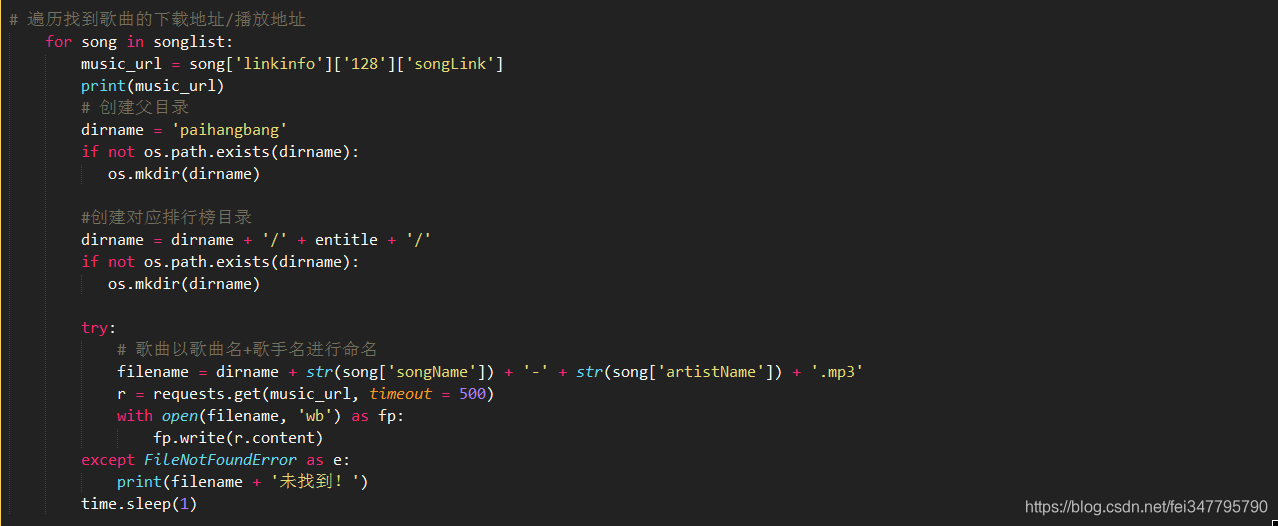
以上就是全部的代码,下载成功后的目录使这样的